【目標檢測】【語義分割】—Mask-R-CNN詳解
一、mask rcnn簡介
論文連結:論文連結
論文程式碼:Facebook程式碼連結;Tensorflow版本程式碼連結; Keras and TensorFlow版本程式碼連結;MxNet版本程式碼連結
mask rcnn是基於faster rcnn架構提出的卷積網路,一舉完成了object instance segmentation. 該方法在進行目標檢測的同時完成了高質量的語義分割。文章的主要思路是把原有的Faster-RCNN進行擴充套件,新增一個分支使用現有的檢測對目標進行並行預測。同時,將 Roi Pooling 層替換成了 RoiAlign;網路結構比較容易實現和訓練,速度為5fps,可以很方便的應用到其他的領域,像目標檢測,分割,和人物關鍵點檢測等。並且比著現有的演算法效果都要好,在後面的實驗結果部分有展示出來。
二、Mask R-CNN是什麼,可以做哪些任務?
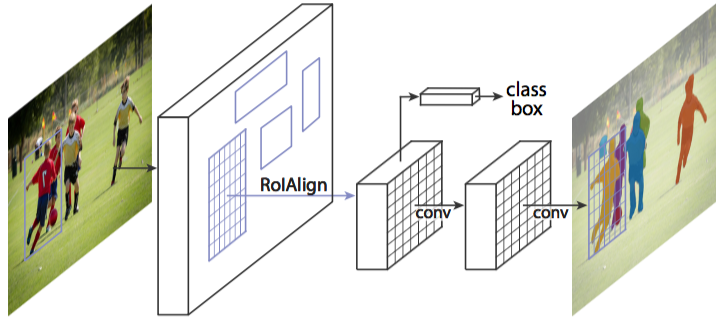
Mask R-CNN是一個例項分割(Instance segmentation)演算法,可以用來做“目標檢測”、“目標例項分割”、“目標關鍵點檢測”。
例項分割(Instance segmentation)和語義分割(Semantic segmentation)的區別與聯絡
聯絡:語義分割和例項分割都是目標分割中的兩個小的領域,都是用來對輸入的圖片做分割處理;
區別:

1. 通常意義上的目標分割指的是語義分割,語義分割已經有很長的發展歷史,已經取得了很好地進展,目前有很多的學者在做這方面的研究;然而例項分割是一個從目標分割領域獨立出來的一個小領域,是最近幾年才發展起來的,與前者相比,後者更加複雜,當前研究的學者也比較少,是一個有研究空間的熱門領域,如圖1所示,這是一個正在探索中的領域;
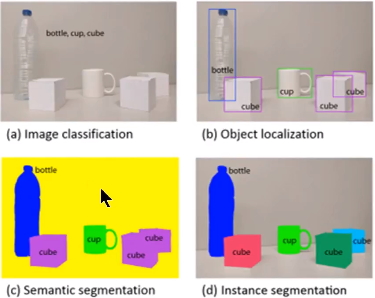
2. 觀察圖3中的c和d圖,c圖是對a圖進行語義分割的結果,d圖是對a圖進行例項分割的結果。兩者最大的區別就是圖中的"cube物件",在語義分割中給了它們相同的顏色,而在例項分割中卻給了不同的顏色。即例項分割需要在語義分割的基礎上對同類物體進行更精細的分割。
三、Mask R-CNN: overview

從整體構架可以知道,Mask R-CNN主要的貢獻在於如下:
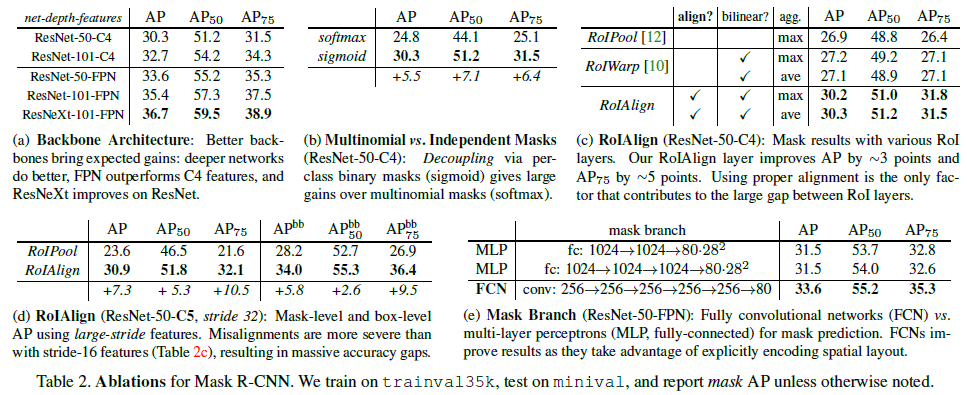
1. 強化的基礎網路,用ResNet-101+FPN作為特徵提取網路,達到 state-of-the-art 的效果。
2. ROIAlign解決Misalignment 的問題
3. 增加了
本文業主要是針對這幾個問題來解析Mask-R-CNN。
四、細節描述
1. Head Architecture
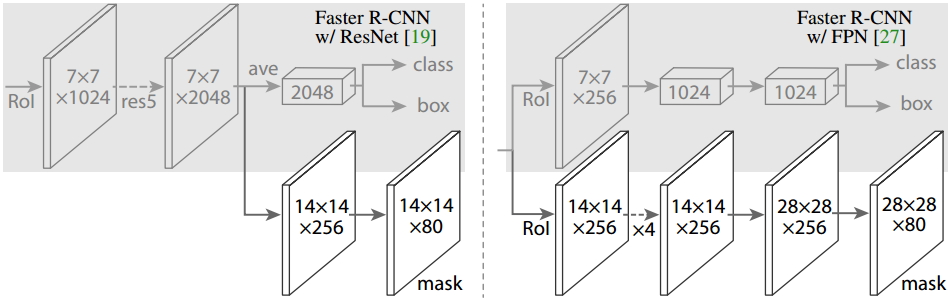
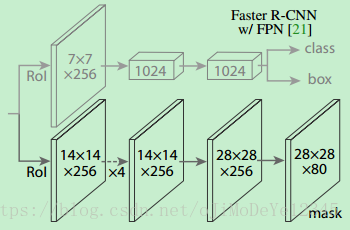
如上圖所示,為了產生對應的Mask,文中提出了兩種架構,即左邊的Faster R-CNN/ResNet和右邊的Faster R-CNN/FPN。對於左邊的架構,我們的backbone使用的是預訓練好的ResNet,使用了ResNet倒數第4層的網路。輸入的ROI首先獲得7x7x1024的ROI feature,然後將其升維到2048個通道(這裡修改了原始的ResNet網路架構),然後有兩個分支,上面的分支負責分類和迴歸,下面的分支負責生成對應的mask。由於前面進行了多次卷積和池化,減小了對應的解析度,mask分支開始利用反捲積進行解析度的提升,同時減少通道的個數,變為14x14x256,最後輸出了14x14x80的mask模板。而右邊使用到的backbone是FPN網路,這是一個新的網路,通過輸入單一尺度的圖片,最後可以對應的特徵金字塔,如果想要了解它的細節,請參考我前邊的部落格。得到證實的是,該網路可以在一定程度上面提高檢測的精度,當前很多的方法都用到了它。由於FPN網路已經包含了res5,可以更加高效的使用特徵,因此這裡使用了較少的filters。該架構也分為兩個分支,作用於前者相同,但是分類分支和mask分支和前者相比有很大的區別。可能是因為FPN網路可以在不同尺度的特徵上面獲得許多有用資訊,因此分類時使用了更少的濾波器。而mask分支中進行了多次卷積操作,首先將ROI變化為14x14x256的feature,然後進行了5次相同的操作,然後進行反捲積操作,最後輸出28x28x80的mask。即輸出了更大的mask,與前者相比可以獲得更細緻的mask。

如上圖所示,影象中紅色的BB表示檢測到的目標,我們可以用肉眼可以觀察到檢測結果並不是很好,即整個BB稍微偏右,左邊的一部分畫素並沒有包括在BB之內,但是右邊顯示的最終結果卻很完美。
1.2 RoIAlign詳解
ROI Align 是在Mask-RCNN論文裡提出的一種新的區域特徵聚集方式, 很好地解決了Faster-R-CNN中ROI Pooling操作時兩次量化造成的區域不匹配(mis-alignment)的問題。實驗顯示,在目標檢測時將ROI Pooling替換為ROI Align 可以提升檢測模型的準確性。
1. ROI Pooling 的侷限性分析
在常見的兩級檢測框架(比如Fast-RCNN,Faster-RCNN,RFCN)中,ROI Pooling 的作用是根據預選框的位置座標在特徵圖中將相應區域池化為固定尺寸的特徵圖,以便進行後續的分類和包圍框迴歸操作。由於預選框的位置通常是由模型迴歸得到的,一般來講是浮點數,而池化後的特徵圖要求尺寸固定。故ROI Pooling這一操作存在兩次量化的過程。
- 將候選框邊界量化為整數點座標值。
- 將量化後的邊界區域平均分割成 k x k 個單元(bin),對每一個單元的邊界進行量化。
事實上,經過上述兩次量化,此時的候選框已經和最開始迴歸出來的位置有一定的偏差,這個偏差會影響檢測或者分割的準確度。在論文裡,作者把它總結為“不匹配問題(misalignment)。
下面我們用直觀的例子具體分析一下上述區域不匹配問題。如 圖1 所示,這是一個Faster-RCNN檢測框架。輸入一張800*800的圖片,圖片上有一個665*665的包圍框(框著一隻狗)。圖片經過主幹網路提取特徵後,特徵圖縮放步長(stride)為32。因此,影象和包圍框的邊長都是輸入時的1/32。800正好可以被32整除變為25。但665除以32以後得到20.78,帶有小數,於是ROI Pooling 直接將它量化成20。接下來需要把框內的特徵池化7*7的大小,因此將上述包圍框平均分割成7*7個矩形區域。顯然,每個矩形區域的邊長為2.86,又含有小數。於是ROI Pooling 再次把它量化到2。經過這兩次量化,候選區域已經出現了較明顯的偏差(如圖中綠色部分所示)。更重要的是,該層特徵圖上0.1個畫素的偏差,縮放到原圖就是3.2個畫素。那麼0.8的偏差,在原圖上就是接近30個畫素點的差別,這一差別不容小覷。
2. ROI Align 的主要思想和具體方法
為了解決ROI Pooling的上述缺點,作者提出了ROI Align這一改進的方法(如圖2)。ROI Align的思路很簡單:取消量化操作,使用雙線性內插的方法獲得座標為浮點數的畫素點上的影象數值,從而將整個特徵聚集過程轉化為一個連續的操作,。值得注意的是,在具體的演算法操作上,ROI Align並不是簡單地補充出候選區域邊界上的座標點,然後將這些座標點進行池化,而是重新設計了一套比較優雅的流程,如 圖3 所示:
- 遍歷每一個候選區域,保持浮點數邊界不做量化。
- 將候選區域分割成k x k個單元,每個單元的邊界也不做量化。
- 在每個單元中計算固定四個座標位置,用雙線性內插的方法計算出這四個位置的值,然後進行最大池化操作。
這裡對上述步驟的第三點作一些說明:這個固定位置是指在每一個矩形單元(bin)中按照固定規則確定的位置。比如,如果取樣點數是1,那麼就是這個單元的中心點。如果取樣點數是4,那麼就是把這個單元平均分割成四個小方塊以後它們分別的中心點。顯然這些取樣點的座標通常是浮點數,所以需要使用插值的方法得到它的畫素值。在相關實驗中,作者發現將取樣點設為4會獲得最佳效能,甚至直接設為1在效能上也相差無幾。事實上,ROI Align 在遍歷取樣點的數量上沒有ROIPooling那麼多,但卻可以獲得更好的效能,這主要歸功於解決了misalignment的問題。值得一提的是,我在實驗時發現,ROI Align在VOC2007資料集上的提升效果並不如在COCO上明顯。經過分析,造成這種區別的原因是COCO上小目標的數量更多,而小目標受misalignment問題的影響更大(比如,同樣是0.5個畫素點的偏差,對於較大的目標而言顯得微不足道,但是對於小目標,誤差的影響就要高很多)。
3. ROI Align 的反向傳播
常規的ROI Pooling的反向傳播公式如下:
這裡,xi代表池化前特徵圖上的畫素點;yrj代表池化後的第r個候選區域的第j個點;i*(r,j)代表點yrj畫素值的來源(最大池化的時候選出的最大畫素值所在點的座標)。由上式可以看出,只有當池化後某一個點的畫素值在池化過程中採用了當前點Xi的畫素值(即滿足i=i*(r,j)),才在xi處回傳梯度。
類比於ROIPooling,ROIAlign的反向傳播需要作出稍許修改:首先,在ROIAlign中,xi*(r,j)是一個浮點數的座標位置(前向傳播時計算出來的取樣點),在池化前的特徵圖中,每一個與 xi*(r,j) 橫縱座標均小於1的點都應該接受與此對應的點yrj回傳的梯度,故ROI Align 的反向傳播公式如下:
上式中,d(.)表示兩點之間的距離,Δh和Δw表示 xi 與 xi*(r,j) 橫縱座標的差值,這裡作為雙線性內插的係數乘在原始的梯度上。
1.3 Loss 函式
訓練時,對每個取樣的 RoI 的 multi-task loss 為:
L=Lcls+Lbox+LmaskL=Lcls+Lbox+Lmask
- LclsLcls - 分類 loss
- LboxLbox - bounding-box 迴歸 loss
- LmaskLmask - mask 分割 loss
mask 網路分支採用 FCN 對每個 RoI 的分割輸出維數為 Km2Km2,即 KK 個類別的 m×mm×m 的二值 mask. 採用畫素級 Sigmoid,定義 LmaskLmask 為平均二值交叉熵損失函式(average binary cross-entropy loss). 一個 RoI 僅與 ground-truth 類別 kk 相關,LmaskLmask 只與第 kk 個 mask 相關,不受其它的 mask 輸出的影響.
LmaskLmask 使得網路能夠輸出每一類的 mask,且不會有不同類別 mask 間的競爭. 分類網路分支預測 object 類別標籤,以選擇輸出 mask,解耦了 mask 和 class 預測間的關係.
傳統 FCNs 採用 per-pixel 的 softmax 和 multinomial cross-entropy loss,會造成不同類別的 mask 間的相互影響;
Lmask 採用 per-pixel sigmoid 和 binary loss,避免了不同類別的 mask 間的影響. 有效的提升了 instance segmentation 效果.
五、對比實驗效果
另外,作者給出了很多實驗分割效果,就不都列了,只貼一張 和 FCIS 的對比圖(FCIS 出現了Overlap 的問題)

六、Mask-RCNN 擴充套件
1、人體姿態估計 Human Pose Estimation
說明 Mask R-CNN 的擴充套件性.
將 keypoint 的位置表示為 one-shot mask,採用 Mask R-CNN 來預測 KK 個 masks,每個 mask 分別對應一個 keypoint.
對於一個例項的 KK 個 keypoints 中的每一個,訓練目標是得到 one-hot m×mm×m 的二值mask,其中只有一種畫素被標記為前景,其它為背景.
訓練時,對於每個可見的 groundtruth keypoint,最小化 m2m2 -way softmax 輸出的 cross-entropy loss(檢測單個 keypoint). 這裡類似與 instance segmentation,KK 個 keypoints 也是被獨立處理的.
基於 ResNet-FPN, keypoint 的 head 網路結構類似於 Figure3(右),如下:
主要由 8 個 3×33×3 512-d 卷積層,其後接 1 個 deconv 層和 1 個 2×2× bilinear upscaling,最終輸出一個解析度為 56×5656×56 的特徵圖.
Mask R-CNN 發現,關鍵點定位的精確度需要相對高的解析度輸出.
訓練資料集 COCO trainval 35k 標註的 keypoints 資料
訓練是影象的尺度隨機的從 [640, 800] 中取樣;
測試時影象採用單一尺度 800 畫素;
訓練 90k 次迭代, learning_rate=0.02,在 60k 和 80k 次迭代時降低 10 倍;
NMS 處理 bounding-box 的閾值 threshold=0.5.