
Streaming 101
開宗明義!本文根據Google Beam大神Tyler Akidau的系列文章《The world beyond batch: Streaming 101》(批處理之外的流式世界)整理而成, 主要討論流式數據處理。在大數據領域,流式數據處理越發地重要了。原因有以下幾點:
-
人們越來越想要得到更及時的數據,而切換到流式處理(streaming)無疑是一個降低延時的好辦法
-
海量數據的生產變得越來越頻繁,即使是小公司也會產出超大量的每日數據。因此必然要求有一種系統能夠處理這種無窮多的數據集合
-
數據更快地被處理可以實現負載均衡,對資源的消耗也更加可控
基於這種業務需求驅動的流式處理浪潮逐漸興起,但現存的流式處理系統比起它們的“一生之敵”批處理系統而言尚不能算成熟,故而在這個領域內依然大有可為。討論流式處理,有些問題必須要先搞清楚:
-
術語:如此復雜的討論不明晰術語一定是舉步維艱的。當前在流式處理的概念中名詞歧義現象十分常見,故消除歧義明確含義的事情一定要首先完成
-
能力邊界:知其為,也要知其不可為。流式處理系統能做什麽,不能做什麽,這是個大問題
-
時間概念:明確兩個時間維度的名詞概念以及它們之間的聯系還有各自的優劣
術語:什麽是流式?
Streaming——流式一詞含義極多,澄清有些難度。困難的原因在於我們解釋一個事物通常喜歡以解決或完成這個事物的方式進行描述,而非它的本質。這種不好的習慣掩蓋了streaming的本質。在某些情況下,這可能會給人帶來一種誤解:仿佛流式系統就只能以流式方式進行處理,從而計算出來的結果值也不是準確的。實際上,如果設計得當,流式系統完全可以重復地計算出正確的一致性結果。那麽何為streaming?streaming就是一類數據處理引擎,旨在處理無限的數據集——廣義上說,它既包括純streaming也包含模擬streaming的微批次實現(micro-batch)。Spark Streaming就是micro-batch思想的實現。
Streaming經常也被解釋成以下幾個名詞表示的意思:
-
無限數據(unbounded data)—— 表示一直增長,無窮無盡的數據集合,它們甚至被稱為“流式數據“。 這裏面的問題就在於當我們說streaming或batch的時候我們其實並不是在表征它們處理的數據的特性。如前所述,streaming或batch的本質是處理這些數據的執行引擎,而非數據本身。streaming和batch的主要區別其實也在於它們處理的數據的有限性,所以刻畫事物時應該抓住事物本質上的特點。這類數據的正確提法是:unbounded data和bounded data,而不是流式數據
-
無限數據處理(unbounded data processing)—— 應用在unbounded data上持續的數據處理。把streaming解釋成這個意思也是有問題的,因為batch引擎其實也可以處理unbounded data——重復多次地運行batch引擎已經被用於處理這類數據了,所以要區分streaming和unbounded data processing的區別
-
能做到低延時但計算結果不準確,只是近似值—— 說起streamig好像它就無法產生出準確計算的值一樣,這是不對的。事實上,batch系統不能做到低延時或產生近似值的觀念也只過時了——batch引擎當然可以產生近似準確的值。因此,我們最好使用低延時/近似值來表示這個意思,不要因為歷史上它們是由streaming引擎產生出來的,就認為把它們和streaming等同起來。
再次強調一下,streaming表示的是用於處理unbounded data的執行引擎,僅此而已!
確定能力邊界
—— 特別在世人誇大了streaming的限制之後
下面我們討論一下streaming系統能做什麽,不能做什麽,重點強調它能做什麽。Streaming系統長期以來一直被視為是一個小眾領域,它以低延時的方式產出近似準確的結果,而且streaming通常還與功能更加強大的batch系統協同工作最終為用戶提供準確的結果。具體而言就是同時部署一套batch系統和一套streaming系統,兩套系統一起執行相同的計算。streaming系統實時運行,延時低但結果不準確(因為使用了近似算法或系統本身就沒有提供準確性保障),而batch系統雖稍後登場,但能夠保證計算結果是準確的——這種部署方式或架構最早由Apache Storm的作者Nathan Marz提出,並經實踐證明後被認為是在當時非常成功的。從準確性這點來看,streaming系統的確不盡如人意,而batch系統通常又很笨拙,因此兩者的結合簡直可謂是“魚與熊掌的兼得"。令人遺憾的是,維護兩套系統的成本是很高的——因為它們是兩套獨立的數據管道,同時它們產出的結果有需要執行合並操作。
Tyler本人對於強一致性的streaming引擎有著很深的造詣,他本人並不贊同這種兩套系統的架構設計——相反地,他是Jay Kreps提出的可重演系統的擁躉(你不知道Jay Kreps是誰? 好吧,你總聽過Kafka吧,他是Kafka的原作者):使用Kafka這樣的可重演系統連接streaming引擎以解決可重復性的問題,並自始至終地使用一套管道來進行數據處理。如果把這個觀點更進一步,我們可以認為定義良好的streaming系統甚至提供的是batch引擎所具功能的超集(superset)——事實上, 去年火爆開源社區的Apache Flink就是這樣的思想,Flink中的batch引擎是作為streaming引擎的一個特例而實現的,這點和Spark streaming正好相反:Spark streaming的streaming其實是借助於micro-batch的思想而實現的。如果不是目前執行效率上的一些差異,當今batch系統根本沒有存在的必要的。在這點上要感謝Flink開發者為我們構建了一個”隨時隨地streaming化“的系統,即使是batch模式,Flink底層也是使用streaming實現的。
所有這一切的結論就是:streaming系統的廣泛成熟與無窮數據處理框架的結合必然會令batch引擎逐步退出歷史舞臺。不過streaming系統若要打敗batch系統,還需要完成兩件事情:
正確性
正確性幫助streaming系統足以匹敵batch系統。從本質上說,正確性可歸結為一致性存儲。streaming系統需要有能力定期地持久化狀態(checkpoint)並且還要能夠維護系統崩潰下的一致性。Spark streaming在這方面是先驅,它很好地維護了一致性。時至今日很多streaming系統都能夠做到這點了——最多一次的處理語義實在是個偽命題,但目前它依然存在。再次強調一下:強一致性是實現”精確一次處理語義”的必要條件,“精確一次處理語義”是實現爭取性的必要條件,而任何streaming系統,若想要打敗batch系統就必須實現正確性。除非真的不在乎計算結果,否則還是建議盡量不要使用那些不提供強一致性的streaming系統。若要學習如何實現強一致性,Spark streaming論文是很好的材料,推薦大家讀一讀。
推導時間的工具
如果說正確性幫助你的streaming系統匹敵batch系統,那麽這些工具將令你超越batch。推導時間的工具是處理無界無序數據集的利器。當前海量數據表現出來的特點是隨機變化的數據傾斜——即事件被處理的時間與事件真實發生時間的差值隨機分布,而現有的bach系統(以及大部分的streaming系統)都無法處理這種情況——這也是streaming系統著重要解決的問題之一。
接下來我們需要了解一下時間方面的2個概念,然後才能深入地去討論下之前說的無界無序數據隨機變化的時間差值是什麽意思,最後針對這些問題streaming系統都有哪些解決之道。
Event time VS. Processing time
坦率地說,無界數據處理先搞清楚時間概念。在任何數據處理系統中,通常都有兩類時間維度的概念:
-
Event time,即事件真實發生的時間,正式名稱是發生時間
-
Processing time: 事件在系統中被觀測到的時間,正式名稱是處理時間
並非所有情況都需要考慮event time——事實上,如果你根本不care發生時間,事情變得簡單多了,也許後面的你都不用看了——但很多場景下event time確實是需要被考慮的,比如統計用戶行為、計費系統以及很多異常檢測等。理想情況下,event time和processing time應該是相等的,即事件一旦發生就立即被處理。顯然,這不可能是真的,兩者之間的差值不僅不為0,而且通常是由各種因素影響的一個變化的函數——我們把這個差值不為0的事實成為時間傾斜,或簡稱為傾斜(skew)。影響這種skew的因素可能有輸入源、執行引擎或硬件等。具體來說包括:
-
共享資源限制:比如帶寬爭用、網絡分區或CPU資源共享等
-
軟件原因:分布式系統邏輯限制、競爭等
-
數據本身的特性導致,包括key分布,TPS變動或無序性變動
因此,如果分別以event time和process time為軸畫一張圖的話,那麽一個真實場景下的數據傾斜分布就應該類似如下圖這個樣子:
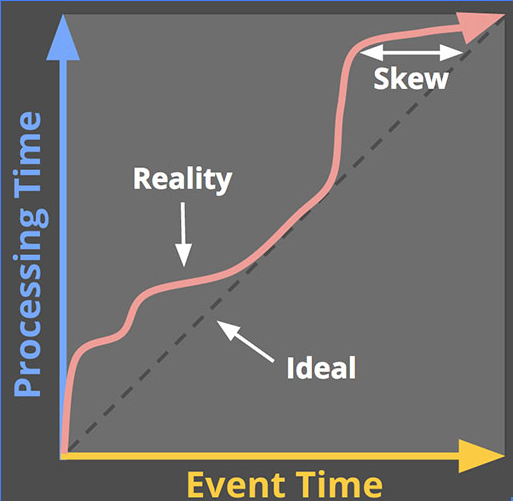
黑虛線表示理想情況,斜率=1表示event time總是等於processing time;紅線表示實際情況。在實際場景中系統總是會滯後一些,表現為processing time永遠大於event time,但兩者的差值其實一條變動的曲線,最開始時差距很大,在中段逐漸靠近理想情況,最後又開始偏離。曲線上同一個縱軸點對應的兩個橫坐標的差值即標識了現實與理想之間的skew——顯然這種skew是因為數據處理管道的延時所引入的。
Event time與processing time之間的差值不是固定的,這就意味著如果要使用event time,單靠processing time是不夠的。令人遺憾地是,目前大多數streaming系統在設計的時候都只是考慮了processing time。如果要處理這種無窮多的數據,streaming系統必須要規定一種類似於時間窗口似的的概念。本質上它就是沿著時間維度把數據劃分到不同的時間窗口中。雖然大部分系統就是這樣做的, 但如果要實現基於event time的正確性,使用processing time來定義時間窗口顯然是不行的。鑒於event time和processing time之間並沒有一致性的關系,很有可能我們會把某些event time數據劃分到錯誤的processing time窗口(比如因為延時)從而導致計算的不準確。後面需要詳細討論一下解決之道。
即使是根據event time進行時間窗口劃分也不是所有問題都解決了。對於unbounded數據而言,無序性和skew的不確定性會帶來一個完整性的問題:因為沒有可控的event time/processing time映射關系,我們如何能夠確定在時間窗口X中觀測到的數據是完備的?真實場景中,我們無法提供完備性驗證。主流的處理系統都依賴於完備性的概念,但當應用於無窮數據集時這些系統就有些捉襟見肘了。
與其把無限數據集打散到有限的batch中,我們不如設計一種工具可以讓我們能夠應付真實場景下的這種不確定性。新數據必將到達,舊數據可能會被刪除或更新,任何系統都應該獨立地處理這些事情。在這些系統中完備性的概念只是一個輔助而非一個必要條件。
下面我們討論一下常見的數據處理範型(data processing pattern),既包括streaming引擎也包括batch引擎。micro-batch也被算作是streaming引擎。
有限數據集
處理有限數據集很簡單,如下圖所示:
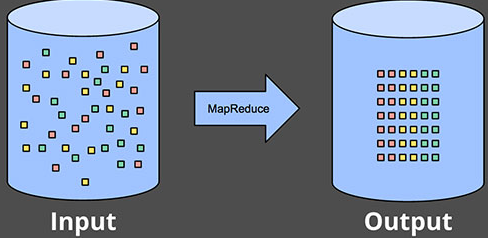
上圖中左邊的數據集雜亂無章,運行某個數據處理引擎後(通常是batch引擎,比如MapReduce)變成了右邊的“更有序”的樣子。怎麽搗騰數據雖然玩法是無窮的,但萬變不離其宗,這種處理方式是不變的,依然非常簡單。有挑戰的還是處理無窮數據集,包括batch處理無窮數據集和streaming處理無窮數據集。
batch處理無窮數據
雖然設計的時候並不是用於處理無窮數據集的,但batch引擎處理unbounded data可謂歷史悠久,誰讓batch是先發明出來的呢。具體的方法就是分而治之的思想,即以批處理的方式把無窮數據集劃分成一組有限數據集進行處理。
固定時間窗口
最常用的方式就是不斷執行batch引擎從而把輸入數據劃分成大小相等的窗口,如下圖所示。然後獨立地處理每個窗口中的數據。對於像日誌這種類型的輸入數據,日誌被寫入到不同的路徑和文件中,因此路徑和文件的名字就特別適合用於命名時間窗口。這樣看來似乎事情變得非常簡單了,你只需要執行一個基於時間的路由策略就可以把所有數據按照event time發送到不同的時間窗口中。在實際使用時,大多數的系統會遭遇完備性的問題:某些事件在寫入到日之前被耽擱了(比如網絡原因或磁盤IO),或者事件雖然是全局收集的但在處理前被轉移到一個公共的地方了,再或者事件是由移動設備發送過來的。這些情況中我們就需要一些手段來處理完備性,比如引入某種延時處理機制直到我們確信所有的時間都已經被收集了,或者只要那些晚到的數據到達,之前時間窗口中的數據就重新被處理一次。

如果batch引擎使用更加復雜的窗口策略(比如會話,session)來處理無界數據時,上面的方法就會更加的有局限性。Session本質上都被定義為特定用戶的操作時段。Session之間的時段就是該用戶無操作的時段。若使用batch引擎計算session,得到的session通常都是跨batch的,如下圖中紅色箭頭部分所示:
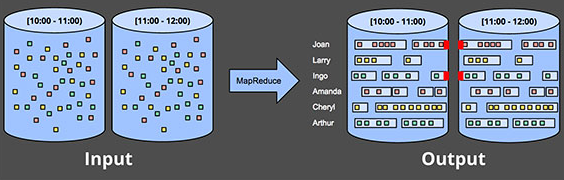
增大batch size固然可以減少這種跨度,但代價就是延時的增加。另一種辦法就是增加額外的邏輯將這種“斷裂”的session縫合在一起,不過想想就知道這實現起來有多復雜。不論那種方式,使用經典的batch引擎來計算session效率很低。更好的辦法是使用streaming的方式。
streaming處理無窮數據集
和大多數batch處理無窮數據集相反的是,streaming系統天生就是處理無窮數據集的。真實場景下的無限數據集有以下特點:
- 與event time高度無序——意味著你需要某種基於時間的路由規則
- 變動的event time skew——意味著你不能想當然地認為在[Y - a, Y + a]時間範圍內總是看到event time = X的所有數據
當然,處理這類數據時還是有一些方法可用的,基本上可以劃分成以下四類:
- 時間無關性方法
- 近似方法
- 基於process time的時間窗口
- 基於event time的時間窗口
時間無關性方法
如果本質上不關心時間——比如所有的邏輯都是數據驅動的——那麽這類方法就非常適合了。其實這也沒什麽新鮮的,一個streaming引擎通常都是要支持的。本質上說,所有現存的streaming系統都天然支持這種與時間無關的使用場景。Batch系統也非常適合這種時間無關性的數據處理,只需簡單地把無窮輸入源劃分成任意序列長度的有界數據集並分別獨立處理即可。下面舉幾個例子來說明一下:
Filtering: 一個典型的例子就是過濾(filtering),如下圖所示:

假設我們處理的是Web流量日誌,想要過濾出某個特定領域來的所有流量,那麽我們只需查看每條日誌的來源,如果不符合條件直接pass掉。顯然這和時間是沒有關系的,因此數據源是否是無序,無窮或是變動的skew就顯得不重要了。
Inner-joins: 另一個時間無關性的例子就是內連接(inner-joins)。當連接兩個無窮數據源時倘若我們只在乎連接的結果,則處理邏輯就不需要考慮時間的因素。一旦看到某股輸入源中出現一個值,那麽我們就把這個值緩存起來。當值出現在第二股輸入源時,只需要發送合並的消息即可了,如下圖所示:
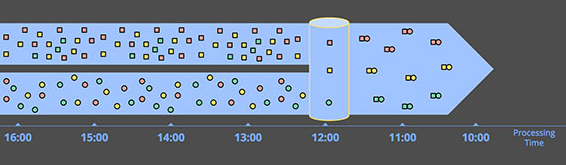
如果切換到外連接將引入數據完備性的問題:一旦看到了join的一邊,那麽如何才能確定另一邊也到達了呢?老實說,我們沒法得知,因此我們就必須引入某種超時機制——而這必然會引入時間因素。時間因素本質上就是時間窗口的形式。
近似算法

第二大類方法就是近似算法,比如近似的TopN,streaming K-means等。這些算法接收無窮數據源作為輸入,而輸出結果只能算是基本上滿足我們的預期。近似算法的好處在於開銷很低並且天生就是用於處理無窮數據集的,而缺點在於算法通常是很復雜的,而且它們的近似特性限制了它們的應用。值得註意的是,這些算法在設計上通常都引入了時間的元素。算法在處理事件時,時間因素通常都是基於processing time的,這對於提供了某類可控錯誤邊界的算法而言是極其重要的。近似算法本身也可以被視為是與時間無關性處理的另一個例子。
時間窗口
剩下的兩類方法都是時間窗口的變種,首先討論下時間窗口的具體含義。時間窗口本質上就是將數據源沿著時間線劃分成有限的數據塊。下圖表明不同的窗口範型:
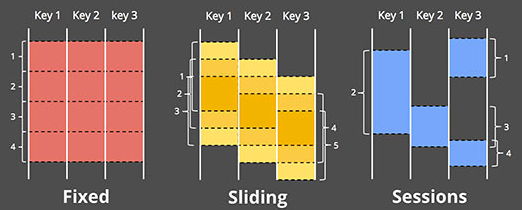
- 固定窗口———— 固定窗口把時間劃分成固定大小的段。具體還可以細分為對齊窗口和未對齊窗口
- 滑動窗口———— 固定窗口的一種廣義形式,滑動窗口也是有固定的長度以及固定的間隔。如果間隔長度<窗口長度,那麽窗口必然會造成重疊。如果間隔長度=窗口長度,那麽就是固定窗口。如果間隔長度>窗口長度,這就被稱為“取樣窗口”,它只會查詢一部分數據。滑動窗口通常是對齊的。
- 會話———— 屬於動態窗口,會話就是一組事件序列,通常被用於分析用戶行為。既然是用戶操作事件序列,我們無法提前為session定義窗口長度,而且由於在實際中不同的用戶其session也是不同的,因此它們屬於經典的未對齊窗口
對於processing time和event time而言,時間窗口都是適用的,當然還是有區別的。我們首先來看基於processing time的時間窗口:
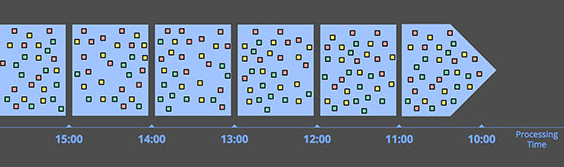
根據processing time創建時間窗口時,系統會緩存輸入數據到窗口中直至超過了某段時間。比方說對於5分鐘的固定時間窗口,系統會緩存之前5分鐘的所有數據並封裝進一個窗口中,之後發送給下遊系統用於處理。這種窗口的特點如下:
- 簡單
- 極易檢驗完備性:系統完全知道所有輸入數據是否已經到來,無需處理延時數據
- 適用於數據被觀測被產生價值的使用場景,比如通過計算每秒請求數的變化來判斷是否出現服務中斷
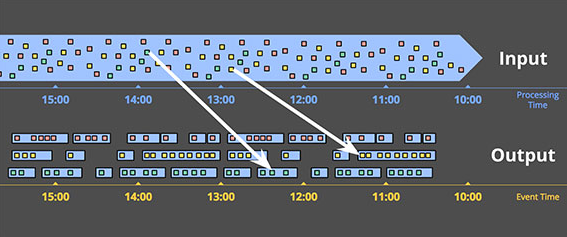
不過這種基於processing time的窗口有一個非常大的缺陷:必須要求數據按照event time順序到達,否則無法真實再現事件發生場景,但是按照event time順序的輸入數據幾乎不存在。。。。舉個簡單的例子,假設手機上的一個app收集用戶統計信息。當手機未連上網絡時,這段時間內收集到的數據就無法上傳。這就意味著數據可能比真實的發生時間晚幾分鐘、幾個小時、幾周甚至更長。在處理時間窗口時,期望從這樣的數據集中獲取任何有用的結論都是不可能的。另一個例子,假設有一個全球服務處理從各個大洲收集上來的數據。如果網絡問題導致帶寬受阻,那麽此時必然造成數據的skew。如果對這種數據基於processing time做窗口,那麽這種窗口就無法表達包含在它們之下數據的真實發生情況。相反地,它們表示的是事件到達時的情況,必然是新舊數據相互混合的。這兩個例子其實都應該以event time進行時間窗口的劃分——即所謂的基於event time的時間窗口。
基於event time的時間窗口:反映事件發生時間的時間窗口。下圖展示了一個基於event time的1小時固定時間窗口:
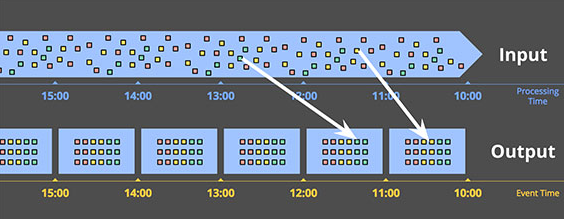
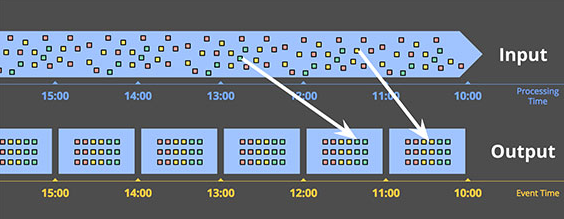
兩條白線表明了兩個特殊的數據:這兩個數據點上的數據對應的processing time時間窗口與基於event time的時間窗口是錯配的。因此如果使用基於processing time的時間窗口必然造成結果的不準確。由此可見,能夠提供正確性是基於event time時間窗口的一大優勢。
基於event time時間窗口的另一個優勢在於它的大小可以動態變更,比如session,再不會有跨batch或跨窗口的情形發生,如下圖所示:
天下沒有免費的午餐。這種時間窗口有2個缺陷:
- 需要額外緩存:因為時間窗口的時間周期來拉長,需要緩存更多的數據。當然現在存儲的成本不斷下降,此缺陷便顯得不是那麽重要了
- 完備性:因為無法明確得知某個窗口下的所有數據都已經到來,因此便無法確認何時才能開始處理這個窗口下的數據。在實踐過程中,系統通常會給一個經驗值來定義窗口的完備性,但如果從絕對正確性的角度來考慮,唯一的解決辦法就是提供一種方式能夠讓窗口中的數據可以被重新處理從而不斷修正計算結果
以上就是我們對於streaming以及streaming系統的一些初級討論,第二篇中將會討論實際場景中streaming系統的解決之法。
Streaming 101