
聊聊訊息佇列高效能的祕密——零拷貝技術
阿新 • • 發佈:2021-04-01
# 一、前言
RocketMQ為什麼這麼快、Kafka為什麼這麼快?用了零拷貝技術?什麼是零拷貝技術,它們二者的零拷貝技術有不同嗎?
# 二、為什麼需要零拷貝
在計算機產業中,I/O的速度相較CPU,總是太慢的。SSD硬碟的IOPS可以達到2W、4W,但是我們CPU的主頻有2GHz以上,也就意味著每秒會有20億次的操作。如果對於I/O操作,都是由CPU發出對應的指令,然後等待I/O裝置完成操作之後返回,那CPU有大量的時間其實都是在等待I/O裝置完成操作。**但是,這個 CPU 的等待,在很多時候,其實並沒有太多的實際意義。我們對於 I/O 裝置的大量操作,其實都只是把記憶體裡面的資料,傳輸到 I/O 裝置而已。**在這種情況下,其實 CPU 只是在傻等而已。特別是當傳輸的資料量比較大的時候,比如進行大檔案複製,如果所有資料都要經過 CPU,實在是有點兒太浪費時間了。因此計算機工程是們就發明了DMA技術,也就是直接記憶體訪問(Direct Memory Access)技術,來減少CPU等待的時間。
## DMA技術
本文不做過多相關介紹,這裡我簡單總結下對它的理解。
如上所述,CPU資源很寶貴,如果用它來處理I/O那麼將是極大的損失,比如說我們用千兆網絡卡或者硬碟傳輸大量資料的時候,如果都用CPU來搬運的話,肯定是忙不過來,所以可以選擇DMAC(DMA控制器即DMA Controller,簡稱DMAC),CPU告訴DMAC它需要傳輸什麼資料,從哪裡傳輸,傳輸到哪裡去這些資訊,然後交給DMAC去做,DMAC可以等到資料都到齊了,再發送訊號,交給CPU去處理,而不是讓CPU在哪裡忙等待。(**DMAC:我們不加工資料,只是資料的搬運工**)
具體傳輸過程(從磁碟傳輸到網路)如圖:
## 零拷貝
如上我們發現,雖然通過DMA技術能夠使得CPU不用忙等待I/O操作,減輕了一些壓力,但是從圖中也能清晰地看出,兩次CPU的Copy完全是在搞笑的,能不能把這兩個步驟去掉呢?這就是零拷貝需要做的事情了,而我們熟知的RocketMQ、Kafka都是使用了零拷貝技術來優化I/O,而它們的零拷貝處理方式卻有些不同。
### Kafka零拷貝——SendFile
Kafka的程式碼呼叫了Java NIO庫,具體是FileChannel裡面的transferTo方法(底層是。我們的資料並沒有讀到中間的應用記憶體裡面,而是直接通過Channel,寫入到對應的網路裝置裡。並且對於Socket的操作,也不是寫入到Socket的Buffer裡面,而是直接根據描述符(Descriptor)寫入到網絡卡的緩衝區裡面。於是,在這個過程中,只進行了兩次資料傳輸。(由於沒有在使用者態記憶體層裡面去Copy資料,幹掉了兩次CPU的Copy,所以我們將之稱為**零拷貝**(Zero-Copy)
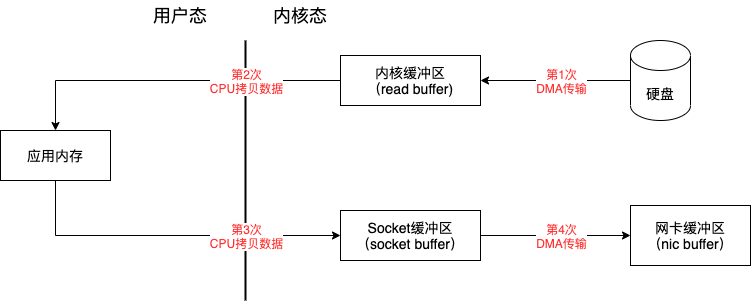
#### SendFile的工作原理
系統呼叫sendfile()通過DMA把磁碟資料拷貝到kernel buffer(read buffer),然後資料被kernel直接拷貝到另外一個與socket相關的kernel buffer(socket buffer)。這樣就沒有使用者態和核心態之間的切換,從核心中直接完成了從一個buffer到另一個buffer的拷貝,因為資料就在kernel裡。
如圖:
第一次,是通過 DMA,從硬碟直接讀到作業系統核心的讀緩衝區裡面。第二次,則是根據 Socket 的描述符資訊,直接從讀緩衝區裡面,寫入到網絡卡的緩衝區裡面。

**這是Kafka目前實時資料傳輸管道的標準解決方案,也是Kafka高吞吐的祕密之一,零拷貝。**
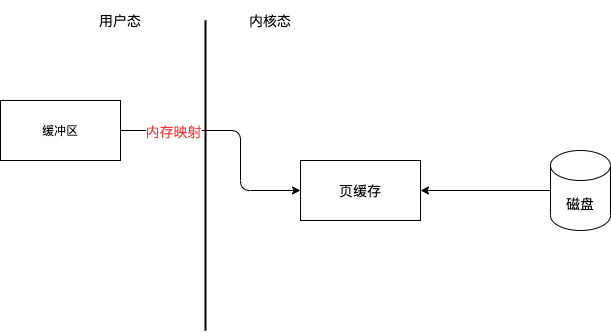
### RocketMQ零拷貝——Mmap
Mmap全稱Memory Mapped Files。簡單描述其作用就是:將磁碟檔案對映到記憶體,使用者通過修改記憶體就能修改磁碟檔案。
它的工作原理是直接利用作業系統的Page來實現檔案到實體記憶體的直接對映,完成對映之後你對實體記憶體的操作會被同步到磁碟上(作業系統在適當的時候)。
通過mmap也有一個很明顯的缺陷——不可靠,寫到mmap中的資料並沒有被真正地寫到磁碟,作業系統會在程式主動呼叫flush的時候才把資料真正寫到磁碟。
**RocketMQ主要通過MappedByteBuffer對檔案進行讀寫操作。其中,利用了NIO中的FileChannel模型將磁碟上的物理檔案直接對映到使用者態的記憶體地址中(這種Mmap的方式減少了傳統IO將磁碟檔案資料在作業系統核心地址空間的緩衝區和使用者應用程式地址空間的緩衝區之間來回進行拷貝的效能開銷),將對檔案的操作轉化為直接對記憶體地址進行操作,從而極大地提高了檔案的讀寫效率(正因為需要使用記憶體對映機制,故RocketMQ的檔案儲存都使用定長結構來儲存,方便一次將整個檔案對映至記憶體)。**
如圖:
# 總結
* CPU比I/O效能好很多,應當盡力給CPU讓步,讓它去做更多的事情,於是就有了DMA。DMA對CPU說,"你告訴我搬什麼資料,搬到哪裡,搬好了我告訴你,你先去忙別的"
* 我們發現,在資料傳輸過程中,有兩次CPU的Copy可以省去,於是就有了記憶體對映技術(Mmap)、SendFile技術(核心資料Copy),讓CPU不需要再白忙活了
* 市面上熟知的優秀中介軟體如RocketMQ使用的零拷貝技術是Mmap、Kafka使用的則是SendFile
參考資料:
《極客時間——深入淺出計算機組成原理》
《[Kafka順序讀寫與零拷貝(kafka為什麼這麼快)](https://blog.csdn.net/yizhiniu_xuyw/article/details/113809107?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.cont