
《機器學習》(西瓜書)筆記(3)--線性模型
阿新 • • 發佈:2017-06-20
思路 ensemble n-1 containe 線性分類 mvm img 很大的 數學 第三章 線性模型
3.1 基本形式線性模型(linear model)試圖學得一個通過屬性的線性組合來進行預測的函數,即 一般用向量形式寫成
一般用向量形式寫成 ,其中
,其中 w 和 b 學得之後, 模型就得以確定。
w 和 b 學得之後, 模型就得以確定。
3.2 線性回歸對離散屬性的處理:
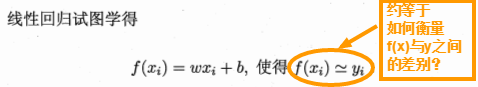 均方差誤差最小
均方差誤差最小 基於均方誤差最小化來進行模型求解的方法稱為最小二乘法(least square method)。線性回歸模型的最小二乘參數估計:指求解 w 和 b 使 E(w, b) = ∑(yi
基於均方誤差最小化來進行模型求解的方法稱為最小二乘法(least square method)。線性回歸模型的最小二乘參數估計:指求解 w 和 b 使 E(w, b) = ∑(yi  對數線性回歸(log-linear regression):
對數線性回歸(log-linear regression):
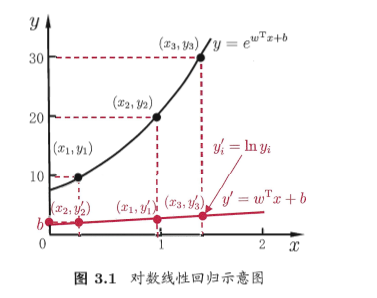 廣義線性模型:考慮單調可微函數g,令
廣義線性模型:考慮單調可微函數g,令 這樣得到的模型稱為廣義線性模型(generalized linear model),函數 g 稱為聯系函數(link function)。
這樣得到的模型稱為廣義線性模型(generalized linear model),函數 g 稱為聯系函數(link function)。
3.3 對數幾率回歸分類任務如何處理?對數幾率函數(logistic function):
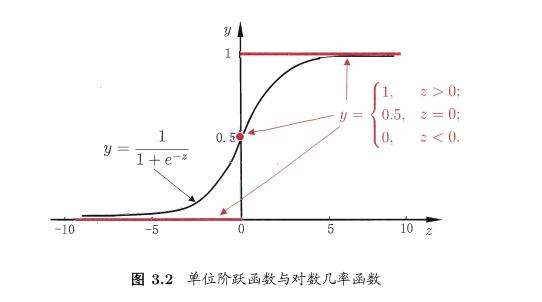

 幾率:若將 y 看做樣本 x 為正例的可能性,則 1-y 為樣本 x 為反例的可能性,這兩者的比例稱為幾率。對數幾率:將上述幾率取對數。
幾率:若將 y 看做樣本 x 為正例的可能性,則 1-y 為樣本 x 為反例的可能性,這兩者的比例稱為幾率。對數幾率:將上述幾率取對數。
對數幾率回歸:(**)式實際上是用線性回歸模型的預測結果去逼近真實標記的對數幾率,因此,其對應的模型稱為對數幾率回歸(logistic regression)。它是一種分類學習方法。
對數幾率回歸的優點
如何確定(**)式中的 w 和 b?
3.4 線性判別分析線性判別分析(Linear Discriminant Analysis,簡稱LDA)的思想:給定訓練樣例集,設法將樣例投影到一條直線上,使得同類樣例的投影盡可能接近,異類樣例的投影盡可能遠離。在對新樣本進行分類時,將其投影到同樣的這條直線上,再根據投影點的位置來去頂新樣本的類別。

3.5 多分類問題
考慮 N 個類別C1,C2,...,CN,給定數據集 D = {(x1,y1),(x2,y2),...,(xm,ym)}, yi ∈ {C1,C2,...,CN}OvO將這 N 個類別兩兩配對,從而產生 N(N-1)/2 個二分類任務。OvR是每次將一個類的樣例作為正例、所有其他類的樣例作為反例來訓練 N 個分類器。
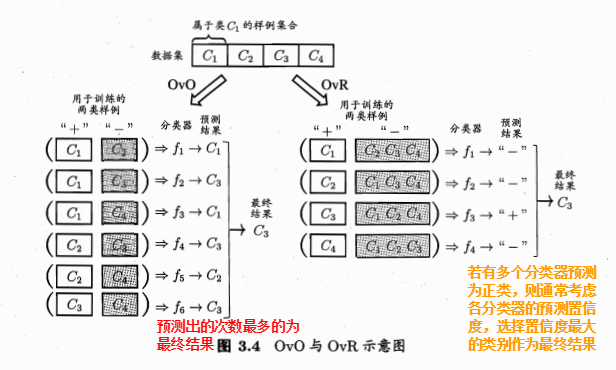
MvM是每次將若幹個類作為正類,若幹個其他類作為反類。MvM的正、反類構造必須有特殊的設計,不能隨意選取。最常見的MvM技術為糾錯輸出碼(Error Correcting Output Codes, 簡稱ECOC)。
 糾錯:在測試階段,ECOC編碼對分類的錯誤有一定的容忍和修正能力。
糾錯:在測試階段,ECOC編碼對分類的錯誤有一定的容忍和修正能力。
3.6 類別不平衡問題前面幾個分類學習方法都有一個共同的假設:不同類別的訓練樣例數目相同。類別不平衡(class-imbalance):指分類任務中不同類別的訓練樣例數目差別很大的情況。
以線性分類器為例,在用 y = wTx + b對新樣本 x 進行分類時,實際上是在用預測出的 y 值與一個閾值進行比較,大於閾值時為正例,反之則為反例。1. 正、反例數目相同時的閾值是0.5,即 2. 正、反例數目不同時的閾值是 m+ / (m+ + m-),即
2. 正、反例數目不同時的閾值是 m+ / (m+ + m-),即 m+ 表示正例數目,m- 表示返利數目。 這就是類別不平衡學習的一個基本策略——再縮放(rescaling)。
m+ 表示正例數目,m- 表示返利數目。 這就是類別不平衡學習的一個基本策略——再縮放(rescaling)。 
當“訓練集是真實樣本總體的無偏采樣”這個假設不成立時,有以下方法:
3.1 基本形式線性模型(linear model)試圖學得一個通過屬性的線性組合來進行預測的函數,即
3.2 線性回歸對離散屬性的處理:
- 若屬性值間存在序關系,可通過連續化將其轉化為連續值,例如二值屬性“身高”的取值“高”“矮”可轉化為 {1.0, 0.0};
- 若屬性值間不存在序關系,假定有 k 個屬性值,則通常轉化為 k 維向量。
均方差誤差最小 基於均方誤差最小化來進行模型求解的方法稱為最小二乘法(least square method)。線性回歸模型的最小二乘參數估計:指求解 w 和 b 使 E(w, b) = ∑(yi 廣義線性模型:考慮單調可微函數g,令3.3 對數幾率回歸分類任務如何處理?對數幾率函數(logistic function):
對數幾率回歸:(**)式實際上是用線性回歸模型的預測結果去逼近真實標記的對數幾率,因此,其對應的模型稱為對數幾率回歸(logistic regression)。它是一種分類學習方法。
對數幾率回歸的優點
- 它直接對分類可能性進行建模,無需事先假設數據分布,避免了假設分布不準確所帶來的問題。
- 它不僅預測出類別,還得到近似概率預測,對許多需利用概率輔助決策的任務很有用。
- 對率函數是任意階可導的凸函數,有很好的數學性質,現有的許多數值優化算法都可直接用於求取最優解。
如何確定(**)式中的 w 和 b?
3.4 線性判別分析線性判別分析(Linear Discriminant Analysis,簡稱LDA)的思想:給定訓練樣例集,設法將樣例投影到一條直線上,使得同類樣例的投影盡可能接近,異類樣例的投影盡可能遠離。在對新樣本進行分類時,將其投影到同樣的這條直線上,再根據投影點的位置來去頂新樣本的類別。
3.5 多分類問題
考慮 N 個類別C1,C2,...,CN,給定數據集 D = {(x1,y1),(x2,y2),...,(xm,ym)}, yi ∈ {C1,C2,...,CN}OvO將這 N 個類別兩兩配對,從而產生 N(N-1)/2 個二分類任務。OvR是每次將一個類的樣例作為正例、所有其他類的樣例作為反例來訓練 N 個分類器。
MvM是每次將若幹個類作為正類,若幹個其他類作為反類。MvM的正、反類構造必須有特殊的設計,不能隨意選取。最常見的MvM技術為糾錯輸出碼(Error Correcting Output Codes, 簡稱ECOC)。
糾錯:在測試階段,ECOC編碼對分類的錯誤有一定的容忍和修正能力。- 一般來說,對同一個學習任務,ECOC編碼越長,糾錯能力越強。
- 對同等長度的編碼,理論上來說,任意兩個類別之間的編碼距離越遠,則糾錯能力越強。
3.6 類別不平衡問題前面幾個分類學習方法都有一個共同的假設:不同類別的訓練樣例數目相同。類別不平衡(class-imbalance):指分類任務中不同類別的訓練樣例數目差別很大的情況。
以線性分類器為例,在用 y = wTx + b對新樣本 x 進行分類時,實際上是在用預測出的 y 值與一個閾值進行比較,大於閾值時為正例,反之則為反例。1. 正、反例數目相同時的閾值是0.5,即
m+ 表示正例數目,m- 表示返利數目。 這就是類別不平衡學習的一個基本策略——再縮放(rescaling)。 當“訓練集是真實樣本總體的無偏采樣”這個假設不成立時,有以下方法:
| 方法 | 欠采樣(undersampling) | 過采樣(oversampling) | 閾值移動(threshold-moving) |
| 詳情 | 去除一些反例使得正、反例數目接近,然後進行學習 | 增加一些正例使得正、反例數目接近,然後再進行學習 | 直接基於原始訓練集進行學習,但在用訓練好的分類器進行預測時,將再縮放的公式嵌入到決策過程中 |
| 註 | 1. 時間開銷較小 2. 不能隨機丟棄反例,可能丟失重要信息。 3. 代表算法EasyEnsemble | 1.不能簡單的對初始正例樣本進行重復采樣,否則會招致嚴重的過擬合。 2. 代表算法SMOTE | 再縮放也是代價敏感學習的基礎。 |
《機器學習》(西瓜書)筆記(3)--線性模型