
ElasticSearch 聚合分析
阿新 • • 發佈:2021-02-24
> **公號:碼農充電站pro**
> **主頁:**
ES 中的[聚合分析](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations.html)(Aggregations)是對資料的統計分析功能,它的優點是**實時性較高**,相比於 Hadoop 速度更快。
### 1,聚合的分類
ES 中的聚合分析主要有以下 3 大類,每一類都提供了多種統計方法:
- [Metrics](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics.html):對文件欄位進行統計分析(數學運算),多數 **Metrics** 的輸出是單個值,部分 **Metrics** 的輸出是多個值。
- [Sum](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-sum-aggregation.html):求和
- [Max](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-max-aggregation.html):求最大值
- [Min](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-min-aggregation.html):求最小值
- [Avg](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-avg-aggregation.html):求平均值
- 等
- [Bucket](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-bucket.html):一些滿足特定條件的文件集合(對文件進行**分組**)。
- [Terms](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-bucket-terms-aggregation.html)
- [Range](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-bucket-range-aggregation.html)
- 等
- [Pipeline](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-pipeline.html):對其它的聚合結果進行**再聚合**。
- [Avg bucket](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-pipeline-avg-bucket-aggregation.html):求平均值
- [Max bucket](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-pipeline-max-bucket-aggregation.html):求最大值
- [Min bucket](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-pipeline-min-bucket-aggregation.html):求最小值
- [Sum bucket](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-pipeline-sum-bucket-aggregation.html):求和
- [Stats bucket](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-pipeline-stats-bucket-aggregation.html):綜合統計
- [Percentiles bucket](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-pipeline-percentiles-bucket-aggregation.html):百分位數統計
- [Cumulative sum](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-pipeline-cumulative-sum-aggregation.html):累計求和
- 等
一般使用聚合分析時,通常將 **size** 設定為 0,表示不需要返回查詢結果,只需要返回聚合結果。
一個示例:
```shell
# 多個 Metric 聚合,找到最低最高和平均工資
POST index_name/_search
{
"size": 0, # size 為 0
"aggs": {
"max_salary": { # 自定義聚合名稱
"max": { # 聚合型別
"field": "salary" # 聚合欄位
}
},
"min_salary": { # 自定義聚合名稱
"min": { # 聚合型別
"field": "salary" # 聚合欄位
}
},
"avg_salary": { # 自定義聚合名稱
"avg": { # 聚合型別
"field": "salary" # 聚合欄位
}
}
}
}
```
### 2,Metrics 聚合
Metrics 聚合可以分為單值分析和多值分析:
- 單值分析:分析結果是單個值
- max
- min
- avg
- sum
- [cardinality](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-cardinality-aggregation.html):類似 distinct count
- 注意 cardinality 對 keyword 型別資料和 text 型別資料的區別
- keyword 型別不會進行分詞處理,而 text 型別會進行分詞處理
- 等
- 多值分析:分析結果是多個值
- [stats](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-stats-aggregation.html)
- [extended stats](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-extendedstats-aggregation.html)
- [string stats](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-string-stats-aggregation.html)
- [percentiles](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-percentile-aggregation.html)
- [percentile ranks](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-percentile-rank-aggregation.html)
- [top hits](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-top-hits-aggregation.html):根據一定的規則排序,選 top N
- 等
#### 2.1,示例
示例,一個員工表定義:
```shell
DELETE /employees
PUT /employees/
{
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"gender" : {
"type" : "keyword"
},
"job" : {
"type" : "text",
"fields" : {
"keyword" : { # 子欄位名稱
"type" : "keyword", # 子欄位型別
"ignore_above" : 50
}
}
},
"name" : {
"type" : "keyword"
},
"salary" : {
"type" : "integer"
}
}
}
}
```
插入一些測試資料:
```shell
PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000}
{ "index" : { "_id" : "11" } }
{ "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 }
{ "index" : { "_id" : "12" } }
{ "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000}
{ "index" : { "_id" : "13" } }
{ "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 }
{ "index" : { "_id" : "14" } }
{ "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000}
{ "index" : { "_id" : "15" } }
{ "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 }
{ "index" : { "_id" : "16" } }
{ "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "17" } }
{ "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "18" } }
{ "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000}
{ "index" : { "_id" : "19" } }
{ "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000}
{ "index" : { "_id" : "20" } }
{ "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}
```
**min** 聚合分析:
```shell
# Metric 聚合,找到最低的工資
POST employees/_search
{
"size": 0,
"aggs": {
"min_salary": {
"min": { # 聚合型別,求最小值
"field":"salary"
}
}
}
}
# 返回結果
"hits": {
"total": {
"value": 20, # 一共統計了多少條資料
"relation": "eq"
},
"max_score": null,
"hits": [...] # 因為 size 為 0
},
"aggregations": {
"min_salary": { # 自定義的聚合名稱
"value": 9000,
}
}
```
**stats** 聚合分析:
```shell
# 輸出多值
POST employees/_search
{
"size": 0,
"aggs": {
"stats_salary": {
"stats": { # stats 聚合
"field":"salary"
}
}
}
}
# 返回多值結果
"aggregations": {
"stats_salary": { # 自定義的聚合名稱
"count": 20,
"min": 9000,
"max": 50000,
"avg": 24700,
"sum": 494000
}
}
```
#### 2.2,top_hits 示例
```shell
# 指定 size,不同崗位中,年紀最大的3個員工的資訊
POST employees/_search
{
"size": 0,
"aggs":{
"old_employee":{ # 聚合名稱
"top_hits":{ # top_hits 分桶
"size":3,
"sort":[ # 根據 age 倒序排序,選前 3 個
{"age":{"order":"desc"}}
]
}
}
}
}
```
### 3,Bucket 聚合
Bucket 聚合按照一定的規則,將文件分配到不同的**桶**中,達到分類的目的。
Bucket 聚合**支援巢狀**,也就是在桶裡再次分桶。
Bucket 聚合演算法:
- [Terms](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-bucket-terms-aggregation.html):根據關鍵字(字串)分桶。**text** 型別的欄位需要開啟 **fielddata** 配置。
- 注意 keyword 型別不會做分詞處理,text 型別會做分詞處理。
- 另外 **size 引數**可以控制**桶的數量**。
- [Range](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-bucket-range-aggregation.html):按照範圍進行分桶,主要針對**數字型別的資料**。
- [Date range](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-bucket-daterange-aggregation.html)
- [Histogram](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-bucket-histogram-aggregation.html):直方圖分桶,指定一個間隔值,來進行分桶。
- [Date histogram](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-bucket-datehistogram-aggregation.html)
- 等
#### 3.1,Terms 示例
示例:
```shell
# 對 keword 進行聚合
POST employees/_search
{
"size": 0, # size 為 0
"aggs": {
"jobs": { # 自定義聚合名稱
"terms": { # terms 聚合
"field":"job.keyword" # job 欄位的 keyword 子欄位
}
}
}
}
# 返回值結構示例
"aggregations": {
"genres": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [ # 很多桶,這是一個數組
{
"key": "electronic",
"doc_count": 6
},
{
"key": "rock",
"doc_count": 3
},
{
"key": "jazz",
"doc_count": 2
}
]
}
}
```
對 Text 欄位進行 terms 聚合查詢會出錯,示例:
```shell
# 對 Text 欄位進行 terms 聚合查詢
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job" # job 是 text 型別
}
}
}
}
# 對 Text 欄位開啟 fielddata,以支援 terms aggregation
PUT employees/_mapping
{
"properties" : {
"job":{
"type": "text",
"fielddata": true # 開啟 fielddata
}
}
}
```
#### 3.2,Terms 效能優化
當某個欄位的**寫入和 Terms 聚合**比較頻繁的時候,可用通過開啟 [eager_global_ordinals](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/tune-for-search-speed.html#_warm_up_global_ordinals) 配置來對 Terms 操作進行優化。
示例:
```shell
PUT index_name
{
"mappings": {
"properties": {
"foo": { # 欄位名稱
"type": "keyword",
"eager_global_ordinals": true # 開啟
}
}
}
}
```
#### 3.3,巢狀聚合示例
Bucket 聚合支援新增**子聚合**來進一步分析,子聚合可以是一個 **Metrics** 或者 **Bucket**。
示例 1:
```shell
# 指定 size,不同崗位中,年紀最大的3個員工的資訊
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": { # 先做了一個 terms 分桶
"field":"job.keyword"
},
"aggs":{ # 巢狀一個聚合,稱為子聚合,
"old_employee":{ # 聚合名稱
"top_hits":{ # top_hits 分桶
"size":3,
"sort":[ # 根據 age 倒序排序,選前 3 個
{"age":{"order":"desc"}}
]
}
}
}
}
}
}
```
示例 2 :
```shell
POST employees/_search
{
"size": 0,
"aggs": {
"Job_salary_stats": {
"terms": { # 先做了一個 terms 分桶
"field": "job.keyword"
},
"aggs": {
"salary": {
"stats": { # 子聚合是一個 stats
"field": "salary"
}
}
}
}
}
}
# 多次巢狀
POST employees/_search
{
"size": 0,
"aggs": { # 第 1 層
"Job_gender_stats": {
"terms": {
"field": "job.keyword" # 先根據崗位分桶
},
"aggs": { # 第 2 層
"gender_stats": {
"terms": {
"field": "gender" # 再根據性別分桶
},
"aggs": { # 第 3 層
"salary_stats": {
"stats": { # 最後根據工資統計 stats
"field": "salary"
}
}
}
}
}
}
}
}
```
#### 3.4,Range 示例
對員工的工資進行區間聚合:
```shell
# Salary Ranges 分桶,可以自己定義 key
POST employees/_search
{
"size": 0,
"aggs": {
"salary_range": { # 自定義聚合名稱
"range": { # range 聚合
"field":"salary", # 聚合的欄位
"ranges":[ # range 聚合規則/條件
{
"to":10000 # salary < 10000
},
{
"from":10000, # 10000 < salary < 20000
"to":20000
},
{ # 如果沒有定義 key,ES 會自動生成
"key":"可以使用 key 自定義名稱",
"from":20000 # salary > 20000
}
]
}
}
}
}
```
#### 3.5,Histogram 示例
示例,工資0到10萬,以 **5000一個區間**進行分桶:
```shell
# Salary Histogram
POST employees/_search
{
"size": 0,
"aggs": {
"salary_histrogram": { # 自定義聚合名稱
"histogram": { # histogram 聚合
"field":"salary", # 聚合的欄位
"interval":5000, # 區間值
"extended_bounds":{ # 範圍
"min":0,
"max":100000
}
}
}
}
}
```
### 4,Pipeline 聚合
Pipeline 聚合用於對其它聚合的結果進行再聚合。
根據 **Pipeline 聚合**與**原聚合**的位置區別,分為兩類:
- **Pipeline 聚合**與**原聚合**同級,稱為 **Sibling 聚合**
- `Max_bucket`,`Min_bucket`,`Avg_bucket`,`Sum_bucket`
- `Stats_bucket`,`Extended-Status_bucket`
- `Percentiles_bucket`
- **Pipeline 聚合**內嵌在**原聚合**之內,稱為 **Parent 聚合**
- `Derivative`:求導
- `Cumulative-sum`:累計求和
- `Moving-function`:滑動視窗
#### 4.1,Sibling 聚合示例
示例:
```shell
# 平均工資最低的工作型別
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": { # 自定義聚合名稱
"terms": {
"field": "job.keyword", # 先對崗位型別進行分桶
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary" # 再計算每種工資崗位的平價值
}
}
}
},
"min_salary_by_job":{ # 自定義聚合名稱
"min_bucket": { # pipeline 聚合
"buckets_path": "jobs>avg_salary"
} # 含義是:對 jobs 中的 avg_salary 進行一個 min_bucket 聚合
}
}
}
```
#### 4.2,Parent 聚合示例
示例:
```shell
# 示例 1
POST employees/_search
{
"size": 0,
"aggs": {
"age": { # 自定義聚合名稱
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": { # 自定義聚合名稱
"avg": {
"field": "salary"
}
}, # 自定義聚合名稱
"derivative_avg_salary":{ # 注意 derivative 聚合的位置,與 avg_salary 同級
"derivative": { # 而不是與 age 同級
"buckets_path": "avg_salary" # 注意這裡不再有箭頭 >
}
}
}
}
}
}
# 示例 2
POST employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"cumulative_salary":{
"cumulative_sum": { # 累計求和
"buckets_path": "avg_salary"
}
}
}
}
}
}
```
### 5,聚合的作用範圍
ES 聚合的預設作用範圍是 Query 的查詢結果,如果沒有寫 Query,那預設就是在索引的所有資料上做聚合。
比如:
```shell
POST employees/_search
{
"size": 0,
"query": { # 在 query 的結果之上做聚合
"range": {
"age": {"gte": 20}
}
},
"aggs": {
"jobs": {
"terms": {"field":"job.keyword"}
}
}
}
```
ES 支援通過以下方式來改變聚合的作用範圍:
- Query:ES 聚合的預設作用範圍。
- **一般設定 size 為 0**。
- 如果沒有寫 Query,那預設就是在索引的所有資料上做聚合。
- Filter:寫在某個聚合的內部,只控制某個聚合的作用範圍。
- **一般設定 size 為 0**。
- Post Filter:對聚合沒有影響,只是對聚合的結果進行再過濾。
- **不再設定 size 為 0**。
- **使用場景**:獲取聚合資訊,並獲取符合條件的文件。
- Global:會覆蓋掉 Query 的影響。
#### 5.1,Filter 示例
示例:
```shell
POST employees/_search
{
"size": 0,
"aggs": {
"older_person": { # 自定義聚合名稱
"filter":{ # 通過 filter 改變聚合的作用範圍
"range":{
"age":{"from":35}
}
}, # end older_person
"aggs":{ # 在 filter 的結果之上做聚合
"jobs":{ # 自定義聚合名稱
"terms": {"field":"job.keyword"}
}
}
}, # end older_person
"all_jobs": { # 又一個聚合,沒有 filter
"terms": {"field":"job.keyword"}
}
}
}
```
#### 5.2,Post Filter 示例
示例:
```shell
POST employees/_search
{
"aggs": {
"jobs": { # 自定義聚合名稱
"terms": {"field": "job.keyword"}
}
}, # end aggs
"post_filter": { # 一個 post_filter,對聚合的結果進行過濾
"match": {
"job.keyword": "Dev Manager"
}
}
}
```
#### 5.3,Global 示例
```shell
POST employees/_search
{
"size": 0,
"query": { # 一個 query
"range": {
"age": {"gte": 40}
}
},
"aggs": {
"jobs": { # 一個聚合
"terms": {"field":"job.keyword"}
},
"all":{ # 又一個聚合,名稱為 all
"global":{}, # 這裡的 global 會覆蓋掉上面的 query,使得聚合 all 的作用範圍不受 query 的影響
"aggs":{ # 子聚合
"salary_avg":{ # 自定義聚合名稱
"avg":{"field":"salary"}
}
}
}
}
}
```
### 6,聚合中的排序
#### 6.1,基於 count 的排序
聚合中的排序使用 **order** 欄位,預設按照 **_count** 和 **_key** 進行排序。
- `_count`:表示按照文件數排序,如果不指定 **_count**,預設按照**降序**進行排序。
- `_key`:表示關鍵字(字串值),如果文件數相同,再按照 **key** 進行排序。
示例 1:
```shell
# 使用 count 和 key
POST employees/_search
{
"size": 0,
"query": {
"range": {
"age": {"gte": 20}
}
},
"aggs": {
"jobs": { # 自定義聚合名稱
"terms": { # terms 聚合
"field":"job.keyword",
"order":[ # order 排序
{"_count":"asc"}, # 先安裝文件數排序
{"_key":"desc"} # 如果文件數相同,再按照 key 排序
]
}
}
}
}
```
#### 6.2,基於子聚合的排序
也可以基於子聚合排序。
示例 2:
```shell
# 先對工作種類進行分桶
# 再以工作種類的平均工資進行排序
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": { # 自定義聚合名稱
"terms": {
"field":"job.keyword",
"order":[ # 基於子聚合的排序
{"avg_salary":"desc"}
]
}, # end terms
"aggs": { # 子聚合
"avg_salary": { # 子聚合名稱
"avg": {"field":"salary"}
}
}
} # end jobs
}
}
```
如果子聚合是**多值輸出**,也可以基於 `子聚合名.屬性` 來進行排序,如下:
```shell
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword",
"order":[ # 基於子聚合的屬性排序
{"stats_salary.min":"desc"}
]
}, # end terms
"aggs": {
"stats_salary": { # 子聚合是多值輸出
"stats": {"field":"salary"}
}
}
} # end jobs
}
}
```
### 7,聚合分析的原理及精準度
下面介紹聚合分析的原理及精準度的問題。
#### 7.1,分散式系統的三個概念
分散式系統中有三個概念:
- 資料量
- 精準度
- 實時性
對於分散式系統(資料分佈在**不同的分片**上),這三個指標不能同時具備,**同時只能滿足其中的 2 個條件**:
- **Hadoop 離線計算**:可以同時滿足**大資料量和精準度**。
- **近似計算**:可以同時滿足**大資料量和實時性**。
- **有限資料計算**:可以同時滿足**精準度和實時性**。
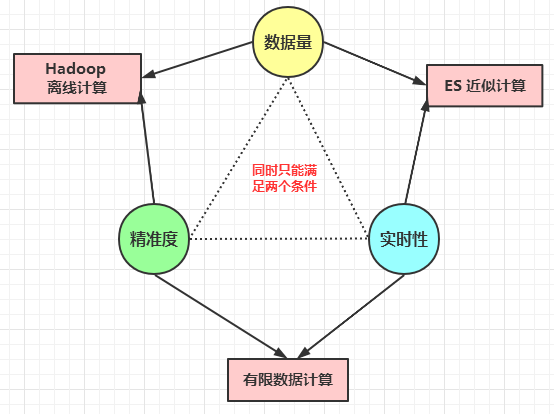
ES 屬於**近似計算**,具備了**資料量**和**實時性**的特點,失去了**精準度**。
#### 7.2,聚合分析的原理
ES 是一個分散式系統,資料分佈在不同的分片上。
因此,ES 在進行聚合分析時,會先在每個**主分片**上做聚合,然後再將每個主分片上的聚合結果進行**彙總**,從而得到最終的聚合結果。
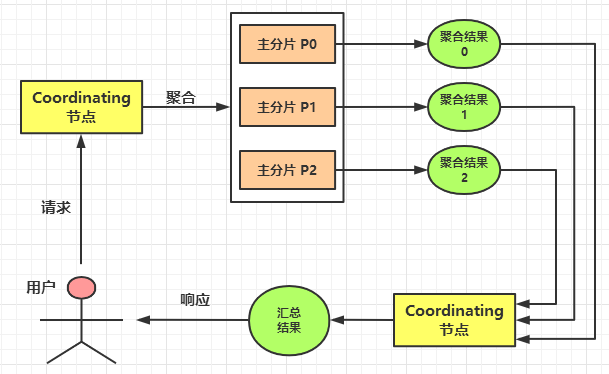
#### 7.3,聚合分析的精準度
分散式聚合的原理,會天生帶來精準度的問題,但並不是所有的聚合分析都有精準度問題:
- 比如 [Min 聚合](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics-min-aggregation.html) 就不會有精準度問題。
- 因為**求總的最小值**,與**先在所有主分片求最小值,再彙總每個主分片的最小值**,它們最終的結果是一樣的。
- 比如 [Terms 聚合](https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-bucket-terms-aggregation.html) 就有精準度問題。
下面來看下 **Terms** 聚合存在的問題,下圖中的:
- A(6) 表示 A 類的文件數有 6 個。
- B(4) 表示 B 類的文件數有 4 個。
- C(4) 表示 C 類的文件數有 4 個。
- D(3) 表示 D 類的文件數有 3 個。
下圖是 Terms 聚合流程:
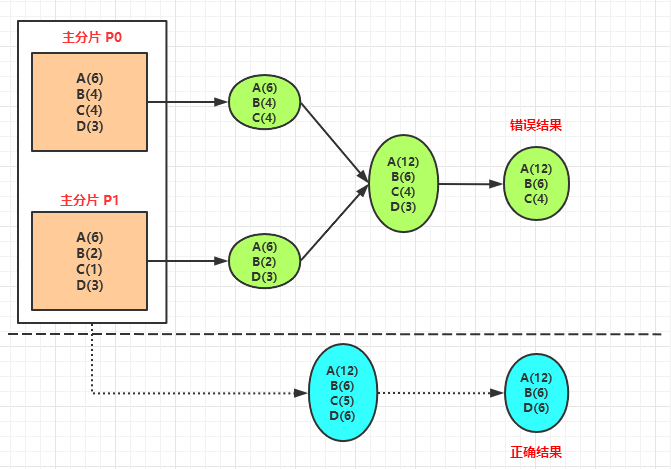
上圖中,在進行 Terms 聚合時(最終結果只要按照數量排序的前 3 個),需要分別在分片 **P0** 和 **P1**上做聚合,然後再將它們的聚合結果進行彙總。
正確的聚合結果應該是 `A(12),B(6),D(6)`,但是由於分片的原因,ES 計算出來的結果是 `A(12),B(6),C(4)`。這就是 **Terms** 聚合存在的精準度問題。
#### 7.4,show_term_doc_count_error 引數
開啟 [show_term_doc_count_error](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html#_per_bucket_document_count_error) 配置可以使得 terms 聚合的返回結果中有一個 `doc_count_error_upper_bound` 值(最小為0),通過該值可以瞭解精準程度;**該值越小,說明 Terms 的精準度越高**。
```shell
POST index_name/_search
{
"size": 0,
"aggs": {
"weather": { # 自定義聚合名稱
"terms": { # terms 聚合
"field":"OriginWeather",
"show_term_doc_count_error":true # 開啟
}
}
}
}
```
#### 7.5,如何提高 terms 精準度
提高 **terms** 聚合的精準度有兩種方式:
- 將主分片數設定為 1。
- 因為 terms 的不準確是由於分片導致的,如果將主分片數設定為 1,就不存在不準確的問題。
- 這種方式在資料量不是很大的時候,可以是使用。
- 將 [shard_size](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html#_shard_size_3) 的值儘量調大(意味著從分片上額外獲取更多的資料,從而提升準確度)。
- **shard_size** 值變大後,會使得計算量變大,進而使得ES 的**整體效能變低,精準度變高**。
- 所以需要權衡 **shard_size** 值與精準度的平衡。
- **shard_size** 值的預設值是 【[**size**](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html#search-aggregations-bucket-terms-aggregation-size) * **1.5 + 10**】。
設定 **shard_size** 的語法:
```shell
POST my_flights/_search
{
"size": 0,
"aggs": {
"weather": {
"terms": {
"field":"OriginWeather",
"size":1,
"shard_size":1,
"show_term_doc_count_error":true
}
}
}
}
```
(本節完。)
---
**推薦閱讀:**
[ElasticSearch 查詢](https://www.cnblogs.com/codeshell/p/14389415.html)
[ElasticSearch URI 查詢](https://www.cnblogs.com/codeshell/p/14429420.html)
[ElasticSearch DSL 查詢](https://www.cnblogs.com/codeshell/p/14435120.html)
[ElasticSearch 文件及操作](https://www.cnblogs.com/codeshell/p/14429409.html)
[ElasticSearch 搜尋模板與建議](https://www.cnblogs.com/codeshell/p/14435151.html)
---
*歡迎關注作者公眾號,獲取更多技術乾貨。*
![碼農充電站pro](https://img-blog.csdnimg.cn/20200505082843773.png?#pic_