
谷歌最新模型pQRNN:效果接近BERT,引數量縮小300倍
阿新 • • 發佈:2020-10-11

摘要:文字分類是NLP最常見的應用之一,有了BERT之後更是可以通過小批量資料精調達到不錯的效果。但在對速度要求高、沒有錢買GPU、移動裝置部署的場景下,還是得用淺層網路。今天就跟大家介紹Google最近新出的一個模型—— ...
人工智慧學習離不開實踐的驗證,推薦大家可以多在FlyAI-AI競賽服務平臺多參加訓練和競賽,以此來提升自己的能力。FlyAI是為AI開發者提供資料競賽並支援GPU離線訓練的一站式服務平臺。每週免費提供專案開源演算法樣例,支援演算法能力變現以及快速的迭代演算法模型。
文字分類是NLP最常見的應用之一,有了BERT之後更是可以通過小批量資料精調達到不錯的效果。但在對速度要求高、沒有錢買GPU、移動裝置部署的場景下,還是得用淺層網路。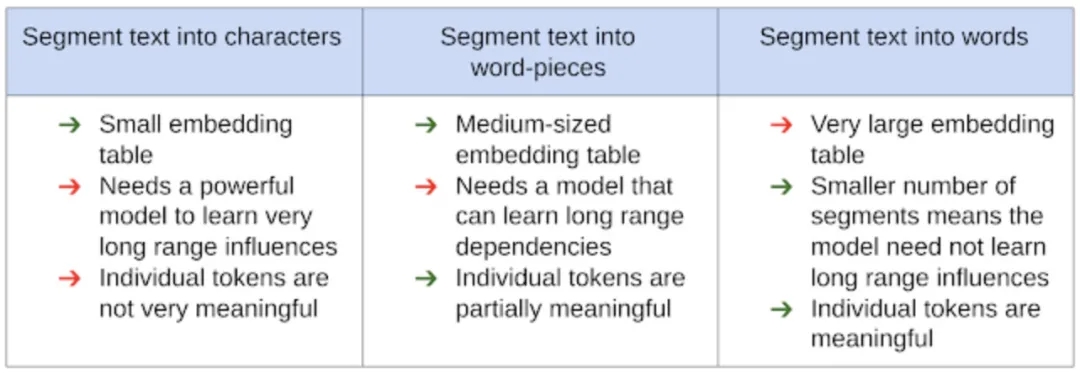
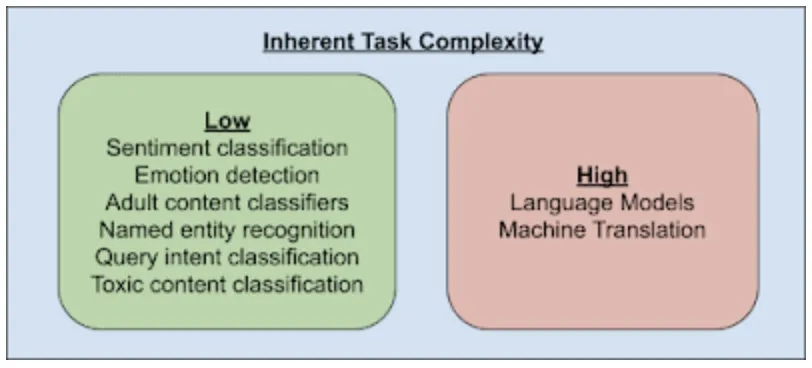
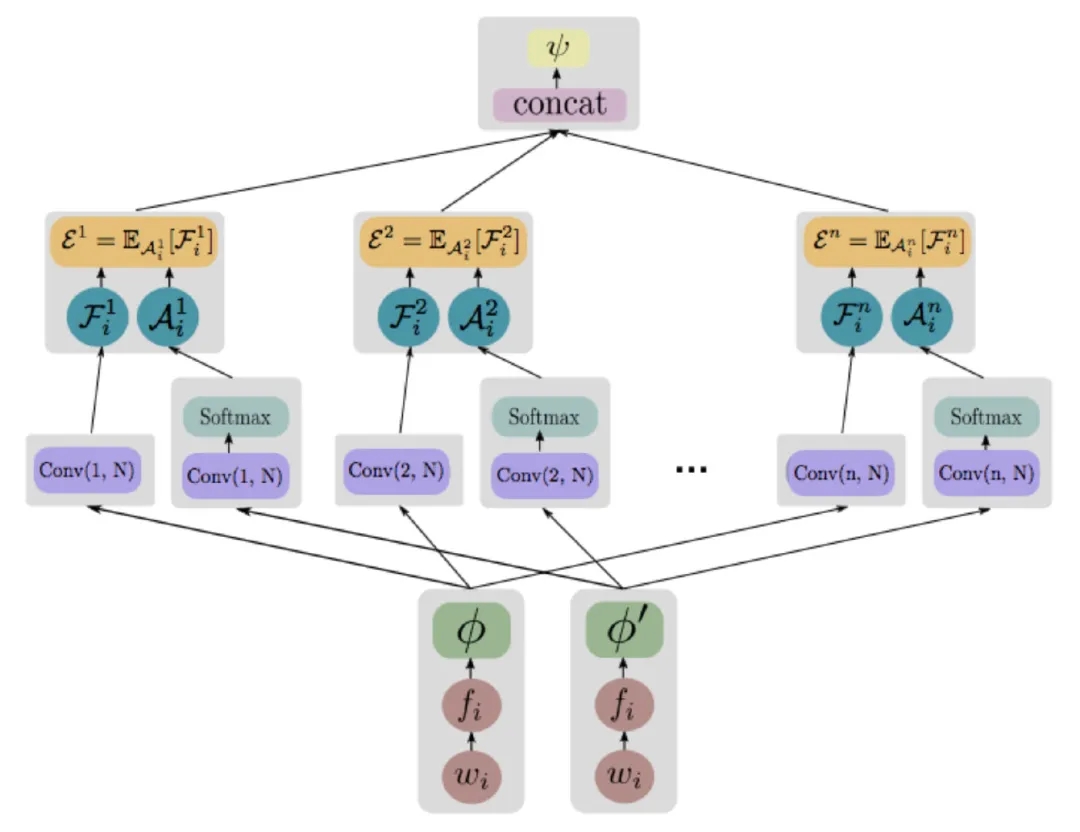
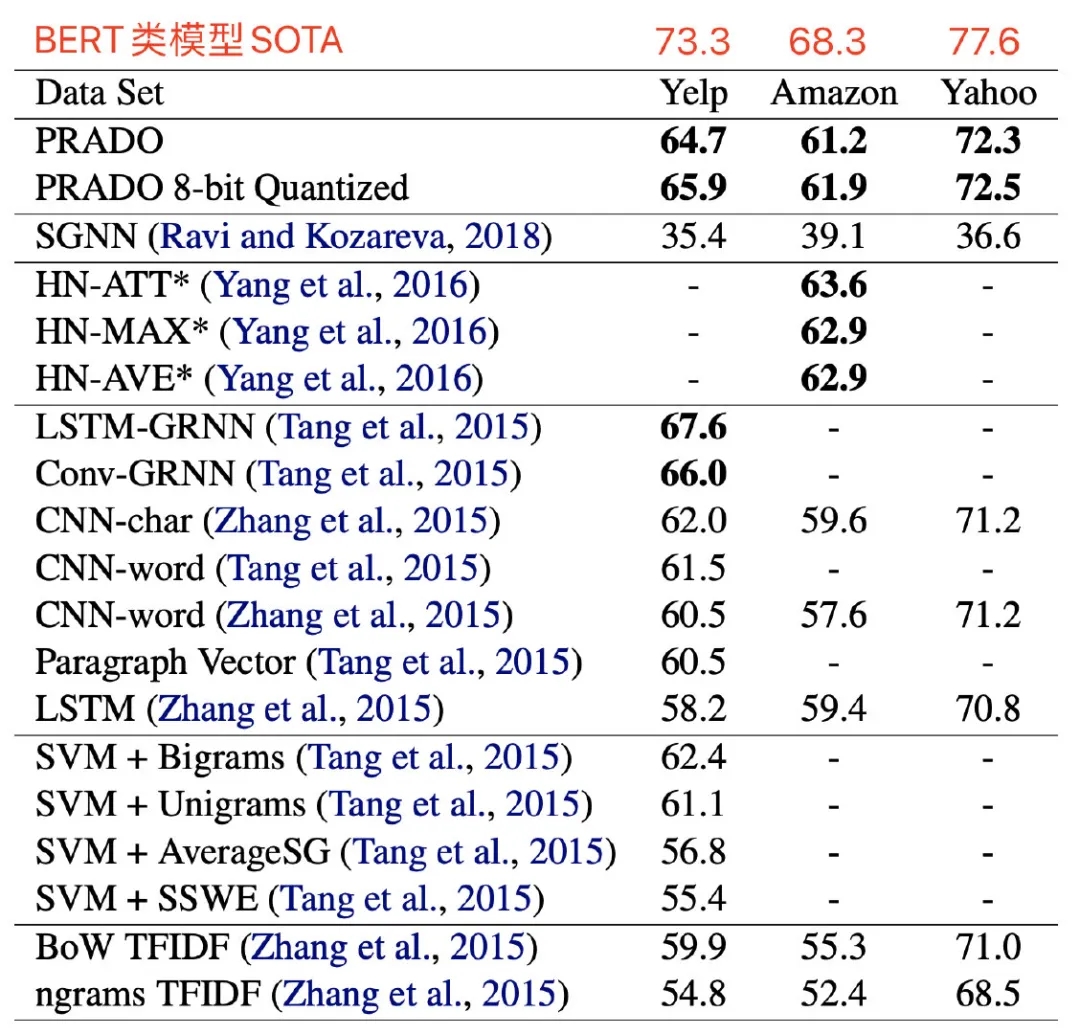
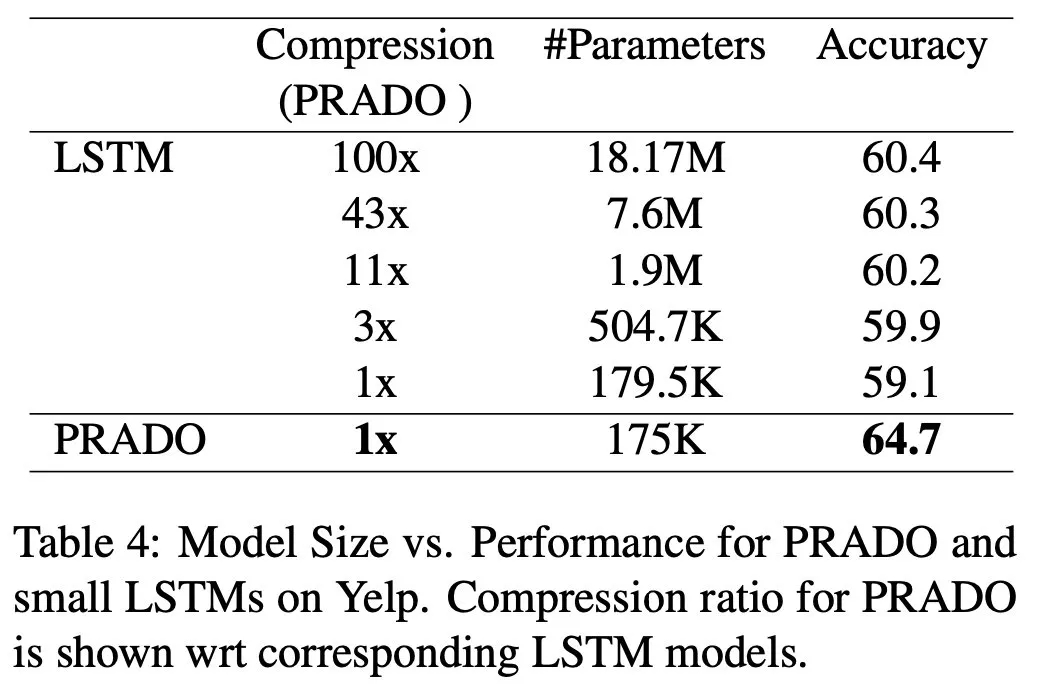
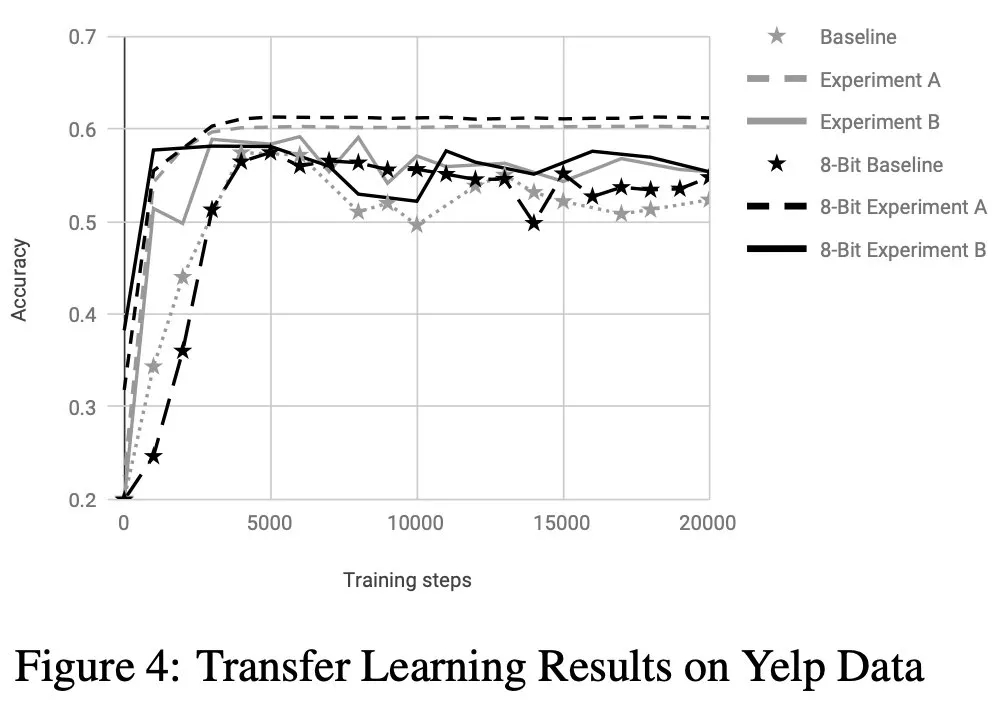

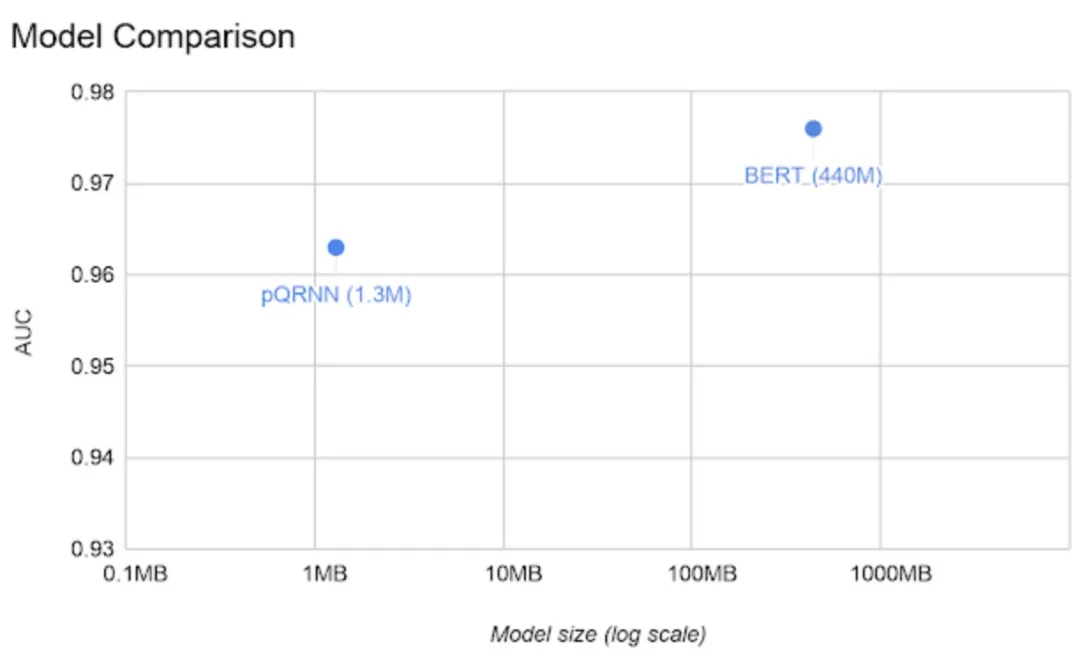

更多精彩內容請訪問FlyAI-AI競賽服務平臺;為AI開發者提供資料競賽並支援GPU離線訓練的一站式服務平臺;每週免費提供專案開源演算法樣例,支援演算法能力變現以及快速的迭代演算法模型。
挑戰者,都在FlyAI!!!