
技術基礎 | 在Apache Cassandra中改變VNodes數量的影響
阿新 • • 發佈:2021-03-06
Apache Cassandra中num_tokens的預設值在4.0版本中將會有變化!這看起來好像只是在CHANGES.txt檔案中做了個小小的改動,但實際上這個改動將會對叢集的日常運維有著深遠的影響。
在這篇文章中,我們將會來仔細討論num_tokens值的改變將會如何影響叢集極其執行情況。
Apache Cassandra中有很多可以用於改變其行為的設定選項,num_tokens設定引數就是其中之一。像很多其他的設定引數一樣,num_tokens也是在cassandra.yaml檔案中,並且有一個預設值。不過它與其他設定引數相似的點也就到此為止了。 正如你所見,大多數Cassandra的設定引數只會對叢集的單一方面產生影響,但是num_tokens值的改變意味著一系列的叢集行為都將會被改變。 Apache Cassandra專案已經提交併解決了CASSANDRA-13701 JIRA問題,將num_tokens的預設值從256改為了16。這個改變具有重大意義,想要理解這個改變所帶來的的影響和結果,我們需要先理解num_tokens在叢集中所扮演的角色。
01 永遠不要在生產環境中嘗試的事 在我們進行深入探討之前,需要注意的是,一旦一個節點已經加入了叢集,num_tokens這個設定引數就不應該再有任何的改變。因為這樣會使得該節點在重啟時將發生故障。 一個數據中心中所有節點的num_tokens值應該是一樣的。從過去來說,異構的叢集是允許有不同的num_tokens值的。雖然這種情況很少見,我們也不推薦這麼做——但從理論上講,如果節點的硬體規格提升兩倍,你是可以將num_tokens的值加倍的。 另外,一個數據中心的節點的num_tokens值與另一個數據中心的節點的num_tokens值不同,這種情況是很常見的。這正是在保證零宕機時間的前提下,可以安全的改變一個正在執行的叢集的num_tokens值的部分原因。
02 基礎知識 num_tokens這一設定影響了Cassandra如何在節點間分配資料、如何從節點中取出資料,以及如何在節點間移動資料。 在後臺,Cassandra用分割槽演算法(partitioner)來決定資料儲存在叢集的何處。分割槽演算法是一個具有一致性的雜湊演算法,它可以將分割槽鍵(partition key,即主鍵的第一部分)一一對映到相應的令牌,而令牌則會決定與這些分割槽鍵相關的資料將會被儲存在哪些節點。 叢集中的每個節點都會被分配來自令牌環(token ring)中的一個或多個唯一的令牌值(雜湊值)——這是一種形象而巧妙的說法,其實每個節點被分配的是一段首尾相接的數字範圍中的一個數字。 也就是說,所謂的“被分配的數字”就是前面提到的令牌雜湊值,而所謂的“首尾相接的數字範圍”就是前面提到的雜湊環。之所以說令牌環(雜湊環)是環狀的,是因為它的最大值的下一個值是它的最小值。 被分配的令牌定義了節點在令牌環上所負責的令牌範圍,這個範圍通常被稱為“令牌區間(token range)”。 一個節點所負責的“令牌區間”的邊界是兩個值所定義的:一是該節點被分配的令牌值,二是在令牌環上自該令牌值向後推所得到的最小的可用雜湊值。被分配的令牌值是包括在節點的令牌區間內的,不過令牌環上最小的可用令牌值則不包括在內——該值通常為前一個相鄰節點佔用。 一個首尾相接的令牌環意味著節點所負責的令牌可能包括了該令牌環的最大令牌值和最小令牌值。至少曾出現過一次這樣的狀況——在令牌環上向後推所得到的最小可用令牌值越過了令牌環中首尾相接的點,即向後推的最小令牌值越過了令牌環的最大值。 舉例來說,在下面的令牌環分配圖中,我們有一個令牌值範圍為0-99的令牌環。令牌10被分配給了節點1。在叢集中,節點1前面的節點是節點5,它被分配的令牌是令牌90。這樣一來,節點1所負責的令牌值的範圍就是91到10了。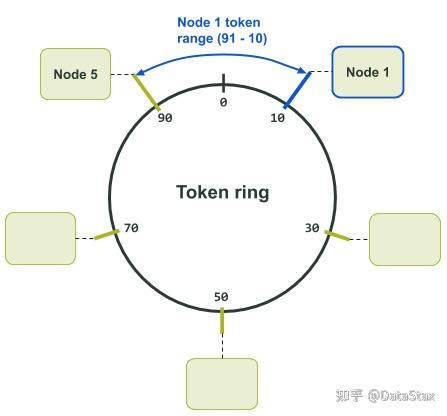
 之所以將分割槽演算法定義為一個具有一致性的雜湊演算法,其實是因為它本身就有這樣的特性——無論多少次地輸入某一特定的值,它總會生成並輸出同樣的值。
這種特性保證了所有的節點(node)、協調節點(coordinator)或是其他的任何元件在一個給定的分割槽鍵下,總能計算出同樣的值。而這個計算得到的令牌值則可被用於可靠地定位儲存著所需資料的節點。
結果就是,令牌環的最大最小值就由分割槽演算法來定義。舉例來說,預設使用的基於Murmur雜湊函式的Murur3Partitioner演算法的範圍是-2^63到+2^63 - 1;而以前曾使用的基於MD5雜湊函式的RandomPartitioner演算法的範圍則是0 to 2^127 - 1。
這樣的一個系統有一個嚴重的副作用,就是一旦一個叢集選定了一個分割槽演算法,那麼之後就不能再更改了。若想要更改分割槽演算法,則需先重新建立一個叢集,再選擇所想使用的分割槽演算法,然後再將資料匯入到新的叢集中。
之所以將分割槽演算法定義為一個具有一致性的雜湊演算法,其實是因為它本身就有這樣的特性——無論多少次地輸入某一特定的值,它總會生成並輸出同樣的值。
這種特性保證了所有的節點(node)、協調節點(coordinator)或是其他的任何元件在一個給定的分割槽鍵下,總能計算出同樣的值。而這個計算得到的令牌值則可被用於可靠地定位儲存著所需資料的節點。
結果就是,令牌環的最大最小值就由分割槽演算法來定義。舉例來說,預設使用的基於Murmur雜湊函式的Murur3Partitioner演算法的範圍是-2^63到+2^63 - 1;而以前曾使用的基於MD5雜湊函式的RandomPartitioner演算法的範圍則是0 to 2^127 - 1。
這樣的一個系統有一個嚴重的副作用,就是一旦一個叢集選定了一個分割槽演算法,那麼之後就不能再更改了。若想要更改分割槽演算法,則需先重新建立一個叢集,再選擇所想使用的分割槽演算法,然後再將資料匯入到新的叢集中。
03 早些時候…… 在Cassandra 1.2版本之前的時代,節點只能被手動分配單獨一個令牌。現在你依然可以通過cassandra.yaml檔案中的initial_token設定引數來實現同樣的效果。 那時候,預設使用的分割槽演算法是RandomPartitioner。在一個叢集從無到有的過程中,雖然令牌的分配過程是是手動的,但是RandomPartitioner分割槽演算法使得計算分配令牌的過程相當簡單直白。 舉例來說,如果你的叢集有3個節點,你需要做的就是用2^127 - 1除以3,這樣所得到的商就是相鄰的令牌所相差的正確增量。 你的第一個節點的起始令牌為0,即initial_token引數為0。接下來的節點的initial_token就會是(2^127 - 1) / 3,然後第三個節點的initial_token會是(2^127 - 1) / 3 * 2。這樣,每個節點的令牌範圍大小就會是一致的。 在各個節點的硬體配置完全一樣且資料在叢集中平均分佈的前提下,平均分配每個節點所負責的令牌範圍會使得節點過載的可能性較低。令牌分配的不均可能會導致所謂的“熱點問題(hot spot)”——即由於需要比別的節點處理更多請求或儲存更多資料,某個節點會處於較強的壓力之下。 儘管搭建一個單個節點對應單個令牌的叢集可能是一個非常手動的過程,但是它們的部署過程還是很常見,尤其是對於那些節點數通常超過1000的超大型Cassandra叢集來說。這種部署的優點之一就是可以保證令牌的分佈是均勻的。 雖然從頭搭建一個單個節點對應單個令牌的叢集可以保證負載的均勻分佈,想要擴大叢集可就沒有那麼容易了。如果你在擁有三個節點的叢集中再插入一個節點,結果就是四個節點當中的兩個節點的令牌範圍會小於另外兩個節點的令牌範圍。 想要修復這個問題並使得令牌分佈獲得再平衡,你就得執行nodetool move從而將令牌重新分配給其他節點。但是這個過程繁瑣且昂貴,因為其中牽涉了很多在整個叢集範圍內移動的資料流。一個替代方案是每次擴大叢集的時候,就將其擴大兩倍。不過這通常意味著需要使用比你實際需要的更多的硬體。 在一個單個節點對應單個令牌的叢集中保持令牌的均勻分佈就像是管理一個整潔無暇的後花園,你需要投入時間、養護以及注意力,或者要有大量的智慧自動化方案。 對於單個節點對應單個令牌的叢集來說,擴充套件性只是所有挑戰的一半。而挑戰的另一半,則是某些故障場景會極大地延長恢復所需要的時間。 讓我們來舉個例子,假設你在一個數據中心裡有一個擁有6個節點的叢集,叢集資料的副本數為3 (Replication Factor = 3)。這些副本可能會儲存在節點1和節點4,或節點2和節點5,或節點3和節點6。在這種情景下,每個節點負責3套副本中每套副本的六分之一。
04 vnodes前來救場 為了解決單個節點對應單個令牌這種分配方案的多個缺點,增強後的Cassandra 1.2版本允許一個節點可以被分配多個令牌,即一個節點可以負責多個令牌區間。Cassandra的這項特性被稱為“虛擬節點”,簡稱vnode。 vnode這項特性是在CASSANDRA-4119這個JIRA中被引入的,根據任務描述,vnode的目標是:
05 記得了解相關的限制條件 這個特性就像是我們擁有了個人開發助手——你交給他們一個節點,告訴他們將節點插入叢集,然後過一會兒他們就會將令牌分配好,並且節點也已經成了叢集的一部分。但是,塞翁得馬焉知非禍…… 雖然使用256個vnode時令牌分佈會更為均勻,但會出現可用性降低更快的問題——諷刺的是,我們越多地分拆令牌區間,我們的資料將越快面臨不可用的問題。而當vnode數量較少時,更容易會出現令牌區間不均的問題。 這裡所說的“數量較少”是指vnode的數量少於32個。當vnode數量較少時,Cassandra的隨機令牌分配機制就變得無能為力。其原因是面對生成的長度差異很大的令牌區間,系統沒有足夠的令牌用於平衡令牌的分配。
06 一圖勝千言 藉助用於測試的叢集,很容易能演示出上面提到的可用性和令牌區間分配不均的問題。我們可以用ccm搭建一個擁有6個節點的單個節點對應單個令牌的叢集。在計算了令牌分配,並配置啟動我們的測試集群后,會得到如下輸出結果。
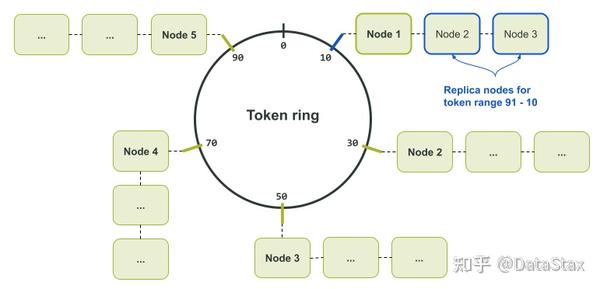
接著,我們可以捕獲ccm node1 nodetool describering test_keyspace的輸出結果,並且將令牌序號換成上面令牌環輸出結果中相應的字母。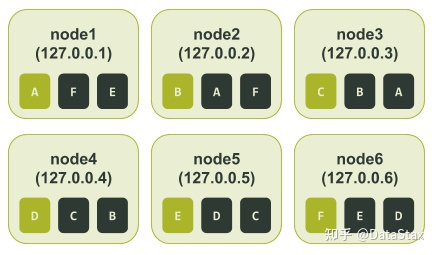 在這種配置下,如果節點3(node3)和節點6(node6)變為不可用狀態,我們將會丟失一整個資料副本。不過即使應用程式使用的一致性級別(consistency level)為LOCAL_QUORUM,所有的資料仍然可用,因為我們在剩下的四個節點中依然存有兩個資料副本。
現在,讓我們來考慮一下叢集使用vnode的情況。為了舉例,我們可以將num_tokens設為3,這樣比較小的令牌數會讓我們的例子更容易理解。在使用ccm配置並啟動多個節點後,我們的測試叢集的初始情況如下:
對於大多數叢集大小小於500個節點的生產部署,建議使用更大的num_tokens值。
在這種配置下,如果節點3(node3)和節點6(node6)變為不可用狀態,我們將會丟失一整個資料副本。不過即使應用程式使用的一致性級別(consistency level)為LOCAL_QUORUM,所有的資料仍然可用,因為我們在剩下的四個節點中依然存有兩個資料副本。
現在,讓我們來考慮一下叢集使用vnode的情況。為了舉例,我們可以將num_tokens設為3,這樣比較小的令牌數會讓我們的例子更容易理解。在使用ccm配置並啟動多個節點後,我們的測試叢集的初始情況如下:
對於大多數叢集大小小於500個節點的生產部署,建議使用更大的num_tokens值。
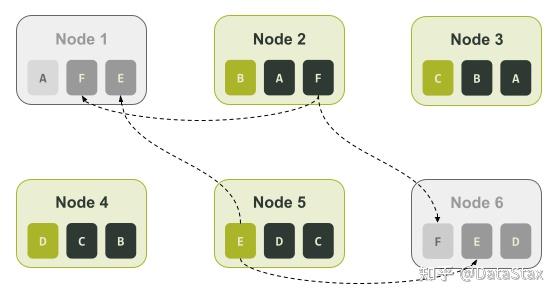
 根據上圖,我們可以看看如果發生像是前面提到的單個節點對應單個令牌的叢集所遇到的故障(即節點3和節點6處於不可用狀態),結果會如何。
上圖中我們可以看到節點3和節點6都負責令牌區間C、D、I、J、Q。所以如果我們的應用程式的一致性級別是LOCAL_QUORUM,那麼與這些令牌相關的資料都會處於不可用狀態。
換句話說,與單個節點對應單個令牌的叢集不同,在這種情況下,33.3%的資料可能再也無法被讀取了。
根據上圖,我們可以看看如果發生像是前面提到的單個節點對應單個令牌的叢集所遇到的故障(即節點3和節點6處於不可用狀態),結果會如何。
上圖中我們可以看到節點3和節點6都負責令牌區間C、D、I、J、Q。所以如果我們的應用程式的一致性級別是LOCAL_QUORUM,那麼與這些令牌相關的資料都會處於不可用狀態。
換句話說,與單個節點對應單個令牌的叢集不同,在這種情況下,33.3%的資料可能再也無法被讀取了。
07 上機架 經驗豐富的Cassandra使用者會注意到,到目前為止,我們只在一個單獨的機架(rack)上針對我們的叢集進行了令牌分配測試。在使用vnode時,我們可以通過部署更多的機架來提高可用性。 當使用多個機架時,Cassandra會試著在每個機架上都只存放一個單獨的資料副本——即Cassandra會試著確保在同一個機架上,不會出現兩個完全相同的令牌區間。 這裡的重點是要做好叢集的配置工作——對於一個給定的資料中心,其機架的數量應該與其複製因子(replication factor)相等。 讓我們再用一下前面num_tokens被設為3的例子,不過這次我們在測試叢集中會定義3個機架。在用ccm配置並啟動節點後,我們重新配置好的測試叢集的初始狀態如下:
Apache Cassandra中有很多可以用於改變其行為的設定選項,num_tokens設定引數就是其中之一。像很多其他的設定引數一樣,num_tokens也是在cassandra.yaml檔案中,並且有一個預設值。不過它與其他設定引數相似的點也就到此為止了。 正如你所見,大多數Cassandra的設定引數只會對叢集的單一方面產生影響,但是num_tokens值的改變意味著一系列的叢集行為都將會被改變。 Apache Cassandra專案已經提交併解決了CASSANDRA-13701 JIRA問題,將num_tokens的預設值從256改為了16。這個改變具有重大意義,想要理解這個改變所帶來的的影響和結果,我們需要先理解num_tokens在叢集中所扮演的角色。
01 永遠不要在生產環境中嘗試的事 在我們進行深入探討之前,需要注意的是,一旦一個節點已經加入了叢集,num_tokens這個設定引數就不應該再有任何的改變。因為這樣會使得該節點在重啟時將發生故障。 一個數據中心中所有節點的num_tokens值應該是一樣的。從過去來說,異構的叢集是允許有不同的num_tokens值的。雖然這種情況很少見,我們也不推薦這麼做——但從理論上講,如果節點的硬體規格提升兩倍,你是可以將num_tokens的值加倍的。 另外,一個數據中心的節點的num_tokens值與另一個數據中心的節點的num_tokens值不同,這種情況是很常見的。這正是在保證零宕機時間的前提下,可以安全的改變一個正在執行的叢集的num_tokens值的部分原因。
02 基礎知識 num_tokens這一設定影響了Cassandra如何在節點間分配資料、如何從節點中取出資料,以及如何在節點間移動資料。 在後臺,Cassandra用分割槽演算法(partitioner)來決定資料儲存在叢集的何處。分割槽演算法是一個具有一致性的雜湊演算法,它可以將分割槽鍵(partition key,即主鍵的第一部分)一一對映到相應的令牌,而令牌則會決定與這些分割槽鍵相關的資料將會被儲存在哪些節點。 叢集中的每個節點都會被分配來自令牌環(token ring)中的一個或多個唯一的令牌值(雜湊值)——這是一種形象而巧妙的說法,其實每個節點被分配的是一段首尾相接的數字範圍中的一個數字。 也就是說,所謂的“被分配的數字”就是前面提到的令牌雜湊值,而所謂的“首尾相接的數字範圍”就是前面提到的雜湊環。之所以說令牌環(雜湊環)是環狀的,是因為它的最大值的下一個值是它的最小值。 被分配的令牌定義了節點在令牌環上所負責的令牌範圍,這個範圍通常被稱為“令牌區間(token range)”。 一個節點所負責的“令牌區間”的邊界是兩個值所定義的:一是該節點被分配的令牌值,二是在令牌環上自該令牌值向後推所得到的最小的可用雜湊值。被分配的令牌值是包括在節點的令牌區間內的,不過令牌環上最小的可用令牌值則不包括在內——該值通常為前一個相鄰節點佔用。 一個首尾相接的令牌環意味著節點所負責的令牌可能包括了該令牌環的最大令牌值和最小令牌值。至少曾出現過一次這樣的狀況——在令牌環上向後推所得到的最小可用令牌值越過了令牌環中首尾相接的點,即向後推的最小令牌值越過了令牌環的最大值。 舉例來說,在下面的令牌環分配圖中,我們有一個令牌值範圍為0-99的令牌環。令牌10被分配給了節點1。在叢集中,節點1前面的節點是節點5,它被分配的令牌是令牌90。這樣一來,節點1所負責的令牌值的範圍就是91到10了。
之所以將分割槽演算法定義為一個具有一致性的雜湊演算法,其實是因為它本身就有這樣的特性——無論多少次地輸入某一特定的值,它總會生成並輸出同樣的值。
這種特性保證了所有的節點(node)、協調節點(coordinator)或是其他的任何元件在一個給定的分割槽鍵下,總能計算出同樣的值。而這個計算得到的令牌值則可被用於可靠地定位儲存著所需資料的節點。
結果就是,令牌環的最大最小值就由分割槽演算法來定義。舉例來說,預設使用的基於Murmur雜湊函式的Murur3Partitioner演算法的範圍是-2^63到+2^63 - 1;而以前曾使用的基於MD5雜湊函式的RandomPartitioner演算法的範圍則是0 to 2^127 - 1。
這樣的一個系統有一個嚴重的副作用,就是一旦一個叢集選定了一個分割槽演算法,那麼之後就不能再更改了。若想要更改分割槽演算法,則需先重新建立一個叢集,再選擇所想使用的分割槽演算法,然後再將資料匯入到新的叢集中。
03 早些時候…… 在Cassandra 1.2版本之前的時代,節點只能被手動分配單獨一個令牌。現在你依然可以通過cassandra.yaml檔案中的initial_token設定引數來實現同樣的效果。 那時候,預設使用的分割槽演算法是RandomPartitioner。在一個叢集從無到有的過程中,雖然令牌的分配過程是是手動的,但是RandomPartitioner分割槽演算法使得計算分配令牌的過程相當簡單直白。 舉例來說,如果你的叢集有3個節點,你需要做的就是用2^127 - 1除以3,這樣所得到的商就是相鄰的令牌所相差的正確增量。 你的第一個節點的起始令牌為0,即initial_token引數為0。接下來的節點的initial_token就會是(2^127 - 1) / 3,然後第三個節點的initial_token會是(2^127 - 1) / 3 * 2。這樣,每個節點的令牌範圍大小就會是一致的。 在各個節點的硬體配置完全一樣且資料在叢集中平均分佈的前提下,平均分配每個節點所負責的令牌範圍會使得節點過載的可能性較低。令牌分配的不均可能會導致所謂的“熱點問題(hot spot)”——即由於需要比別的節點處理更多請求或儲存更多資料,某個節點會處於較強的壓力之下。 儘管搭建一個單個節點對應單個令牌的叢集可能是一個非常手動的過程,但是它們的部署過程還是很常見,尤其是對於那些節點數通常超過1000的超大型Cassandra叢集來說。這種部署的優點之一就是可以保證令牌的分佈是均勻的。 雖然從頭搭建一個單個節點對應單個令牌的叢集可以保證負載的均勻分佈,想要擴大叢集可就沒有那麼容易了。如果你在擁有三個節點的叢集中再插入一個節點,結果就是四個節點當中的兩個節點的令牌範圍會小於另外兩個節點的令牌範圍。 想要修復這個問題並使得令牌分佈獲得再平衡,你就得執行nodetool move從而將令牌重新分配給其他節點。但是這個過程繁瑣且昂貴,因為其中牽涉了很多在整個叢集範圍內移動的資料流。一個替代方案是每次擴大叢集的時候,就將其擴大兩倍。不過這通常意味著需要使用比你實際需要的更多的硬體。 在一個單個節點對應單個令牌的叢集中保持令牌的均勻分佈就像是管理一個整潔無暇的後花園,你需要投入時間、養護以及注意力,或者要有大量的智慧自動化方案。 對於單個節點對應單個令牌的叢集來說,擴充套件性只是所有挑戰的一半。而挑戰的另一半,則是某些故障場景會極大地延長恢復所需要的時間。 讓我們來舉個例子,假設你在一個數據中心裡有一個擁有6個節點的叢集,叢集資料的副本數為3 (Replication Factor = 3)。這些副本可能會儲存在節點1和節點4,或節點2和節點5,或節點3和節點6。在這種情景下,每個節點負責3套副本中每套副本的六分之一。
04 vnodes前來救場 為了解決單個節點對應單個令牌這種分配方案的多個缺點,增強後的Cassandra 1.2版本允許一個節點可以被分配多個令牌,即一個節點可以負責多個令牌區間。Cassandra的這項特性被稱為“虛擬節點”,簡稱vnode。 vnode這項特性是在CASSANDRA-4119這個JIRA中被引入的,根據任務描述,vnode的目標是:
- 降低叢集伸縮的運維複雜性
- 縮短故障重建時間
- 故障發生時能夠平均分配負載
- 平均分配資料流操作帶來的影響
- 針對硬體異構性提供更可行的支援
05 記得了解相關的限制條件 這個特性就像是我們擁有了個人開發助手——你交給他們一個節點,告訴他們將節點插入叢集,然後過一會兒他們就會將令牌分配好,並且節點也已經成了叢集的一部分。但是,塞翁得馬焉知非禍…… 雖然使用256個vnode時令牌分佈會更為均勻,但會出現可用性降低更快的問題——諷刺的是,我們越多地分拆令牌區間,我們的資料將越快面臨不可用的問題。而當vnode數量較少時,更容易會出現令牌區間不均的問題。 這裡所說的“數量較少”是指vnode的數量少於32個。當vnode數量較少時,Cassandra的隨機令牌分配機制就變得無能為力。其原因是面對生成的長度差異很大的令牌區間,系統沒有足夠的令牌用於平衡令牌的分配。
06 一圖勝千言 藉助用於測試的叢集,很容易能演示出上面提到的可用性和令牌區間分配不均的問題。我們可以用ccm搭建一個擁有6個節點的單個節點對應單個令牌的叢集。在計算了令牌分配,並配置啟動我們的測試集群后,會得到如下輸出結果。
$ ccm node1 nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 127.0.0.1 71.17 KiB 1 33.3% 8d483ae7-e7fa-4c06-9c68-22e71b78e91f rack1 UN 127.0.0.2 65.99 KiB 1 33.3% cc15803b-2b93-40f7-825f-4e7bdda327f8 rack1 UN 127.0.0.3 85.3 KiB 1 33.3% d2dd4acb-b765-4b9e-a5ac-a49ec155f666 rack1 UN 127.0.0.4 104.58 KiB 1 33.3% ad11be76-b65a-486a-8b78-ccf911db4aeb rack1 UN 127.0.0.5 71.19 KiB 1 33.3% 76234ece-bf24-426a-8def-355239e8f17b rack1 UN 127.0.0.6 30.45 KiB 1 33.3% cca81c64-d3b9-47b8-ba03-46356133401b rack1接著,我們可以使用cqlsh建立一個測試鍵空間(keyspace),並向其中輸入資料。
$ ccm node1 cqlsh
Connected to SINGLETOKEN at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.9 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE test_keyspace WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 };
cqlsh> CREATE TABLE test_keyspace.test_table (
... id int,
... value text,
... PRIMARY KEY (id));
cqlsh> CONSISTENCY LOCAL_QUORUM;
Consistency level set to LOCAL_QUORUM.
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (1, 'foo');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (2, 'bar');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (3, 'net');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (4, 'moo');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (5, 'car');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (6, 'set');
想要確認該叢集是否已經完美地實現令牌的平均分配,我們可以檢視該叢集的令牌環。
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token
6148914691236517202
127.0.0.1 rack1 Up Normal 125.64 KiB 50.00% -9223372036854775808
127.0.0.2 rack1 Up Normal 125.31 KiB 50.00% -6148914691236517206
127.0.0.3 rack1 Up Normal 124.1 KiB 50.00% -3074457345618258604
127.0.0.4 rack1 Up Normal 104.01 KiB 50.00% -2
127.0.0.5 rack1 Up Normal 126.05 KiB 50.00% 3074457345618258600
127.0.0.6 rack1 Up Normal 120.76 KiB 50.00% 6148914691236517202
在“Owns”那列,我們可以看到所有的節點都擁有50%的資料。為了讓這個例子更容易理解,我們可以在每個令牌的右邊手動新增一個代表該令牌的字母。這樣一來,這些令牌區間就會被如下這樣表示:
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
6148914691236517202 F
127.0.0.1 rack1 Up Normal 125.64 KiB 50.00% -9223372036854775808 A
127.0.0.2 rack1 Up Normal 125.31 KiB 50.00% -6148914691236517206 B
127.0.0.3 rack1 Up Normal 124.1 KiB 50.00% -3074457345618258604 C
127.0.0.4 rack1 Up Normal 104.01 KiB 50.00% -2 D
127.0.0.5 rack1 Up Normal 126.05 KiB 50.00% 3074457345618258600 E
127.0.0.6 rack1 Up Normal 120.76 KiB 50.00% 6148914691236517202 F
接著,我們可以捕獲ccm node1 nodetool describering test_keyspace的輸出結果,並且將令牌序號換成上面令牌環輸出結果中相應的字母。
$ ccm node1 nodetool describering test_keyspace Schema Version:6256fe3f-a41e-34ac-ad76-82dba04d92c3 TokenRange: TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.4], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.3, 127.0.0.4, 127.0.0.5], rpc_endpoints:[127.0.0.3, 127.0.0.4, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.1], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:F, end_token:A, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
根據上面的輸出結果,特別是end_token這一列,我們就可以知道所有的節點被分配的令牌區間。就像前文“基礎知識”部分中提到的那樣,令牌區間是由前一個令牌(start_token)開始(不包括在內),直到本節點被分配的令牌(end_token)為止(包括在內)。 每個節點被分配的令牌區間如下圖所示:
在這種配置下,如果節點3(node3)和節點6(node6)變為不可用狀態,我們將會丟失一整個資料副本。不過即使應用程式使用的一致性級別(consistency level)為LOCAL_QUORUM,所有的資料仍然可用,因為我們在剩下的四個節點中依然存有兩個資料副本。
現在,讓我們來考慮一下叢集使用vnode的情況。為了舉例,我們可以將num_tokens設為3,這樣比較小的令牌數會讓我們的例子更容易理解。在使用ccm配置並啟動多個節點後,我們的測試叢集的初始情況如下:
對於大多數叢集大小小於500個節點的生產部署,建議使用更大的num_tokens值。
$ ccm node1 nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 127.0.0.1 71.21 KiB 3 46.2% 7d30cbd4-8356-4189-8c94-0abe8e4d4d73 rack1 UN 127.0.0.2 66.04 KiB 3 37.5% 16bb0b37-2260-440c-ae2a-08cbf9192f85 rack1 UN 127.0.0.3 90.48 KiB 3 28.9% dc8c9dfd-cf5b-470c-836d-8391941a5a7e rack1 UN 127.0.0.4 104.64 KiB 3 20.7% 3eecfe2f-65c4-4f41-bbe4-4236bcdf5bd2 rack1 UN 127.0.0.5 66.09 KiB 3 36.1% 4d5adf9f-fe0d-49a0-8ab3-e1f5f9f8e0a2 rack1 UN 127.0.0.6 71.23 KiB 3 30.6% b41496e6-f391-471c-b3c4-6f56ed4442d6 rack1
在上面的輸出結果中我們可以直觀迅速地看到該叢集可能已經處於失衡狀態。
就像我們針對單個節點對應單個令牌的叢集所做的那樣,這裡我們可以用cqlsh建立一個測試鍵空間,並向其中輸入資料。接著,我們通過讀取資料來看一下令牌環的情況。同樣的,為了使這個例子更容易理解,我們在每個令牌的右邊手動新增一個代表該令牌的字母。$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
8828652533728408318 R
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% -7586808982694641609 A
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% -6737339388913371534 B
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% -5657740186656828604 C
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% -3714593062517416200 D
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% -2697218374613409116 E
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% -1044956249817882006 F
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% -877178609551551982 G
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% -852432543207202252 H
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% 117262867395611452 I
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% 762725591397791743 J
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% 1416289897444876127 K
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% 3730403440915368492 L
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% 4190414744358754863 M
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% 6904945895761639194 N
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% 7117770953638238964 O
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% 7764578023697676989 P
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% 8123167640761197831 Q
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% 8828652533728408318 R
就像上面“Owns”那列所顯示的,令牌區間的分配有著較大的失衡現象,導致各個節點所負責的資料量有很大的不同。 IP地址為127.0.0.3的節點有著最小的令牌區間,該節點擁有39.89%的資料副本;而IP地址為127.0.0.2的節點有著最大的令牌區間,該節點擁有66.6%的資料副本——這兩者居然幾乎相差了26%。 就像前面所做的那樣,我們可以捕獲ccm node1 nodetool describering test_keyspace的輸出結果,並且將令牌序號換成上面令牌環輸出結果中相應的字母。
$ ccm node1 nodetool describering test_keyspace
Schema Version:4b2dc440-2e7c-33a4-aac6-ffea86cb0e21
TokenRange:
TokenRange(start_token:J, end_token:K, endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.4], rpc_endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:K, end_token:L, endpoints:[127.0.0.1, 127.0.0.4, 127.0.0.2], rpc_endpoints:[127.0.0.1, 127.0.0.4, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.4], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:I, end_token:J, endpoints:[127.0.0.6, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.6, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:R, end_token:A, endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:M, end_token:N, endpoints:[127.0.0.2, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.2, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:H, end_token:I, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:L, end_token:M, endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.5], rpc_endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:N, end_token:O, endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:P, end_token:Q, endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.5], rpc_endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:Q, end_token:R, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.1], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:F, end_token:G, endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.5], rpc_endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.1], rpc_endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:G, end_token:H, endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.6], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:O, end_token:P, endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
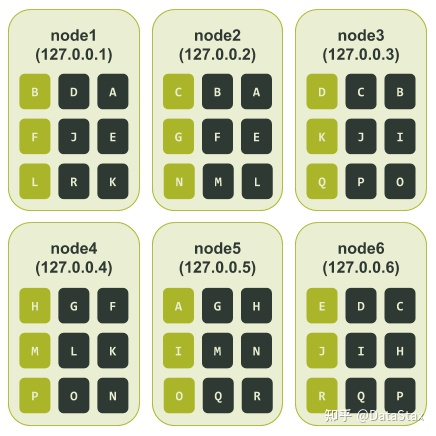
最後,我們就可以知道所有節點所被分配到的令牌區間了——它們如下圖所示:
根據上圖,我們可以看看如果發生像是前面提到的單個節點對應單個令牌的叢集所遇到的故障(即節點3和節點6處於不可用狀態),結果會如何。
上圖中我們可以看到節點3和節點6都負責令牌區間C、D、I、J、Q。所以如果我們的應用程式的一致性級別是LOCAL_QUORUM,那麼與這些令牌相關的資料都會處於不可用狀態。
換句話說,與單個節點對應單個令牌的叢集不同,在這種情況下,33.3%的資料可能再也無法被讀取了。
07 上機架 經驗豐富的Cassandra使用者會注意到,到目前為止,我們只在一個單獨的機架(rack)上針對我們的叢集進行了令牌分配測試。在使用vnode時,我們可以通過部署更多的機架來提高可用性。 當使用多個機架時,Cassandra會試著在每個機架上都只存放一個單獨的資料副本——即Cassandra會試著確保在同一個機架上,不會出現兩個完全相同的令牌區間。 這裡的重點是要做好叢集的配置工作——對於一個給定的資料中心,其機架的數量應該與其複製因子(replication factor)相等。 讓我們再用一下前面num_tokens被設為3的例子,不過這次我們在測試叢集中會定義3個機架。在用ccm配置並啟動節點後,我們重新配置好的測試叢集的初始狀態如下:
$ ccm node1 nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 127.0.0.1 71.08 KiB 3 31.8% 49df615d-bfe5-46ce-a8dd-4748c086f639 rack1 UN 127.0.0.2 71.04 KiB 3 34.4% 3fef187e-00f5-476d-b31f-7aa03e9d813c rack2 UN 127.0.0.3 66.04 KiB 3 37.3% c6a0a5f4-91f8-4bd1-b814-1efc3dae208f rack3 UN 127.0.0.4 109.79 KiB 3 52.9% 74ac0727-c03b-476b-8f52-38c154cfc759 rack1 UN 127.0.0.5 66.09 KiB 3 18.7% 5153bad4-07d7-4a24-8066-0189084bbc80 rack2 UN 127.0.0.6 66.09 KiB 3 25.0% 6693214b-a599-4f58-b1b4-a6cf0dd684ba rack3
我們仍能看到一些表明叢集可能處於失衡狀態的跡象,不過這是次要問題——在上面的程式碼中,我們的主要關注點在於現在我們在1個叢集中定義了3個機架,並且為每個機架分配了2個節點。 與前面我們對單個節點的叢集所做的操作類似,我們可以用cqlsh建立一個測試鍵空間,並向其中輸入資料。接著,我們通過讀取資料來看一下令牌環的情況。與前面的測試相同,為了使這個例子更容易理解,我們在每個令牌的右邊手動新增一個代表該令牌的字母。
ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
8993942771016137629 R
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% -8459555739932651620 A
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% -8458588239787937390 B
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% -8347996802899210689 C
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% -5712162437894176338 D
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% -2744262056092270718 E
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% -2132400046698162304 F
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% -1232974565497331829 G
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% 1026323925278501795 H
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% 3093888090255198737 I
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% 3596129656253861692 J
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% 3674189467337391158 K
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% 3846303495312788195 L
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% 4699181476441710984 M
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% 6795515568417945696 N
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% 7964270297230943708 O
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% 8105847793464083809 P
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% 8813162133522758143 Q
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% 8993942771016137629 R
與前面的測試步驟一樣,我們