
Scrapy抓取動態網頁
動態網頁指幾種可能:
1)需要用戶交互,如常見的登錄操作;
2)網頁通過JS/ AJAX動態生成,如一個html裏有<div id="test"></div>,通過JS生成<div id="test"><span>aaa</span></div>;
3)點擊輸入關鍵字後進行查詢,而瀏覽器url地址不變
本篇文章不借助任何外部工具,實例操作如何以觀察網絡通信的方法解析動態網頁。
環境:Win10 , python2.7,scrapy 1.4.0,Chrome瀏覽器,Firefox瀏覽器
1、觀察是否為動態網頁
以華盛頓郵報為例,搜索關鍵詞 French ,搜索到的結果如下:

該網頁的url 為https://www.washingtonpost.com/newssearch/?datefilter=All%20Since%202005&query=French&sort=Relevance&utm_term=.3570cb8c6dcf
F12打開控制臺,在Element下找到想要獲得的搜索列表數據所在的section標簽”main-content”
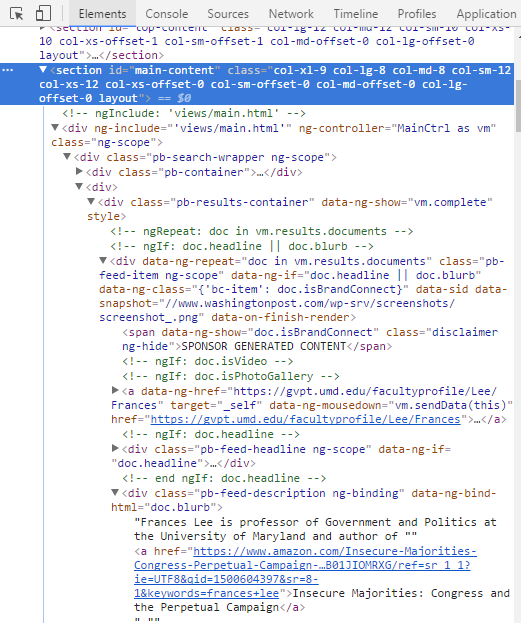
然後轉到Network的Doc標簽,重新加載當前網頁,在Name下點擊第一個文件,在右邊的Preview下尋找相應的section id 為 “main-content”的元素,發現沒有數據:
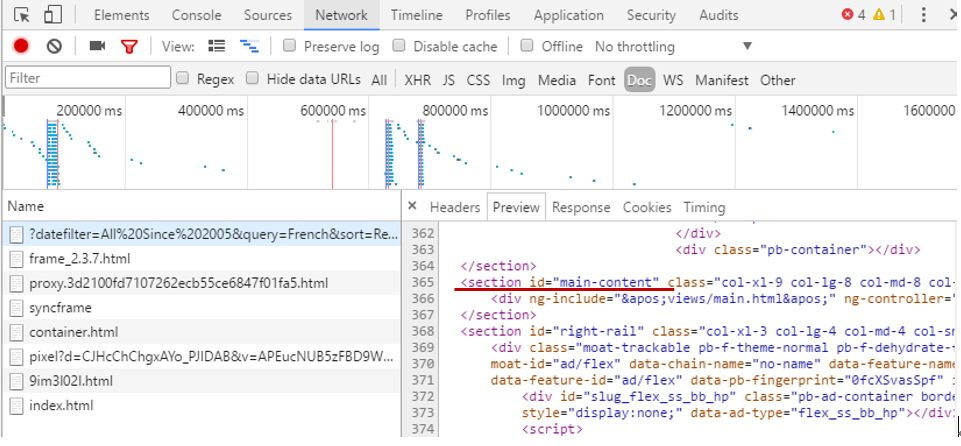
說明該內容為動態加載
2、獲得JS點擊動作發出的請求url
在JS標簽下尋找真正存放數據的網頁,點擊Name下的文件觀察右側的Preview有沒有數據,存放數據的網頁才是我們真正需要爬取的網頁:

一個小技巧:一般動態加載的數據都以json形式存儲,在Filter裏填json過濾,可以更加快速地尋找到想要的文件,但不是所有的網站都適用,還是需要在JS或XHR裏手動尋找所需文件。
復制當前文件的鏈接,得到一個很長的url:
https://sitesearchapp.washingtonpost.com/sitesearch-api/v2/search.json?count=20&datefilter=displaydatetime:%5B*+TO+NOW%2FDAY%2B1DAY%5D&facets.fields=%7B!ex%3Dinclude%7Dcontenttype,%7B!ex%3Dinclude%7Dname&highlight.fields=headline,body&highlight.on=true&highlight.snippets=1&query=French&sort=&callback=angular.callbacks._0
在瀏覽器中打開這個地址,發現這是一個json文件,但是該url太過冗長,我們可以根據需要適當地刪減一些參數,這些參數可以在Headers下得到:
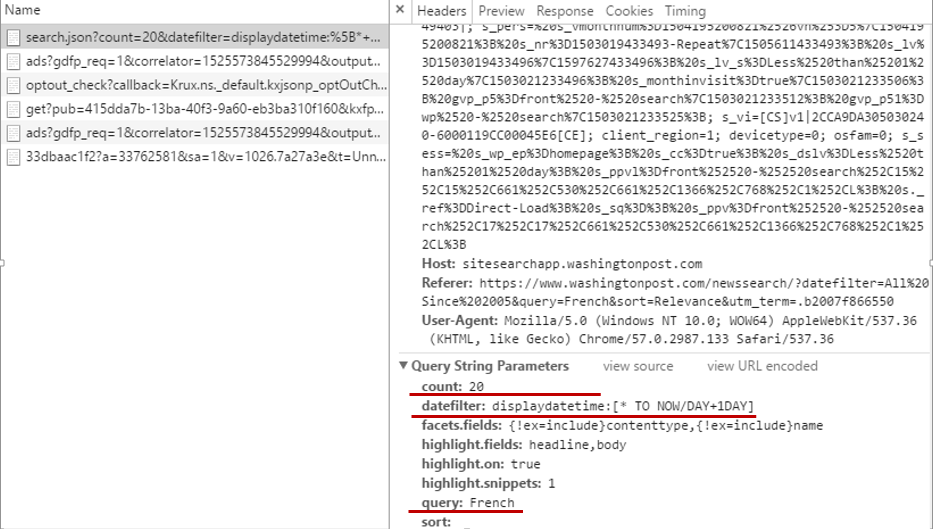
選擇保留count,datefilter,query三個參數,註意,必須保證刪減參數後的網頁與原url獲得的json數據一樣,精簡後的url為:
https://sitesearchapp.washingtonpost.com/sitesearch-api/v2/search.json?count=20&datefilter=displaydatetime:[*+TO+NOW%2FDAY%2B1DAY]&query=French
在火狐瀏覽器中打開該url(選擇火狐瀏覽器打開是因為json數據顯示友好),獲得的頁面如下:

3、提取json數據
根據以上json文件的結構,我們可以用json.loads函數進一步提取想要的數據:

4、翻頁機制
在網頁上進行操作,觀察url的參數變化規律:
第一頁:
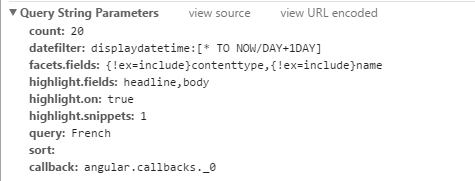
第二頁:

第三頁:
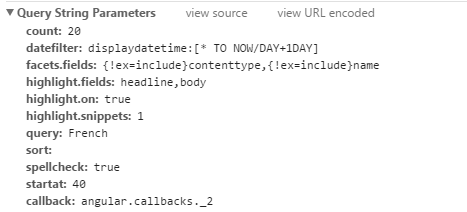
發現每一頁的url變化都是由多出來的startat這個參數導致的,解析下一頁只需要每次讓startat的值增加20,在url後添加該參數即可,如第二頁:
https://sitesearchapp.washingtonpost.com/sitesearch-api/v2/search.json?count=20&datefilter=displaydatetime:[*+TO+NOW%2FDAY%2B1DAY]&query=French&startat=20
最後根據新聞總數來計算出最後一頁的startat值即可
5、解析以表單形式提交參數的動態網頁
有的網站輸入關鍵字後進行查詢,而瀏覽器url地址不變,有可能是以表單形式提交Request參數。
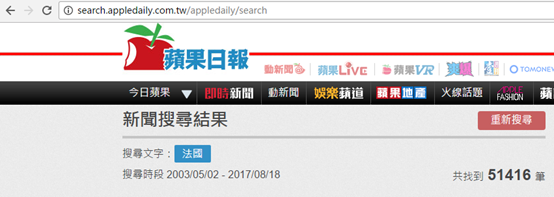
以蘋果日報為例,關鍵字搜索“法國”,url中卻沒有類似“?q=法國”的參數
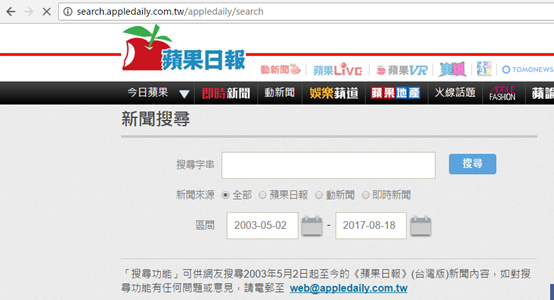
再次加載該url,發現其定位在一個單獨的搜索頁面:
分析搜索的結果,發現該參數是以表單的方式提交的:
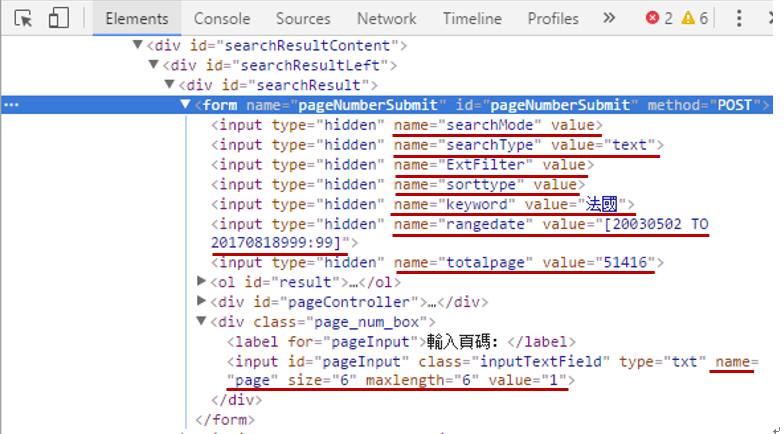
根據input 的參數填充FormRequest:
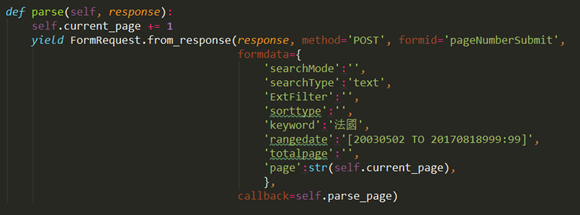
返回的response就可以用xpath正常解析網頁了:


Scrapy抓取動態網頁