
scrapy-splash抓取動態資料例子一
目前,為了加速頁面的載入速度,頁面的很多部分都是用JS生成的,而對於用scrapy爬蟲來說就是一個很大的問題,因為scrapy沒有JS engine,所以爬取的都是靜態頁面,對於JS生成的動態頁面都無法獲得
解決方案:
1、利用第三方中介軟體來提供JS渲染服務: scrapy-splash 等。
2、利用webkit或者基於webkit庫
Splash是一個Javascript渲染服務。它是一個實現了HTTP API的輕量級瀏覽器,Splash是用Python實現的,同時使用Twisted和QT。Twisted(QT)用來讓服務具有非同步處理能力,以發揮webkit的併發能力。
下面就來講一下如何使用scrapy-splash:
1、利用pip安裝scrapy-splash庫:
2、pip install scrapy-splash
scrapy-splash使用的是Splash HTTP API, 所以需要一個splash instance,一般採用docker執行splash,所以需要安裝docker,具體參見:http://www.cnblogs.com/shaosks/p/6932319.html
安裝好後執行docker。docker成功安裝後,有“Docker Quickstart Terminal”圖示,雙擊他啟動

5、拉取映象(pull the image):
$ docker pull scrapinghub/splash

這樣就正式啟動了。
6、用docker執行scrapinghub/splash服務:
$ docker run -p 8050:8050 scrapinghub/splash
首次啟動會比較慢,載入一些東西,多次啟動會出現以下資訊

這時要關閉當前視窗,然後在程序管理器裡面關閉一些程序重新開啟

重新開啟Docker Quickstart Terminal,然後輸入:docker run -p 8050:8050 scrapinghub/splash
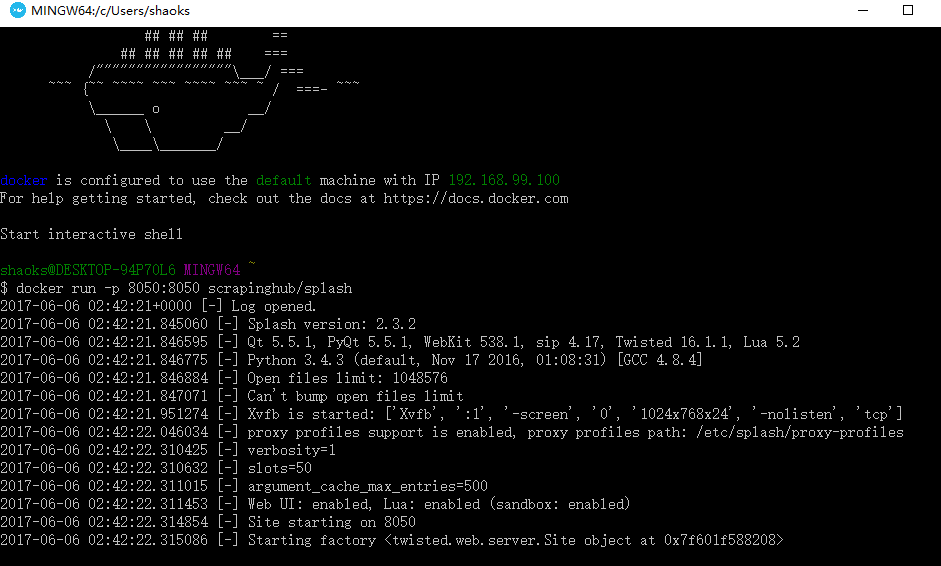
7、配置splash服務(以下操作全部在settings.py):
1)新增splash伺服器地址:

2)將splash middleware新增到DOWNLOADER_MIDDLEWARE中:

3)Enable SplashDeduplicateArgsMiddleware:

4)Set a custom DUPEFILTER_CLASS:

5)a custom cache storage backend:

8、正式抓取
如下圖:框住的資訊是要榨取的內容
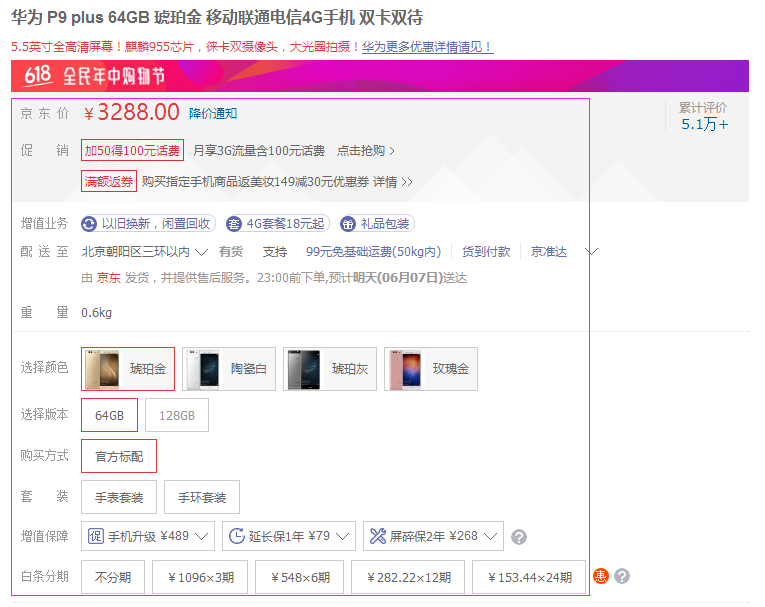
對應的html
1、京東價:

抓取程式碼:prices = site.xpath('//span[@class="p-price"]/span/text()')
2、促銷

抓取程式碼:cxs = site.xpath('//div[@class="J-prom-phone-jjg"]/em/text()')
3、增值業務

抓取程式碼:value_addeds =site.xpath('//ul[@class="choose-support lh"]/li/a/span/text()')
4、重量

抓取程式碼:quality = site.xpath('//div[@id="summary-weight"]/div[2]/text()')
5、選擇顏色

抓取程式碼:colors = site.xpath('//div[@id="choose-attr-1"]/div[2]/div/@title')
6、選擇版本

抓取程式碼:versions = site.xpath('//div[@id="choose-attr-2"]/div[2]/div/@data-value')
7、購買方式
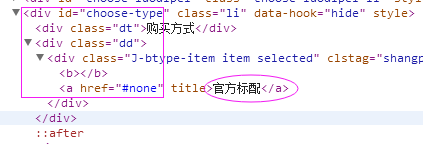
抓取程式碼:buy_style = site.xpath('//div[@id="choose-type"]/div[2]/div/a/text()')
8、套 裝

抓取程式碼:suits = site.xpath('//div[@id="choose-suits"]/div[2]/div/a/text()')
9、增值保障

抓取程式碼:vaps = site.xpath('//div[@class="yb-item-cat"]/div[1]/span[1]/text()')
10、白條分期

抓取程式碼:stagings = site.xpath('//div[@class="baitiao-list J-baitiao-list"]/div[@class="item"]/a/strong/text()')
9、執行splash服務
在抓取之前首先要啟動splash服務,命令:docker run -p 8050:8050 scrapinghub/splash,
點選“Docker Quickstart Terminal” 圖示

10、執行scrapy crawl scrapy_splash

11、抓取資料


12、完整原始碼
1、SplashSpider
# -*- coding: utf-8 -*- import scrapy from scrapy import Request from scrapy.spiders import Spider from scrapy_splash import SplashRequest from scrapy_splash import SplashMiddleware from scrapy.http import Request, HtmlResponse from scrapy.selector import Selector from scrapy_splash import SplashRequest from splash_test.items import SplashTestItem import sys reload(sys) sys.setdefaultencoding('utf-8') sys.stdout = open('output.txt', 'w') class SplashSpider(Spider): name = 'scrapy_splash' start_urls = [ 'https://item.jd.com/2600240.html' ] # request需要封裝成SplashRequest def start_requests(self): for url in self.start_urls: yield SplashRequest(url , self.parse , args={'wait': '0.5'} # ,endpoint='render.json' ) def parse(self, response): # 本文只抓取一個京東連結,此連結為京東商品頁面,價格引數是ajax生成的。會把頁面渲染後的html存在html.txt # 如果想一直抓取可以使用CrawlSpider,或者把下面的註釋去掉 site = Selector(response) it_list = [] it = SplashTestItem() #京東價 # prices = site.xpath('//span[@class="price J-p-2600240"]/text()') # it['price']= prices[0].extract() # print '京東價:'+ it['price'] prices = site.xpath('//span[@class="p-price"]/span/text()') it['price'] = prices[0].extract()+ prices[1].extract() print '京東價:' + it['price'] # 促 銷 cxs = site.xpath('//div[@class="J-prom-phone-jjg"]/em/text()') strcx = '' for cx in cxs: strcx += str(cx.extract())+' ' it['promotion'] = strcx print '促銷:%s '% strcx # 增值業務 value_addeds =site.xpath('//ul[@class="choose-support lh"]/li/a/span/text()') strValueAdd ='' for va in value_addeds: strValueAdd += str(va.extract())+' ' print '增值業務:%s ' % strValueAdd it['value_add'] = strValueAdd # 重量 quality = site.xpath('//div[@id="summary-weight"]/div[2]/text()') print '重量:%s ' % str(quality[0].extract()) it['quality']=quality[0].extract() #選擇顏色 colors = site.xpath('//div[@id="choose-attr-1"]/div[2]/div/@title') strcolor = '' for color in colors: strcolor += str(color.extract()) + ' ' print '選擇顏色:%s ' % strcolor it['color'] = strcolor # 選擇版本 versions = site.xpath('//div[@id="choose-attr-2"]/div[2]/div/@data-value') strversion = '' for ver in versions: strversion += str(ver.extract()) + ' ' print '選擇版本:%s ' % strversion it['version'] = strversion # 購買方式 buy_style = site.xpath('//div[@id="choose-type"]/div[2]/div/a/text()') print '購買方式:%s ' % str(buy_style[0].extract()) it['buy_style'] = buy_style[0].extract() # 套裝 suits = site.xpath('//div[@id="choose-suits"]/div[2]/div/a/text()') strsuit = '' for tz in suits: strsuit += str(tz.extract()) + ' ' print '套裝:%s ' % strsuit it['suit'] = strsuit # 增值保障 vaps = site.xpath('//div[@class="yb-item-cat"]/div[1]/span[1]/text()') strvaps = '' for vap in vaps: strvaps += str(vap.extract()) + ' ' print '增值保障:%s ' % strvaps it['value_add_protection'] = strvaps # 白條分期 stagings = site.xpath('//div[@class="baitiao-list J-baitiao-list"]/div[@class="item"]/a/strong/text()') strstaging = '' for st in stagings: ststr =str(st.extract()) strstaging += ststr.strip() + ' ' print '白天分期:%s ' % strstaging it['staging'] = strstaging it_list.append(it) return it_list
2、SplashTestItem
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class SplashTestItem(scrapy.Item): #單價 price = scrapy.Field() # description = Field() #促銷 promotion = scrapy.Field() #增值業務 value_add = scrapy.Field() #重量 quality = scrapy.Field() #選擇顏色 color = scrapy.Field() #選擇版本 version = scrapy.Field() #購買方式 buy_style=scrapy.Field() #套裝 suit =scrapy.Field() #增值保障 value_add_protection = scrapy.Field() #白天分期 staging = scrapy.Field() # post_view_count = scrapy.Field() # post_comment_count = scrapy.Field() # url = scrapy.Field()
3、SplashTestPipeline
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import codecs import json class SplashTestPipeline(object): def __init__(self): # self.file = open('data.json', 'wb') self.file = codecs.open( 'spider.txt', 'w', encoding='utf-8') # self.file = codecs.open( # 'spider.json', 'w', encoding='utf-8') def process_item(self, item, spider): line = json.dumps(dict(item), ensure_ascii=False) + "\n" self.file.write(line) return item def spider_closed(self, spider): self.file.close()
4、settings.py
# -*- coding: utf-8 -*- # Scrapy settings for splash_test project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html ITEM_PIPELINES = { 'splash_test.pipelines.SplashTestPipeline':300 } BOT_NAME = 'splash_test' SPIDER_MODULES = ['splash_test.spiders'] NEWSPIDER_MODULE = 'splash_test.spiders' SPLASH_URL = 'http://192.168.99.100:8050' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'splash_test (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, } SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100, } DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage' # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'splash_test.middlewares.SplashTestSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'splash_test.middlewares.MyCustomDownloaderMiddleware': 543, #} # Enable or disable extensions # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'splash_test.pipelines.SplashTestPipeline': 300, #} # Enable and configure the AutoThrottle extension (disabled by default) # See http://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
相關推薦
scrapy-splash抓取動態資料例子一
目前,為了加速頁面的載入速度,頁面的很多部分都是用JS生成的,而對於用scrapy爬蟲來說就是一個很大的問題,因為scrapy沒有JS engine,所以爬取的都是靜態頁面,對於JS生成的動態頁面都無法獲得 解決方案: 1、利用第三方中介軟體來提供JS渲染服務: scrapy-splash 等
scrapy實戰:scrapy-splash抓取動態資料
scrapy實戰:scrapy-splash抓取動態資料 docker安裝 拉取scrapinghub/splash映象 啟動Splash 安裝 scrapy-splash 新建taobao spider專案 settings.py
scrapy-splash抓取動態數據例子十一
tel ems 網站 tput findall spi 來源 標題 end 一、介紹 本例子用scrapy-splash抓取活動樹網站給定關鍵字抓取活動信息。 給定關鍵字:數字;融合;電視 抓取信息內如下: 1、資訊標題
scrapy-splash抓取動態數據例子八
ear .config war rep ont code port 動態數據 shm 一、介紹 本例子用scrapy-splash抓取界面網站給定關鍵字抓取咨詢信息。 給定關鍵字:個性化;融合;電視 抓取信息內如下: 1、資訊標題
Scrapy利用Splash抓取動態頁面
之前的例子,我爬取的都是些靜態頁面中的資訊,爬取容易。但是目前大多數網站都是動態的,動態頁面中的部分內容是瀏覽器執行頁面中的JavaScript指令碼動態生成的,爬取相對困難。 動態網頁一般兩種思路 ,一是找到api介面偽裝請求直接請求資料,另一種是沒有辦法模
python抓取動態資料 A股上市公司基本資訊
1.背景 之前寫的抓取A股所有上市公司資訊的小程式在上交所網站改版後,需要同步修改 pyton2.7.9 2.分析過程 以抓取宇通客車【600066】資訊為例 紅框中的內容是需要抓取的資訊,檢視網頁原始碼 可以看到公司資訊並沒有直接寫到html中,使用chrome “
Python爬蟲抓取動態資料
一個月前實習導師佈置任務說通過網路爬蟲獲取深圳市氣象局釋出的降雨資料,網頁如下: 心想,爬蟲不太難的,當年跟zjb爬煎蛋網無(mei)聊(zi)圖的時候,多麼清高。由於接受任務後的一個月考試加作業一大堆,導師也不催,自己也不急。 但是,導師等我一個月都得讓我來寫意味著這
Scrapy抓取動態網頁
都是 搜索 華盛頓 etime 觀察 review llb 得到 我們 動態網頁指幾種可能: 1)需要用戶交互,如常見的登錄操作; 2)網頁通過JS/ AJAX動態生成,如一個html裏有<div id="test"></div>,通過JS生成&l
scrapy利用scrapy-splash爬取JS動態生成的標籤
1 引言 scrapy處理爬取靜態頁面,可以說是很好的工具,但是隨著技術的發展,現在很多頁面都不再是靜態頁面了,都是通過AJAX非同步載入資料動態生成的,我們如何去解決問題呢?今天給大家介紹一種方法:scrapy-splash 2 準備工作 首先需要安裝一下幾個工具 (1)
Python網路爬蟲抓取動態網頁並將資料存入資料庫MYSQL
簡述 以下的程式碼是使用python實現的網路爬蟲,抓取動態網頁http://hb.qq.com/baoliao/。此網頁中的最新、精華下面的內容是由JavaScript動態生成的。審查網頁元素與網頁原始碼是不同。 本人對於Python學習建立了一個小小的學習圈子,為各位提供了
Python爬蟲scrapy框架爬取動態網站——scrapy與selenium結合爬取資料
scrapy框架只能爬取靜態網站。如需爬取動態網站,需要結合著selenium進行js的渲染,才能獲取到動態載入的資料。如何通過selenium請求url,而不再通過下載器Downloader去請求這個url?方法:在request物件通過中介軟體的時候,在中介軟體內部開始
利用scrapy-splash爬取JS生成的動態頁面
目前,為了加速頁面的載入速度,頁面的很多部分都是用JS生成的,而對於用scrapy爬蟲來說就是一個很大的問題,因為scrapy沒有JS engine,所以爬取的都是靜態頁面,對於JS生成的動態頁面都無法獲得。 解決方案: 利用第三方中介軟體來提供JS渲染服務: scrapy-splash 等。 利用webk
Scrapy筆記(12)- 抓取動態網站
前面我們介紹的都是去抓取靜態的網站頁面,也就是說我們開啟某個連結,它的內容全部呈現出來。但是如今的網際網路大部分的web頁面都是動態的,經常逛的網站例如京東、淘寶等,商品列表都是js,並有Ajax渲染,下載某個連結得到的頁面裡面含有非同步載入的內容,這樣再使用之前的方式我們根本獲取不到非同步載入的這些網頁內
抓取手機資料網路的網路包(一)——安裝adb,並pc連線手機
抓取手機資料網路的網路包。 前提 一臺root手機,且安裝“ROOT許可權管理”、安裝“terminal emulator”。 一臺windows系統的PC電腦。 在手機上的“ROOT許可權管理”裡面給“terminal emulator”分
python爬蟲之利用scrapy框架抓取新浪天氣資料
scrapy中文官方文件:點選開啟連結Scrapy是Python開發的一個快速、高層次的螢幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的資料。Scrapy用途廣泛,可以用於資料探勘、監測和自動化測試,Scrapy吸引人的地方在於它是一個框架,任何人都可以根據
使用Selenium抓取百度指數一
輸入 指數 _id orm end span try res () 抓百度指數的數據,比較簡單的演示:selenium+瀏覽器(我這是Firefox)的代碼。 代碼如下: from selenium import webdriver from selenium.webdri
夜神模擬器配置burpsuite抓取APP資料報文
設定夜神模擬器的代理 進入wifi連線選項 之後長按熱點,出現修改網路的彈窗 點選修改網路,勾選高階選項,將代理設為手動,代理伺服器主機名填寫電腦的ip,埠號填寫8888 點選儲存 設定Burpsuite代理 在夜神模擬器當中使用瀏覽器瀏覽該代理地
java webmagic 抓取靜態網頁資源,抓取動態網頁資源
webmagicJava爬蟲框架 fastjson 阿里巴巴提供的 json 轉為物件的快捷包,裡面有下載jar包的地址 抓取靜態網頁資源 。例項:抓取李開復部落格:標題,內容,釋出日期。 public class LiKaiFuBlogReading implements Pag
Charles小常識及抓取手機資料
一.Charles小常識 注意: (1)瀏覽網頁時花瓶儘量不要開啟,可能會出現網頁重置現象 (2)安裝Python包時,切記要將花瓶關閉,否則會報錯 1.花瓶的埠是8888 2. 可以改為0.0.0.0/0可以抓取所有IP下的所有埠 3.可以按照以下做
使用fiddler抓取app資料
本文簡單展示如何用Python抓取APP資料,以超級課程表樹洞為例: 首先:需要下載抓包神器:fiddler 直接百度下載,然後打來fiddler設定幾個選項: 選中"Decrpt HTTPS traffic", Fiddler就可以截獲HTTPS請