
Java HashMap原始碼分析(含散列表、紅黑樹、擾動函式等重點問題分析)
阿新 • • 發佈:2021-02-21
# 寫在最前面
這個專案是從20年末就立好的 flag,經過幾年的學習,回過頭再去看很多知識點又有新的理解。所以趁著找實習的準備,結合以前的學習儲備,建立一個主要針對應屆生和初學者的 Java 開源知識專案,專注 Java 後端面試題 + 解析 + 重點知識詳解 + 精選文章的開源專案,希望它能伴隨你我一直進步!
說明:此專案內容參考了諸多博主(已註明出處),資料,N本書籍,以及結合自己理解,重新繪圖,重新組織語言等等所制。個人之力綿薄,或有不足之處,在所難免,但更新/完善會一直進行。大家的每一個 Star 都是對我的鼓勵 !希望大家能喜歡。
注:所有涉及圖片未使用網路圖床,文章等均開源提供給大家。
**專案名: Java-Ideal-Interview**
Github 地址: [Java-Ideal-Interview - Github ](https://github.com/ideal-20/Java-Ideal-Interview)
Gitee 地址:[Java-Ideal-Interview - Gitee(碼雲) ](https://gitee.com/ideal-20/java-ideal-interview)
持續更新中,線上閱讀將會在後期提供,若認為 Gitee 或 Github 閱讀不便,可克隆到本地配合 Typora 等編輯器舒適閱讀
若 Github 克隆速度過慢,可選擇使用國內 Gitee 倉庫
- [三 HashMap 原始碼分析](#三-hashmap-原始碼分析)
- [1. 前置知識](#1-前置知識)
- [1.1 什麼是 Map](#11-什麼是-map)
- [1.1.1 概述](#111-概述)
- [1.1.2 Map集合和Collection集合的區別](#112-map集合和collection集合的區別)
- [1.2 什麼是散列表](#12-什麼是散列表)
- [1.2.1 分析一下為什麼要用散列表](#121-分析一下為什麼要用散列表)
- [1.2.2 散列表工作原理](#122-散列表工作原理)
- [1.2.3 如何解決 Hash 衝突](#123-如何解決-hash-衝突)
- [1.2.3.1 JDK 1.7](#1231-jdk-17)
- [1.2.3.1 JDK 1.8](#1231-jdk-18)
- [1.3 什麼是紅黑樹](#13-什麼是紅黑樹)
- [2. 原始碼分析](#2-原始碼分析)
- [2.1 類成員](#21-類成員)
- [2.2 兩個節點](#22-兩個節點)
- [2.2.1 Node 節點](#221-node-節點)
- [2.2.2 TreeNode 節點](#222-treenode-節點)
- [2.3 構造方法](#23-構造方法)
- [2.4 新增方法](#24-新增方法)
- [2.4.1 put()](#241-put)
- [2.4.2 putVal()](#242-putval)
- [2.5 獲取方法](#25-獲取方法)
- [2.5.1 get()](#251-get)
- [2.5.2 getNode](#252-getnode)
- [2.6 移除方法](#26-移除方法)
- [2.6.1 remove()](#261-remove)
- [2.7 擴容方法](#27-擴容方法)
- [2.7.1 resize()](#271-resize)
- [3. 重點分析](#3-重點分析)
- [3.1 hash() 中的擾動函式如何解決Hash衝突 ※](#31-hash-中的擾動函式如何解決hash衝突)
# 三 HashMap 原始碼分析
## 1. 前置知識
### 1.1 什麼是 Map
> 在實際需求中,我們常常會遇到這樣的問題,在諸多的資料中,通過其編號來尋找某一些資訊,從而進行檢視或者修改,例如通過學號查詢學生資訊。今天我們所介紹的Map集合就可以很好的幫助我們實現這種需求
#### 1.1.1 概述
Map是一種儲存元素對的集合(元素對分別稱作 鍵 和 值 也稱鍵值對)它將鍵對映到值的物件。一個對映不能包含重複的鍵,並且每個鍵最 多隻能對映到一個值。
> 怎麼理解呢?
>
> 鍵 (key):就是你存的值的編號 值 (value):就是你要存放的資料
>
> 你可以近似的將鍵理解為下標,值依據鍵而儲存,每個鍵都有其對應值。這兩者是1、1對應的
>
> 但在之前下標是整數,但是Map中鍵可以使任意型別的物件。
#### 1.1.2 Map集合和Collection集合的區別
- Map集合儲存元素是成對出現的,Map集合的鍵是唯一的,值是可重複的
- Collection集合儲存元素是單獨出現的,Collection的子類Set是唯一的,List是可重複的。
- Map集合的資料結構值針對鍵有效,跟值無關,Collection集合的資料結構是針對元素有效
### 1.2 什麼是散列表
散列表也叫hash表 ,是根據關鍵碼值而進行直接進行訪問的資料結構。也就是說,它通過把關鍵碼值對映到表中一個位置來訪問記錄,以加快查詢的速度。這個對映也叫雜湊函式,存放記錄的陣列叫散列表。
> 一個通俗的例子是,為了查詢電話簿中某人的號碼,可以建立一個按照人名首字母順序排列的表(即建立人名到首字母的一個函式關係),在首字母為W的表中查詢“王”姓的電話號碼,顯然比直接查詢就要快得多。這裡使用人名作為關鍵字,“取首字母”是這個例子中雜湊函式的函式法則,存放首字母的表對應散列表。關鍵字和函式法則理論上可以任意確定。—— 維基百科
#### 1.2.1 分析一下為什麼要用散列表
雜湊表其實就是陣列的一種擴充套件,因為其本質上用的就是陣列可以**按照下標隨機訪問資料**的特點,我們來一步一步看一下
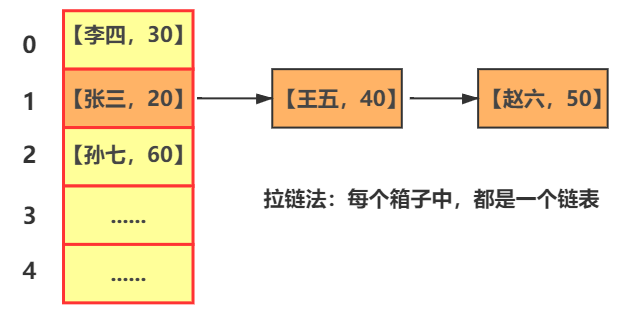
首先建立一個數組,我們將陣列的每一個儲存空間看做一個一個箱子或者一個一個桶,儲存一些 key-value 的資料如,【張三,20】【李四,30】【王五,40】【趙六,50】【孫七,60】,依次放置於陣列中。
如果按照普通順序表的查詢方式,就需要從開始依次比對查詢,但是資料量越多,順序表查詢耗費的時間就越長。在大量資料的情況下,很顯然不上算。
還有很多種資料結構,它們並不關心元素的順序,能夠快速的查詢元素資料,其中一種就是:散列表
下面看看散列表如何做到這麼高效處理的
#### 1.2.2 散列表工作原理
這次依舊使用 5 個箱子(桶)空間的陣列來儲存資料,我們開始存第一個資料【張三,20】,散列表會使用雜湊函式(Hash演算法)計算出 “張三” 的鍵,也就是字串 “張三” 的雜湊值,例如返回一個 5372 ,將其做取餘處理,除數為陣列的長度,即:5372 mod 5 = 2,因此將其放在下標(index)為 2 的位置,例如 第二個資料的雜湊值為 6386,繼續操作 6386 mod 5 = 1,即將其放在下標(index)為 1 的位置,以此類推.....
但是有一種情況就會出現了,例如我們儲存第三個資料【王五,40】的時候,經過雜湊函式計算,得出的結果為 5277,5277 mod 5 = 2 ,但是 2 這個位置已經有【張三,20】這個資料存在了,這種儲存位置重複了的情況便叫作衝突
#### 1.2.3 如何解決 Hash 衝突
##### 1.2.3.1 JDK 1.7
在 JDK 1.8 之前,HashMap 的底層是陣列和連結串列。因此當出現雜湊衝突後,使用**拉鍊法**解決衝突。
拉鍊法,就是將陣列的每一個格子(箱子),都看作一個連結串列,例如下標為 1 的格子,就是一個連結串列,已經儲存了 【張三,20】,若仍有資料雜湊值 mod 後等於 1 ,則直接在 1 中的這個連結串列中追加上這些資料就可以了。
##### 1.2.3.1 JDK 1.8
JDK 8 做了一些較大的調整,當陣列中每個格子裡的連結串列,長度大於閾值(預設為8)時,將連結串列轉化為紅黑樹,就可以大大的減少搜尋時間。
而且,如果散列表快滿的情況下下,還會有機制進行再雜湊,下面會在原始碼中深入分析。

### 1.3 什麼是紅黑樹
紅黑樹是一種複雜的樹形結構,這裡不做過於詳細的解釋,講一下其基本的結構,有一個基本的概念。對於理解,還可以參考掘金上的一篇文章([掘金-漫畫:什麼是紅黑樹?@程式設計師小灰](https://juejin.im/post/5a27c6946fb9a04509096248#comment))非常不錯!
紅黑樹就是為了防止二叉樹一些極端的情況,例如變成一條線狀,或者左右不均衡,從二叉查詢樹,2-3樹 等演變出來的一種樹形結構。最主要的目的就是為了保持平衡。保證樹的左右分支葉子等基本平衡。
具體的資料結果演變是比較複雜的,這一篇還是主要講解 HashMap ,有需要以後會專篇講解一些常見的資料結構的 Java 版本
## 2. 原始碼分析
### 2.1 類成員
```jaVa
// 序列化自動生成的一個碼,用來在正反序列化中驗證版本一致性。
private static final long serialVersionUID = 362498820763181265L;
// 預設的初始容量 1 * 2^4 = 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量 1 * 2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
// 預設的載入因子 0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 桶的樹化閾值,當桶(bucket)上的結點數大於這個值時會轉成紅黑樹,
// 也就是上面提到的長度大於閾值(預設為8)時,將連結串列轉化為紅黑樹
static final int TREEIFY_THRESHOLD = 8;
// 桶的連結串列還原閾值,當桶(bucket)上的結點數小於這個值時樹轉連結串列
// 一個道理
static final int UNTREEIFY_THRESHOLD = 6;
// 最小樹形化容量閾值,當雜湊表中的容量 > [] table;
// 存放具體元素的集
transient Set> entrySet;
// 存放元素的個數(不是陣列的長度)
transient int size;
// 擴容和修改的計數變數
transient int modCount;
// 臨界值 當實際大小(容量*填充因子)超過臨界值時,會進行擴容
int threshold;
// 載入因子
final float loadFactor;
```
其中有幾個需要強調的內容
**threshold 臨界值**
- 陣列擴容的一個臨界值,即當陣列實際大小(容量 * 填充因子,即:threshold = capacity * loadFactor)超過臨界值時,會進行擴容。
**loadFactor載入因子**
- 載入因子就是表示雜湊表中元素填滿的程度,當表中元素過多,超過載入因子的值時,雜湊表會自動擴容,一般是一倍,這種行為可以稱作rehashing(再雜湊)。
- 載入因子的值設定的越大,新增的元素就會越多,確實空間利用率的到了很大的提升,但是毫無疑問,就面臨著雜湊衝突的可能性增大,反之,空間利用率造成了浪費,但雜湊衝突也減少了,所以我們希望在空間利用率與雜湊衝突之間找到一種我們所能接受的平衡,經過一些試驗,定在了0.75f。
### 2.2 兩個節點
因為一定條件下會轉換成紅黑樹這種資料結果,所以除了普通的 Node 節點,還有 樹節點(TreeNode 節點)
#### 2.2.1 Node 節點
```java
static class Node implements Map.Entry {
// 雜湊碼,用來查詢位置以及比對元素是否相同
final int hash;
// 鍵
final K key;
// 值
V value;
// 指向下一個結點
Node next;
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
// 重寫了 hashCode, ^ 是位異或運算子
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 重寫 equals() 方法
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
```
#### 2.2.2 TreeNode 節點
```java
static final class TreeNode extends LinkedHashMap.Entry {
// 父節點
TreeNode parent;
// 左節點
TreeNode left;
// 右節點
TreeNode right;
TreeNode prev;
// 判斷顏色,預設紅色
boolean red;
TreeNode(int hash, K key, V val, Node next) {
super(hash, key, val, next);
}
// 返回根節點
final TreeNode root() {
for (TreeNode r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
```
### 2.3 構造方法
```java
// 指定了具體容量大小和載入因子的建構函式
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
// 指定了具體容量大小的建構函式
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 預設無參建構函式
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
// 指定了 map 的建構函式
public HashMap(Map m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
```
**tableSizeFor**
```java
/**
* 返回一個大於輸入引數,且最接近的,2的整數次冪的數
* 只是一個初始化內容,建立雜湊表時,會再重新賦值
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
```
**putMapEntries**
```java
final void putMapEntries(Map m, boolean evict) {
// 拿到給定 Map 的長度
int s = m.size();
if (s > 0) {
// 判斷當前實際儲存資料的這個 table 是否已經初始化
if (table == null) { // pre-size
// 沒初始化,就將 s 處理後設為m的實際元素個數
float ft = ((float)s / loadFactor) + 1.0F;
// 防止小於最小容量(閾值)
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 若大於臨界值,則初始化閾值
if (t > [] tab; Node p; int n, i;
// table未初始化(為null)或者長度為0,呼叫 resize 進行擴容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 若桶為空,即無發生碰撞
// (n - 1) & hash 用來確定元素存放在哪個位置,即哪個桶中
if ((p = tab[i = (n - 1) & hash]) == null)
// 新生成結點放入桶中(陣列中)
tab[i] = newNode(hash, key, value, null);
// 若桶中已經存在元素
else {
Node e; K k;
// 若節點 key 存在,就和要插入的key比較
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 如果key相同就直接覆蓋 value
e = p;
// hash值不相等,即key不相等,轉為紅黑樹結點
else if (p instanceof TreeNode)
// 插入到樹中
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
// 若是為連結串列結點
else {
// 遍歷找到尾節點插入
for (int binCount = 0; ; ++binCount) {
// 到達連結串列的尾部
if ((e = p.next) == null) {
// 在尾部插入新結點
p.next = newNode(hash, key, value, null);
// 結點數量達到閾值,轉化為紅黑樹
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出迴圈
break;
}
// 遍歷的過程中,遇到相同 key 則覆蓋 value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出迴圈
break;
// 用於遍歷桶中的連結串列,與前面的e = p.next組合,可以遍歷連結串列
p = e;
}
}
// 在桶中找到key值、hash值與插入元素相等的結點
if (e != null) {
// 記錄e的value
V oldValue = e.value;
// onlyIfAbsent 為 false 或者舊值為 null
if (!onlyIfAbsent || oldValue == null)
// 用新值替換舊值
e.value = value;
// 訪問後回撥
afterNodeAccess(e);
// 返回舊值
return oldValue;
}
}
// 結構性修改
++modCount;
// 超過最大容量,擴容
if (++size > threshold)
resize();
// 插入後回撥
afterNodeInsertion(evict);
return null;
}
```
**總結一下大致流程:**
- 先定位到具體的陣列位置,例如叫做 A
- 若 A 處沒有元素
- 就直接插入
- 若 A 處 有元素就和待插入的 key 比較
- 若 key 相同就直接覆蓋
- 若 key 不相同,就判斷 p 是否是一個樹節點
- 如果是就呼叫putTreeVal 方法將元素新增進入
- 如果不是就遍歷連結串列插入(尾插法)
### 2.5 獲取方法
#### 2.5.1 get()
同樣 get 方法中也用到了 hash 方法計算 key 的雜湊值,同樣跳轉到 3.1 可看,也可以看完最後去看也可以。
[3.1 hash() 中的擾動函式如何解決Hash衝突 ※](###3.1 hash() 中的擾動函式如何解決Hash衝突 ※)
```java
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
```
#### 2.5.2 getNode
```java
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
// 保證計算出來的雜湊值,確定是在雜湊表上的
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 要是直接在桶的首個位置上,直接就可以返回(這個桶中只有一個元素,或者在首個)
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一個節點
if ((e = first.next) != null) {
// 在樹中 get
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
// 在連結串列中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
```
### 2.6 移除方法
#### 2.6.1 remove()
同樣 get 方法中也用到了 hash 方法計算 key 的雜湊值,同樣跳轉到 3.1 可看,也可以看完最後去看也可以。
[3.1 hash() 中的擾動函式如何解決Hash衝突 ※](###3.1 hash() 中的擾動函式如何解決Hash衝突 ※)
```java
public V remove(Object key) {
Node e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
```
2.6.2 removeNode()
```java
final Node removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node[] tab; Node p; int n, index;
// 桶不為空,對映的雜湊值也存在
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node node = null, e; K k; V v;
// 如果在桶的首位就找到對應元素,記錄下來
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
// 若不在首位,就去紅黑樹或者連結串列中查詢了
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 找到了要刪除的節點和值,就分三種情況去刪除,連結串列,紅黑樹,桶的首位
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
```
### 2.7 擴容方法
#### 2.7.1 resize()
resize 在程式中是非常耗時的。要儘量避免用它。
- 其過程中會重新分配 hash ,然後遍歷hash表中所有的元素
```java
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超過最大值,不再擴容,沒辦法了
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 沒超過最大值,就擴充為原來的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > [] newTab = (Node[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 將舊的鍵值對移動到新的雜湊桶陣列中
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// / 無鏈條,也就是沒有下一個,只有自己
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 拆紅黑樹,先拆成兩個子連結串列,再分別按需轉成紅黑樹
((TreeNode)e).split(this, newTab, j, oldCap);
else {
// 拆連結串列,拆成兩個子連結串列並保持原有順序
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引 + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到新的雜湊桶中
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引 +oldCap 放到新的雜湊桶中
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
```
## 3. 重點分析
### 3.1 hash() 中的擾動函式如何解決Hash衝突 ※
看HashMap的put方法原始碼:
```java
//HashMap 原始碼節選-JDK8
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
```
而我們的值在返回前需要經過HashMap中的hash方法
接著定位到hash方法的原始碼:
```java
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
```
hash方法的返回結果中是一句三目運算子,鍵 (key) 為null即返回 0,存在則返回後一句的內容
```java
(h = key.hashCode()) ^ (h >>> 16)
```
JDK8中 HashMap——hash 方法中的這段程式碼叫做 “**擾動函式**”
我們來分析一下:
hashCode 是 Object 類中的一個方法,在子類中一般都會重寫,而根據我們之前自己給出的程式,暫以 Integer 型別為例,我們來看一下 Integer 中 hashCode 方法的原始碼:
```java
/**
* Returns a hash code for this {@code Integer}.
*
* @return a hash code value for this object, equal to the
* primitive {@code int} value represented by this
* {@code Integer} object.
*/
@Override
public int hashCode() {
return Integer.hashCode(value);
}
/**
* Returns a hash code for a {@code int} value; compatible with
* {@code Integer.hashCode()}.
*
* @param value the value to hash
* @since 1.8
*
* @return a hash code value for a {@code int} value.
*/
public static int hashCode(int value) {
return value;
}
```
Integer 中 hashCode 方法的返回值就是這個數本身
> 注:整數的值因為與整數本身一樣唯一,所以它是一個足夠好的雜湊
所以,下面的 A、B 兩個式子就是等價的
```java
//注:key為 hash(Object key)引數
A:(h = key.hashCode()) ^ (h >>> 16)
B:key ^ (key >>> 16)
```
分析到這一步,我們的式子只剩下位運算了,先不急著算什麼,我們先理清思路
HashSet因為底層使用**雜湊表(連結串列結合陣列)**實現,儲存時key通過一些運算後得出自己在陣列中所處的位置。
我們在hashCoe方法中返回到了一個等同於本身值的雜湊值,但是考慮到int型別資料的範圍:-2147483648~2147483647 ,著很顯然,這些雜湊值不能直接使用,因為記憶體是沒有辦法放得下,一個40億長度的陣列的。所以它使用了對陣列長度進行**取模運算**,得餘後再作為其陣列下標,**indexFor( )** ——JDK7中,就這樣出現了,在JDK8中 indexFor()就消失了,而全部使用下面的語句代替,原理是一樣的。
```java
//JDK8中
(tab.length - 1) & hash;
```
```java
//JDK7中
bucketIndex = indexFor(hash, table.length);
static int indexFor(int h, int length) {
return h & (length - 1);
}
```
> 提一句,為什麼取模運算時我們用 & 而不用 % 呢,因為位運算直接對記憶體資料進行操作,不需要轉成十進位制,因此處理速度非常快,這樣就導致位運算 & 效率要比取模運算 % 高很多。
看到這裡我們就知道了,儲存時key需要通過**hash方法**和**indexFor( )**運算,來確定自己的對應下標
(取模運算,應以JDK8為準,但為了稱呼方便,還是按照JDK7的叫法來說,下面的例子均為此,特此提前宣告)
但是先直接看與運算(&),好像又出現了一些問題,我們舉個例子:
HashMap中初始長度為16,length - 1 = 15;其二進位制表示為 00000000 00000000 00000000 00001111
而與運算計算方式為:遇0則0,我們隨便舉一個key值
```java
1111 1111 1010 0101 1111 0000 0011 1100
& 0000 0000 0000 0000 0000 0000 0000 1111
----------------------------------------------------
0000 0000 0000 0000 0000 0000 0000 1100
```
我們將這32位從中分開,左邊16位稱作高位,右邊16位稱作低位,可以看到經過&運算後 結果就是高位全部歸0,剩下了低位的最後四位。但是問題就來了,我們按照當前初始長度為預設的16,HashCode值為下圖兩個,可以看到,在不經過擾動計算時,只進行與(&)運算後 Index值均為 12 這也就導致了雜湊衝突

> 雜湊衝突的簡單理解:計劃把一個物件插入到散列表(雜湊表)中,但是發現這個位置已經被別的物件所佔據了
例子中,兩個不同的HashCode值卻經過運算後,得到了相同的值,也就代表,他們都需要被放在下標為2的位置
一般來說,如果資料分佈比較廣泛,而且儲存資料的陣列長度比較大,那麼雜湊衝突就會比較少,否則很高。
但是,如果像上例中只取最後幾位的時候,這可不是什麼好事,即使我的資料分佈很散亂,但是雜湊衝突仍然會很嚴重。
別忘了,我們的擾動函式還在前面擱著呢,這個時候它就要發揮強大的作用了,還是使用上面兩個發生了雜湊衝突的資料,這一次我們加入擾動函式再進行與(&)運算

> 補充 :>>> 按位右移補零操作符,左運算元的值按右運算元指定的為主右移,移動得到的空位以零填充
> ^ 位異或運算,相同則 0,不同則 1
可以看到,本發生了雜湊衝突的兩組資料,經過擾動函式處理後,數值變得不再一樣了,也就避免了衝突
其實在**擾動函式**中,將**資料右位移16位**,雜湊碼的**高位和低位混合**了起來,這也正解決了前面所講 高位歸0,計算只依賴低位最後幾位的情況, 這使得高位的一些特徵也**對低位產生了影響**,使得**低位的隨機性加強**,能更好的**避免