
TDH大數據平臺數據入庫方案
一、數據入庫方式
目前批量數據入庫TDH大數據平臺主要有如下幾種方式
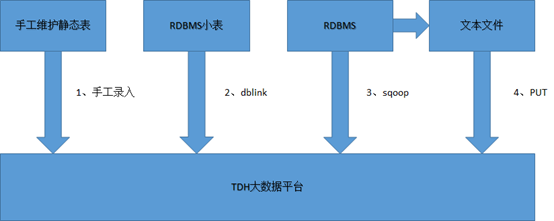
1、手工入錄
一些靜態表手工維護的數據,可以直接采用insert導入,或者使用waterdrop客戶端工具導入,只適用少數據量的導入和更新
2、dblink
TDH inceptor支持建立dblink直接連接db2,oracle,mysql等關系數據庫,對於一些數據量不大的靜態表,手工維護的表,可以通過建立dblink的方式獲取數據
優點:簡單方便
缺點:1)對大數據量的表,效率較差
2)初次使用相應數據庫的dblink時,需要導入對應數據庫的驅動jar包到 inceptor 的lib目錄,重啟才能生效
3、sqoop直接抽取
可以使用sqoop的方式從RDBMS關系型數據庫抽取數據到TDH大數據平臺
優點:1)支持各種類型的關系型數據庫;
2)數據可以直接導入到HDFS;
缺點:1)sqoop單map導入數據不快,多map導入速度快,但是同時導出的表多時,關系型數據庫需要抗壓
2)當生產系統的數據導出要給多個系統使用或者數據重采,每個系統都需要再次從源系統抽取數據,源系統壓力較大
3)對ORACLE的colb,blob等字段,導出速度慢
4)RDBMS-文件服務器-TDH平臺
先使用相應的數據庫導數工具導出成文本文件,然後把文本文件上傳到TDH大數據平臺
優點:1)使用數據庫相對應的導數工具,數據導出速度快,put到hdfs數據也快 特別適合數據量大,導出表多的情況
2)當有多個系統需要使用源系統導出的數據時,可以直接共享導出的文件
3)可以制定統一的數據入庫規範
缺點:1)需要文件采集服務器,增加服務器和存儲成本
二、數據入庫流程
3,4 兩種是目前主要采用的數據入庫方案,詳細流程見下圖
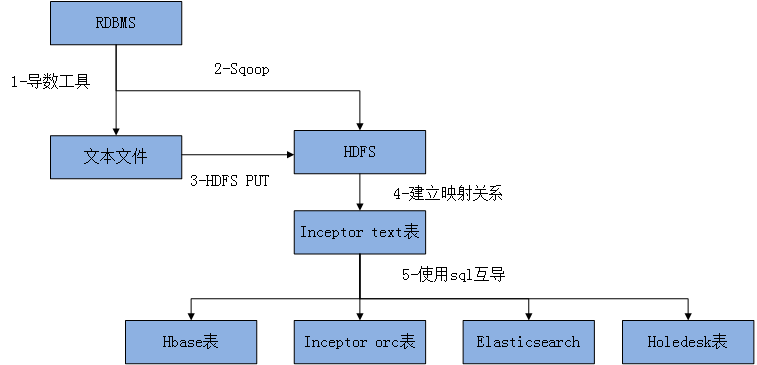
流程1
1)關系型數據庫通過導數工具導出文件到采集服務器
2)采集服務把本地文件put到HDFS上
3)對PUT到hdfs上的文件建立inceptor text映射表
4) 此時可以通過sql的方式根據不同的需要把數據導入 TDH的不同類型的表裏了
註:
inceptor是一個強大的分布式數據庫引擎,各個不同類型表的數據可以通過inceptor使用SQL的方式互相導,簡單方便快捷
流程2
1)直接通過sqoop 把RDBMS中的數據導出成hdfs文件
2)對PUT到hdfs上的文件建立inceptor text映射表
3) 此時可以通過sql的方式根據不同的需要把數據導入 TDH的不同類型的表裏了
流程3
如果是文本文件
參照流程1從第二步開始導入即可
TDH大數據平臺數據入庫方案