
CNN詳解
CNN詳解
版權聲明:本文為博主原創文章,轉載請指明轉載地址
http://www.cnblogs.com/fydeblog/p/7450413.html
前言
這篇博客主要就是卷積神經網絡(CNN)的歷史、模塊、特點和架構等等
1. CNN歷史
- CNN最早可以追溯到1968Hubel和Wiesel的論文,這篇論文講述貓和猴的視覺皮層含有對視野的小區域單獨反應的神經元,如果眼睛沒有移動,則視覺刺激影響單個神經元的視覺空間區域被稱為其感受野(Receptive Field)。相鄰細胞具有相似和重疊的感受野。感受野大小和位置在皮層之間系統地變化,形成完整的視覺空間圖。這個為CNN的局部感知奠定了一個基礎。
- 然後是1980年,神經感知機(neocognitron)的提出,標誌了第一個初始的卷積神經網絡的誕生,也是感受野概念在人工神經網絡領域的首次應用,神經認知機將一個視覺模式分解成許多子模式(特征),然後進入分層遞階式相連的特征平面進行處理。
- 在然後1988年,時不變神經網絡(Shift-invariant neural network)的提出,將卷積神經網絡的功能進行了一次提高,使其能夠在即使物體有位移或輕微變形的時候,也能完成識別。
- 卷積神經網絡的前饋架構在神經抽象金字塔(Neural abstraction pyramid)中被橫向和反饋連接擴展。所產生的復現卷積網絡允許靈活地並入情景信息以叠代地解決局部模糊。與以前的模型相反,產生了最高分辨率的圖像輸出。
- 最後,2005出現了一篇GPU實現CNN的paper,標誌了一種實現CNN更有效的方式,之後在2012年ImageNet大賽中CNN由於其高精確度脫穎而出,於是,深度學習正式進入人們的視野。
2 CNN基本模塊
CNN由輸入和輸出層以及多個隱藏層組成,隱藏層可分為卷積層,池化層、RELU層和全連通層。
2.1 輸入層
CNN的輸入一般是二維向量,可以有高度,比如,RGB圖像
2.2 卷積層
卷積層是CNN的核心,層的參數由一組可學習的濾波器(filter)或內核(kernels)組成,它們具有小的感受野,延伸到輸入容積的整個深度。 在前饋期間,每個濾波器對輸入進行卷積,計算濾波器和輸入之間的點積,並產生該濾波器的二維激活圖(輸入一般二維向量,但可能有高度(即RGB))。 簡單來說,卷積層是用來對輸入層進行卷積,提取更高層次的特征。
聯想理解:
- 可能上面的話語太拗口,這裏講一下卷積的作用,我最早接觸卷積是在信號與系統這門課上。在信號與系統中,輸入對一個系統的響應是等於輸入信號e(x)與系統函數h(x)進行卷積,h(x)可以看作一個濾波器,它會對輸入信號進行篩選,選擇和它類似的信號,其他則過濾掉,相信學過的人有這個體會哈!
- 我們還可以想想數字圖像處理(DIP)這門課,我們在提取圖像的邊緣特征時,用到的一個卷積核,名字叫sobel算子,它與圖像進行卷積,就可以得到邊緣,這個原因是有sobel算子與圖像邊緣的結構相似,所以才能提取出來,這個可能更容易理解卷積層的作用吧,但不同的是這裏的卷積層參數未知,需要學習才能得到。
2.3 池化層
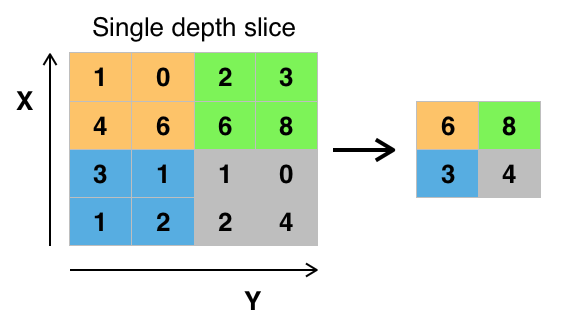
池化層又稱下采樣,它的作用是減小數據處理量同時保留有用信息,它是怎麽做到的呢?
答:通常池化層是每鄰域四個像素中的最大值變為一個像素(這就是下一講要降的max_pooling),為什麽可以這麽做呢?這是因為卷積已經提取出特征,相鄰區域的特征是類似,近乎不變,這是池化只是選出最能表征特征的像素,縮減了數據量,同時保留了特征,何樂而不為呢?池化層的作用可以描述為模糊圖像,丟掉了一些不是那麽重要的特征.
圖形描述:
2.4 RELU層
這個RELU我們之前講過,全名將修正線性單元,是神經元的激活函數,對輸入值x的作用是max(0,x),當然RELU只是一種選擇,還有選sigmiod等等
2.5 全連通層
這個層就是一個常規的神經網絡,它的作用是對經過多次卷積層和多次池化層所得出來的高級特征進行全連接(全連接就是常規神經網絡的性質),算出最後的預測值。
2.6 輸出層
輸出層就不用介紹了,就是對結果的預測值,一般會加一個softmax層。
3. CNN的特點
這裏主要討論CNN相比與傳統的神經網絡的不同之處,CNN主要有三大特色,分別是局部感知、權重共享和多卷積核
3.1 局部感知
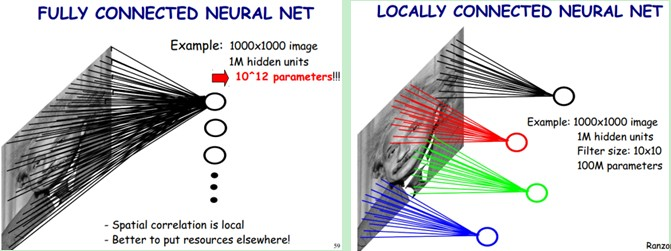
局部感知就是我們上面說的感受野,實際上就是卷積核和圖像卷積的時候,每次卷積核所覆蓋的像素只是一小部分,是局部特征,所以說是局部感知。CNN是一個從局部到整體的過程(局部到整體的實現是在全連通層),而傳統的神經網絡是整體的過程。
圖形描述:
3.2 權重共享
傳統的神經網絡的參數量是非常巨大的,比如1000X1000像素的圖片,映射到和自己相同的大小,需要(1000X1000)的平方,也就是10的12次方,參數量太大了,而CNN除全連接層外,卷積層的參數完全取決於濾波器的設置大小,比如10x10的濾波器,這樣只有100個參數,當然濾波器的個數不止一個,也就是下面要說的多卷積核。但與傳統的神經網絡相比,參數量小,計算量小。整個圖片共享一組濾波器的參數。
3.3 多卷積核
一種卷積核代表的是一種特征,為獲得更多不同的特征集合,卷積層會有多個卷積核,生成不同的特征,這也是為什麽卷積後的圖片的高,每一個圖片代表不同的特征。
4. CNN實現架構
這裏以LeNet-5(效果和paper)為例,一個典型的用來識別數字的卷積網絡,當年美國大多數銀行就是用它來識別支票上面的手寫數字的。能夠達到這種商用的地步,它的準確性可想而知。
LeNet-5主要有7層(不包括輸入和輸出),具體框架如圖
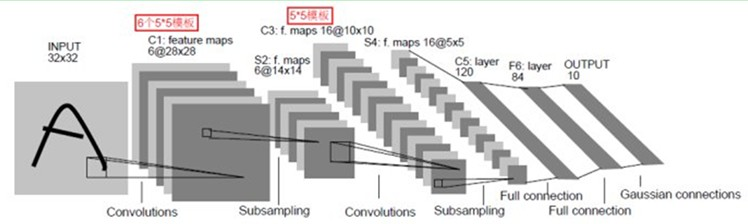
流程:輸入層——>第一層卷積層——>第一層池化層——>第二層卷積層——>第二層池化層——>三層全連通層——>輸出層
詳解:輸入是一個2維的圖片,大小32X32,經過第一層卷積層,得到了C1層的6個28X28的特征映射圖,6個說明了第一層卷積層用了6個卷積核。這裏卷積後大小變成28X28,這是因為卷積有兩種,一種有填充,卷積後與原圖像大小一樣,另一種不帶填充,卷積後結果與原圖像相比,小了一些。然後經過第一層池化層,28X28變成了14X14,一般是每鄰域四個像素中的最大值變為一個像素,相應圖片的長和寬各縮小兩倍。然後又經過一個卷積層,變成了C3層的16個10X10的特征映射圖,然後又經過一個池化層,得到S4層的16個5X5的特征映射,然後將這16個5X5的特征映射送到3層的常規神經網絡,得出最後的結果。
總結:我們可以這樣想,前面的卷積層和池化層是為了提取輸入的高級特征,送到全連通層的輸入,然後訓練出最後的結果。
5.dropout
dropout是一種正則化的方法,應用在CNN中,主要解決CNN過擬合的問題。
怎麽理解這個東西呢,首先我們要知道為什麽過擬合?這是因為神經網絡的神經元過多,參數過多,導致訓練集擬合得太好了,為此,我們想dropout(丟掉)一些神經元,讓它不產生影響。
具體做法:在每個隱藏層的輸入進行一個概率判決,比如我們設置概率為0.5(通常命名為keep_drop),根據0.5,我們生成一個跟隱藏層神經元個數的向量,true:false的比例是1:1(因為keep_drop=0.5),與隱藏層的輸入進行相乘,那麽會有一半隱藏層的神經元被丟掉,不起作用,整個網絡變得簡單了,就會從過擬合過渡到just right 。這是組合派的說法,andrew也是這麽講的,文末鏈接中還有一派噪聲派的說法,也很有意思,可以看看!
6.結尾
CNN初探到此結束,當然,這是一個非常強大的算法,還需細細思考,體會其中更精華的東西!最後,由於筆者能力有限,如果錯誤,還請不吝指教!
在這裏說一句,吳恩達的deeplearning.ai正式在網易雲上線,全免費,非常值得觀看哦!點開鏈接即可觀看!
參考
[1] https://en.wikipedia.org/wiki/Convolutional_neural_network
[2] http://blog.csdn.net/zouxy09/article/details/8781543
[3] http://dataunion.org/11692.html
[4] http://blog.csdn.net/stdcoutzyx/article/details/49022443
CNN詳解