
深入 聚集索引與非聚集索引(一)
1.資料庫索引結構、2.表聯接、3.遞迴查詢這幾個點上。
一、基本概念
1.資料的讀取
頁(page)是SQL SERVER可以讀寫的最小I/O單位。即使只需訪問一行,也要把整個頁載入到快取之中,再從快取中讀取資料。物理讀取是從磁碟上讀取,邏輯讀取是從快取中讀取。物理讀取一頁的開銷要比邏輯讀取一頁的要大得多。
2.表的組織方式
表有兩種組織方式,B樹(Balance Tree)或者堆(Heap)。當在表上建立了一個聚集索引的時候,整個表資料就以B數的結構排列。否則就是按照堆的結構排列。無論表是怎麼組織的,都可以在表上面建立多個非聚集索引。非聚集索引都是以B樹的結構排列。
2.1 堆(Heap)
之所以這個結構稱為堆,是因為它不以任何人為指定的邏輯順序進行排列。而是按照分割槽組隊資料進行組織。也就是說,是按照磁碟的物理順序。只要需要讀取的資料檔案沒有檔案系統碎片(注意和下面提到的索引的碎片區分),這個讀取過程在磁碟中就可以連續的進行,沒有多餘的磁碟臂移動
堆使用一個bitmap結構來管理資料的分配。也就是它會告訴你兩個結果,這個區是分配了,還是沒有分配。每一個區中的物理順序如下圖。
對於新插入的資料,堆只管在最後一條資料的後面的一個空閒位置儲存新插入的資料,不保持任何的邏輯順序。比如拿order表舉例,如果先插入orderid 4,5,6, 假設在位置1:176、 1:177、1:178這三個位置。這時再插入1,這時儲存的資料就變味4,5,6,1, 1儲存在 1:179的位置。
2.2聚集索引(Clustered Index)
聚集索引以B樹的方式儲存資料。由於在另一篇文章中已經詳細的分析了B樹,這裡就不再詳細說明。
繼續拿Order表舉例,Order表中的全部資料都儲存在B樹中的葉層(leaf level)中,其他層只是起到一個索引的作用,並不包含任何資料。葉層是一個雙向連結串列結構,並按照聚集索引的主鍵的邏輯順序排列。因此邏輯順序是用指標來維護。
我們在圖中頁層所見到是邏輯順序,和上圖堆中所展示的物理順序要區分開來。
為什麼我一再強調邏輯順序和物理順序?因為理解這很重要。
如圖所示,聚集索引中除了B樹之外,仍然維護了一個IAM結構,而這個結構就能保證在需要的時候,我們能按照物理順序而不是邏輯順序去在葉層中讀取資料。
那麼什麼時候才需要呢?先看什麼是索引碎片。
2.2.1 索引碎片
資料庫中之所以會出現碎片,是因為B樹的頁拆分造成的。具體頁拆分請參考資料結構,這裡要說的是由於拆分所產生的新頁不保證一定就會在被拆分的頁的後面,而是可能出於檔案的任何位置。這就是“無序頁”
因此在按邏輯順序讀取的時候,由於無序頁的存在,可能造成磁臂頻繁的擺動。別忘記,磁碟擺動是I/O中開銷最大的操作。而I/O往往是一個系統的瓶頸所在。
如果按照物理順序來讀取,也就是unordered讀取,就會避免上面所產生的問題。再次強調,unordered是指不按邏輯順序讀取,所以叫unordered。
2.2.2 索引的層數
索引的層數,也就是B樹的高度,直接表明了一次查詢操作在頁面讀取方面的開銷。一些執行計劃如Nested loop聯接會多次呼叫查詢操作。因此理解這個概念很重要。
樹的高度主要和以下幾個因素相關
- 表的總行數。
- 平均一行儲存資料的大小。
- 頁的平均密度。因為不是每一頁都應該填充滿資料,這樣可以減少頁拆分的次數。
- 一頁所能容納的行數。
具體公式也很簡單,3級索引大概能容納4百萬行,4級索引大概能容納4億行資料。因此通常一張表的索引層數通常為3到4級。
2.3非聚集索引(NonClustered Index)
非聚集索引也是以B樹組織的。和聚集索引的區別就在於它的葉層並不包含所有的資料。在預設情況下它只包含了鍵列的資料,幷包含了一個行定位符(row locator)。這個行定位符的具體內容取決於它建立在以堆形式的表還是以B樹組織的表,換句話說也就是這張表是否建立了聚集索引會影響到非聚集索引的行定位符。如果是建立了聚集索引,那麼這個行定位符就是一個聚集鍵,我們通過這個聚集鍵再次查詢聚集索引上的資料。
聚集索引上的非聚集索引
如果表是堆組織結構的,那麼它就是一個直接指向資料所在行的物理指標。
下圖是建立在堆上的非聚集索引
2.3.1 如果非聚集索引包含了我們需要查詢的所有資料
這種情況我們通常叫做索引覆蓋。
正因為非聚集索引有著和索引一樣的結構,並且由於非聚集索引所包含的列少,因此資料量就小,使得葉層的一頁能包含更多的行,因此進行一次I/O頁讀取的動作的時候,就能讀取進更多的行。因此查詢效率是最高的。
舉個不恰當的例子,美女徵婚,應徵人員的個人資訊表有 “姓名、 德、 智、 體 、美、 勞、 高、 富、 帥”這幾列,按姓名排序。美女只關注“高、 富、 帥”這三列的內容,為了更快的篩選,我們幫美女按照個人資訊表的內容重新制作了一張表,這張表忽略了其他資訊,只保留了高、富、帥和姓名,篩選效率當然就比原來關注更多內容時要高。
2.3.2 如果非聚集索引不包含我們需要查詢的所有資料
通俗的說這時我們就需要從非聚集索引中所包含的線索去包含所有資料的表中去找。
按照我們之前的定義換句話來說,就是通過非聚集索引中的行定位符去聚集索引或者堆中去查詢所需的資料。
二、通過例項來說明上述概念
我們建立一張Order表,表上建立了幾個索引
1.為orderdate列建立了聚集索引
2.為orderid列建立了非聚集索引
1.1.1 只為獲取整張表的資料,對資料順序不關心
SELECT [orderid]
,[custid]
,[empid]
,[shipperid]
,[orderdate]
,[filler]
FROM [Performance].[dbo].[Orders]
分析:由於我們需要獲取整張表的資料,因此不需要任何篩選也不需要任何排序。因此我們按照磁碟物理順序讀取出所有資料無疑是最快的選擇。 所以已排序為False. 再次說明這裡的順序是聚集鍵的邏輯順序,和物理順序不同。
通過IAM在聚集索引的葉層掃描。在這種情況下無論表是以堆或者B樹的形式組織情況都類似。
(1000000 行受影響)
表'Orders'。掃描計數1,邏輯讀取25081 次,物理讀取5 次,預讀23545 次,lob 邏輯讀取0 次,lob 物理讀取0 次,lob 預讀0 次。
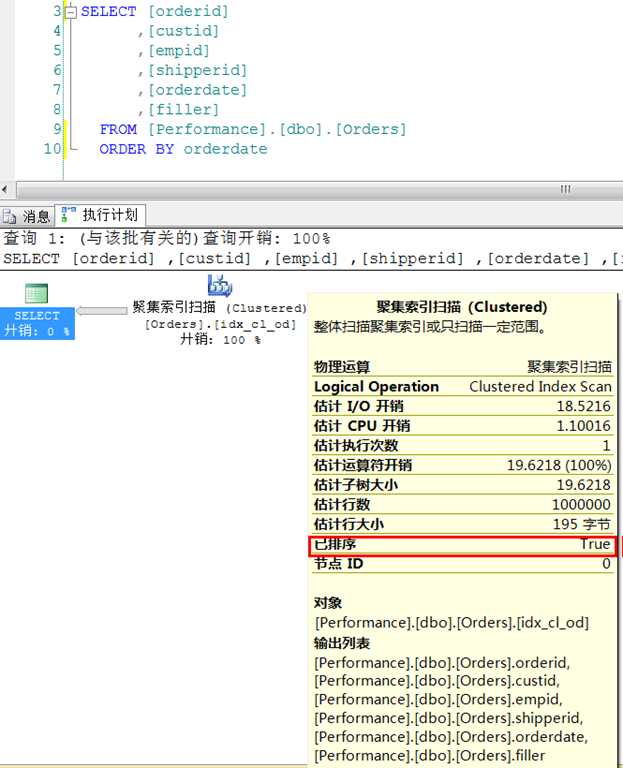
1.1.2 按聚集鍵順序獲取整張表的資料
對於Orders表,以orderdate為聚集鍵,因此如果我們使用順序查詢,就可以直接獲取所需要的資料。
{kind=link}
這是我們就不再通過IAM來對葉層進行掃描,而是通過葉節點的指標來進行掃描。
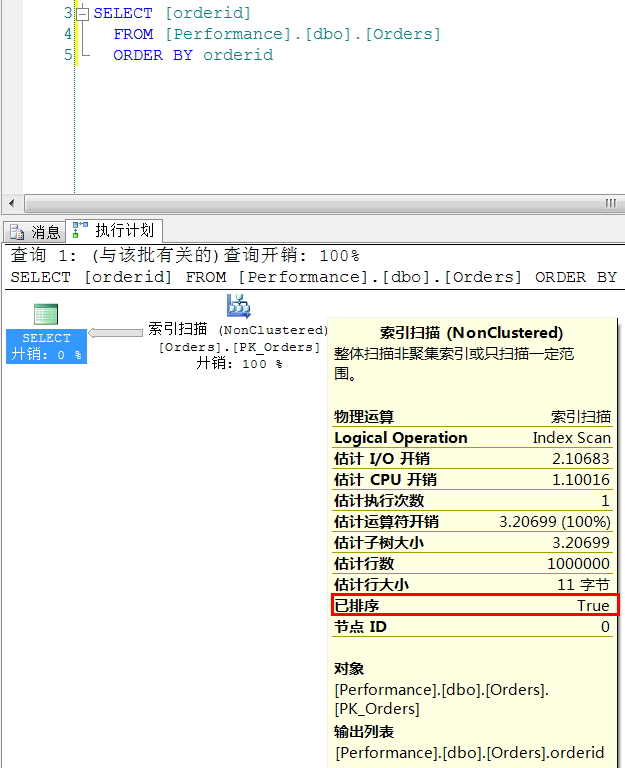
1.1.3 如果不按照聚集鍵,而是按照其他列的順序來獲取整張表
我們並沒有把orderid設定成聚集索引的鍵,而是把它設成了非聚集索引的鍵。因此在返回整張表的內容時:
1.非聚集索引鍵列orderid對我們沒有意義,因為我們期望返回的是整張表的內容,而非聚集索引只包含鍵列的內容。
2.聚集鍵列orderdate的順序在這裡對我們是沒有什麼用的。
由上面的推論可以知道,這時我們所建立的索引對我們都沒有任何幫助。因此,與其按照邏輯順序返回,不如按照最快速的無序返回,再把返回的結果集排序。而計劃證明了我們的猜想。
{kind=link}
1.1.4 如果我們要查詢的內容,正好在非聚集索引裡面就已經包含了
和上面查詢基本類似,區別在於我們在查詢結果中把非聚集索引中不包含的列全部刪除了,這時非聚集索引就形成了覆蓋。我們就可以利用非聚集索引進行查詢。
一些索引建議:
1.對於長字串,比如VARCHAR(80)這種型別的索引要比更為緊湊資料型別的索引大很多。同樣地,你也不太可能對長字串列進行全匹配查詢。
{kind=link}