
例項分割模型Mask R-CNN詳解:從R-CNN,Fast R-CNN,Faster R-CNN再到Mask R-CNN
Mask R-CNN是ICCV 2017的best paper,彰顯了機器學習計算機視覺領域在2017年的最新成果。在機器學習2017年的最新發展中,單任務的網路結構已經逐漸不再引人矚目,取而代之的是整合,複雜,一石多鳥的多工網路模型。Mask R-CNN就是典型的代表。本篇大作的一作是何凱明,在該篇論文發表的時候,何凱明已經去了FaceBook。我們先來看一下,Mask R-CNN取得了何等的成果。
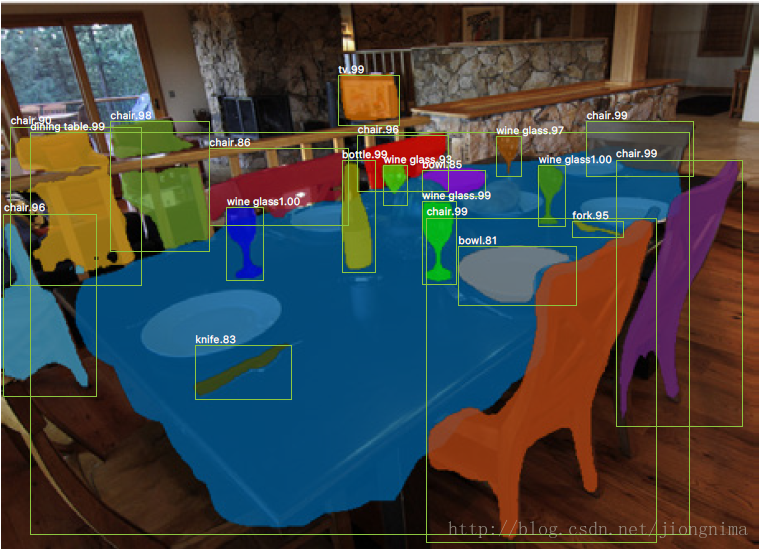

大家可以看到,在例項分割Mask R-CNN框架中,還是主要完成了三件事情:
1) 目標檢測,直接在結果圖上繪製了目標框(bounding box)。
2) 目標分類,對於每一個目標,需要找到對應的類別(class),區分到底是人,是車,還是其他類別。
3) 畫素級目標分割,在每個目標中,需要在畫素層面區分,什麼是前景,什麼是背景。
可是,在解析Mask R-CNN之前,筆者不得不告訴大家一個事實,Mask R-CNN是繼承於Faster R-CNN (2016)的,Mask R-CNN只是在Faster R-CNN上面加了一個Mask Prediction Branch (Mask 預測分支),並且改良了ROI Pooling,提出了ROI Align。從統計資料來看,"Faster R-CNN"在Mask R-CNN論文的前三章中出現了二十餘次,因此,如果不瞭解Ross Girshick和何凱明之前的工作,是很難弄懂Mask R-CNN的。所以,筆者在解析Mask R-CNN之前,先給大家分析一下Faster R-CNN。
在給大家解析Faster R-CNN之前,筆者又要告訴大家,Faster R-CNN是繼承於Fast R-CNN (2015),Fast R-CNN繼承於R-CNN (2014)。因此,索性破釜沉舟,在本篇博文中,筆者就按照R-CNN, Fast R-CNN,Faster R-CNN再到Mask R-CNN的發展順序全部解析。
首先時間回到了2014年,在2014年,正是深度學習如火如荼的發展的第三年。在CVPR 2014年中Ross Girshick提出的R-CNN中,使用到了卷積神經網路來進行目標檢測。下面筆者就來概述一下R-CNN是如何採用卷積神經網路進行目標檢測的工作。
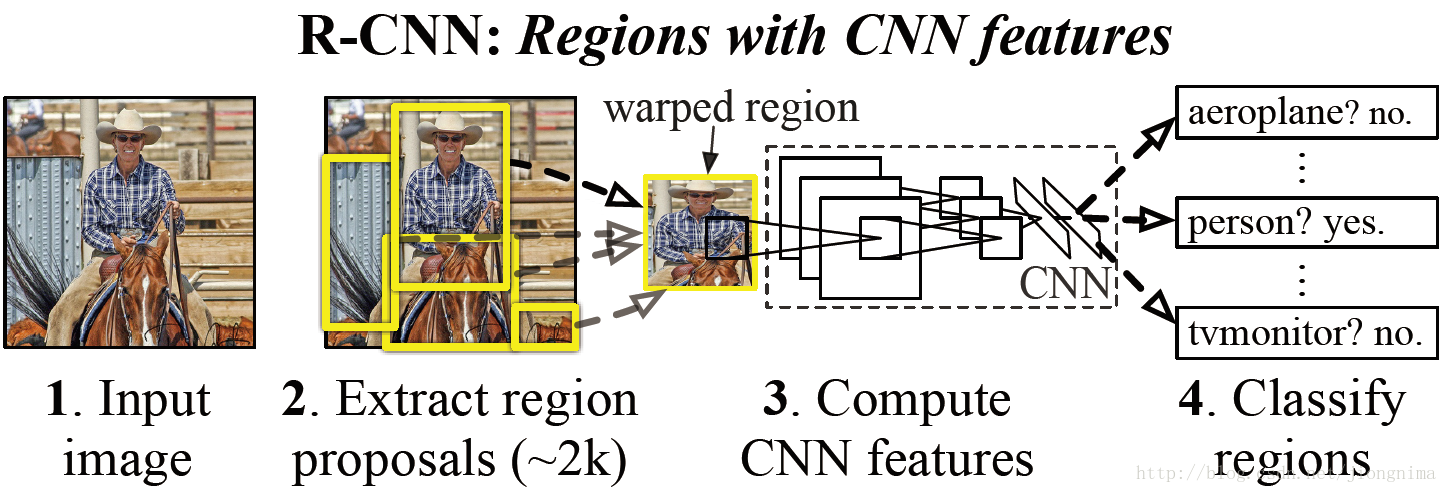
首先模型輸入為一張圖片,然後在圖片上提出了約2000個待檢測區域,然後這2000個待檢測區域一個一個地
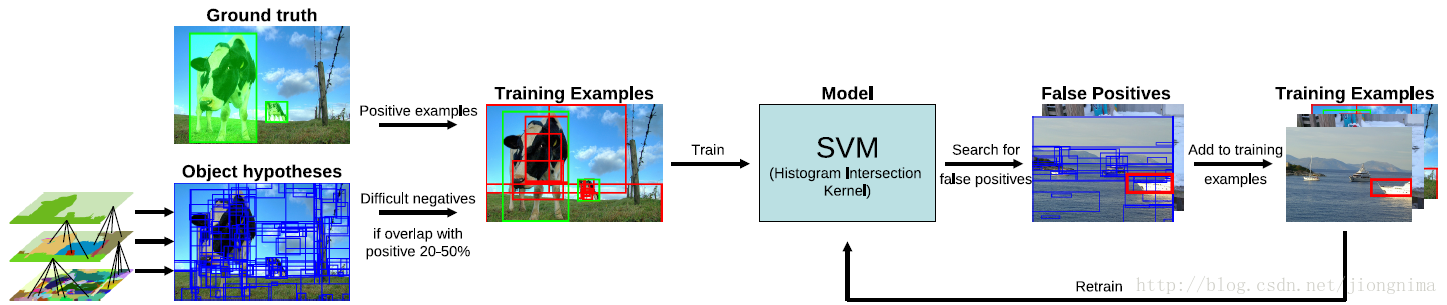
首先在第一步提取2000個待檢測區域的時候,是通過一個2012年提出的方法,叫做selective search。簡單來說就是通過一些傳統影象處理方法將影象分成若干塊,然後通過一個SVM將屬於同一目標的若干塊拿出來。selective search的核心是一個SVM,架構如下所示:
然後在第二步進行特徵提取的時候,Ross直接藉助了當時深度學習的最新成果AlexNet (2012)。那麼,該網路是如何訓練的呢?是直接在ImageNet上面訓練的,也就是說,使用影象分類資料集訓練了一個僅僅用於提取特徵的網路。
在第三步進行對目標的時候,使用了一個支援向量機(SVM),在訓練這個支援向量機的時候,結合目標的標籤(類別)與包圍框的大小進行訓練,因此,該支援向量機也是被單獨訓練的。
在2014年R-CNN橫空出世的時候,顛覆了以往的目標檢測方案,精度大大提升。對於R-CNN的貢獻,可以主要分為兩個方面:
1) 使用了卷積神經網路進行特徵提取。
2) 使用bounding box regression進行目標包圍框的修正。
但是,我們來看一下,R-CNN有什麼問題:
1) 耗時的selective search,對一幀影象,需要花費2s。
2) 耗時的序列式CNN前向傳播,對於每一個RoI,都需要經過一個AlexNet提特徵,為所有的RoI提特徵大約花費47s。
3) 三個模組是分別訓練的,並且在訓練的時候,對於儲存空間的消耗很大。
那麼,面對這種情勢,Ross在2015年提出的Fast R-CNN進行了改進,下面我們來概述一下Fast R-CNN的解決方案:
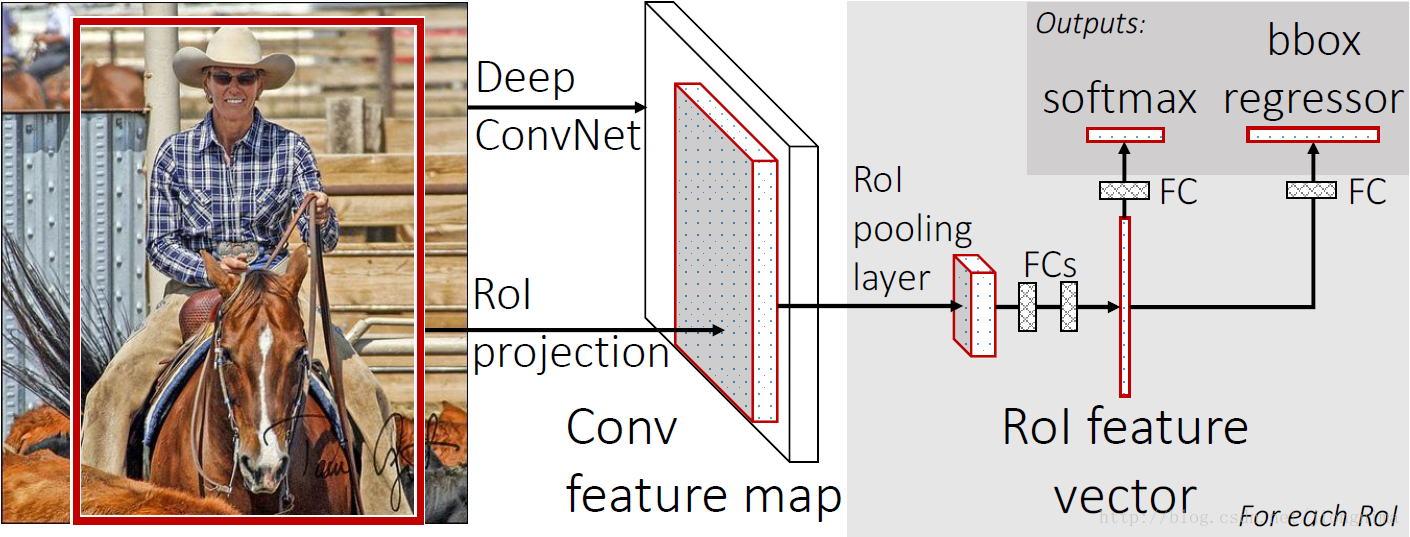
首先還是採用selective search提取2000個候選框,然後,使用一個神經網路對全圖進行特徵提取。接著,使用一個RoI Pooling Layer在全圖特徵上摘取每一個RoI對應的特徵,再通過全連線層(FC Layer)進行分類與包圍框的修正。Fast R-CNN的貢獻可以主要分為兩個方面:
1) 取代R-CNN的序列特徵提取方式,直接採用一個神經網路對全圖提取特徵(這也是為什麼需要RoI Pooling的原因)。
2) 除了selective search,其他部分都可以合在一起訓練。
可是,Fast R-CNN也有缺點,體現在耗時的selective search還是依舊存在。那麼,如何改良這個缺陷呢?發表於2016年的Faster R-CNN進行了如下創新:
取代selective search,直接通過一個Region Proposal Network (RPN)生成待檢測區域,這麼做,在生成RoI區域的時候,時間也就從2s縮減到了10ms。我們來看一下Faster R-CNN是怎麼做的。
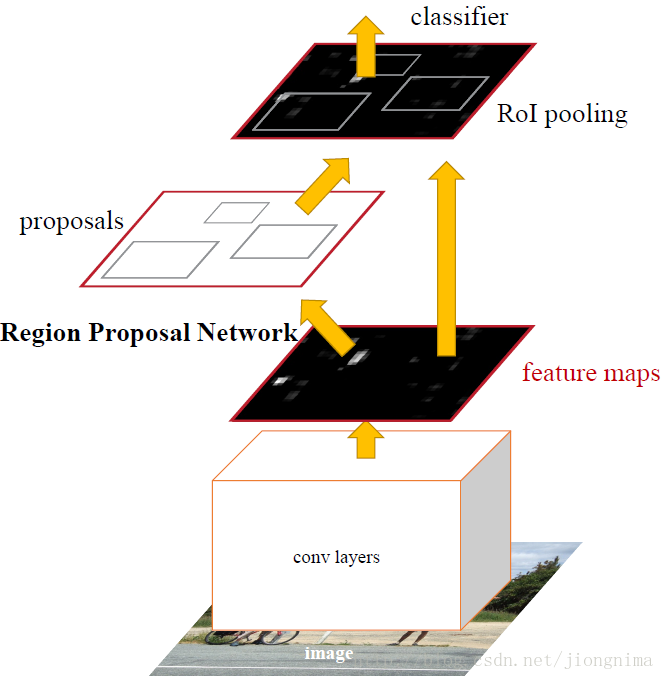
首先使用共享的卷積層為全圖提取特徵,然後將得到的feature maps送入RPN,RPN生成待檢測框(指定RoI的位置)並對RoI的包圍框進行第一次修正。之後就是Fast R-CNN的架構了,RoI Pooling Layer根據RPN的輸出在feature map上面選取每個RoI對應的特徵,並將維度置為定值。最後,使用全連線層(FC Layer)對框進行分類,並且進行目標包圍框的第二次修正。尤其注意的是,Faster R-CNN真正實現了端到端的訓練(end-to-end training)。
要理解Mask R-CNN,只有先理解Faster R-CNN。因此,筆者根據Faster R-CNN的架構(Faster R-CNN的ZF model的train.prototxt),畫了一個結構圖,如下所示:
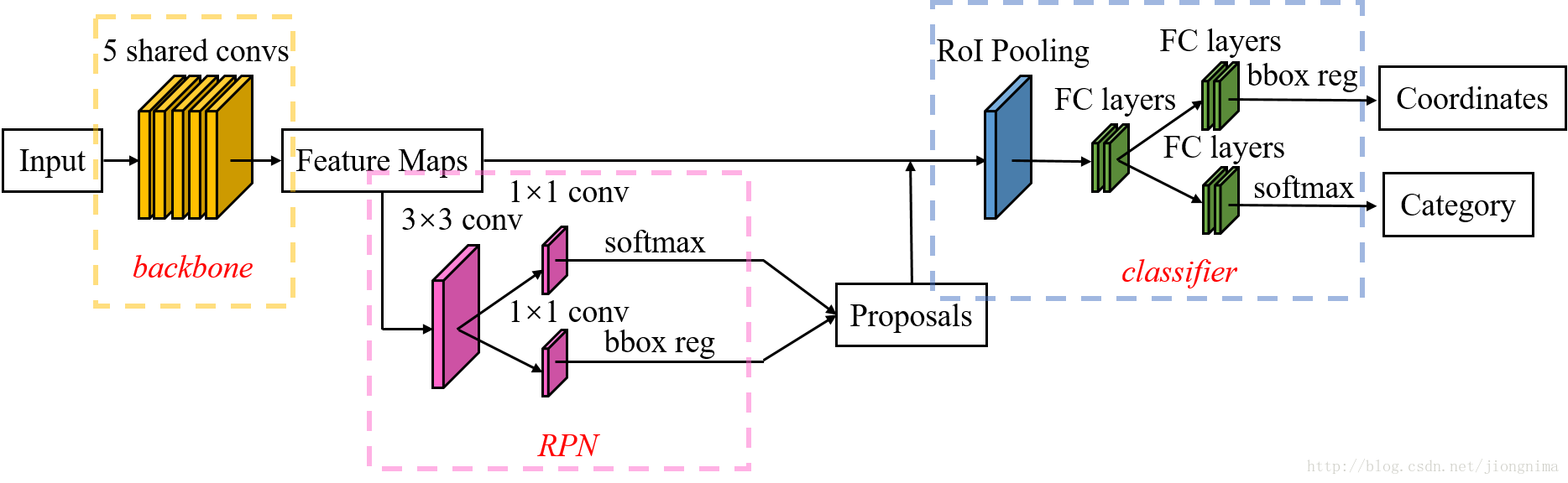
如上圖所示,Faster R-CNN的結構主要分為三大部分,第一部分是共享的卷積層-backbone,第二部分是候選區域生成網路-RPN,第三部分是對候選區域進行分類的網路-classifier。其中,RPN與classifier部分均對目標框有修正。classifier部分是原原本本繼承的Fast R-CNN結構。我們下面來簡單看看Faster R-CNN的各個模組。
首先來看看RPN的工作原理:
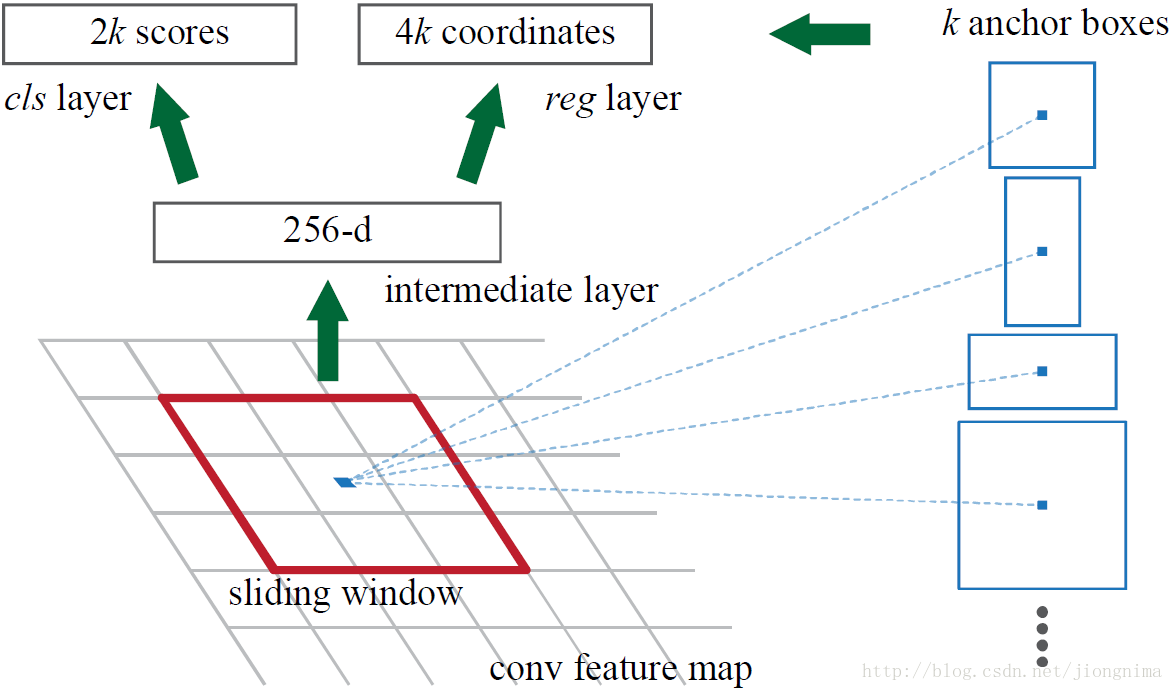
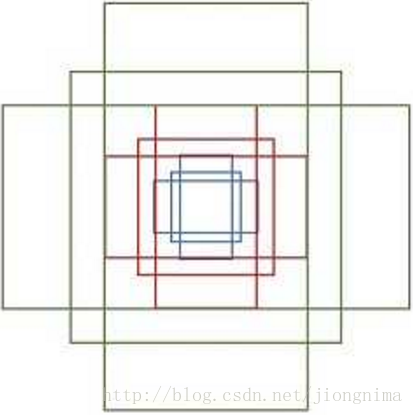
簡單地說,RPN依靠一個在共享特徵圖上滑動的視窗,為每個位置生成9種預先設定好長寬比與面積的目標框(文中叫做anchor)。這9種初始anchor包含三種面積(128×128,256×256,512×512),每種面積又包含三種長寬比(1:1,1:2,2:1)。示意圖如下所示:
由於共享特徵圖的大小約為40×60,RPN生成的初始anchor的總數約為20000個(40×60×9)。對於生成的anchor,RPN要做的事情有兩個,第一個是判斷anchor到底是前景還是背景,意思就是判斷這個anchor到底有沒有覆蓋目標,第二個是為屬於前景的anchor進行第一次座標修正。對於前一個問題,Faster R-CNN的做法是使用SoftmaxLoss直接訓練,在訓練的時候排除掉了超越影象邊界的anchor;對於後一個問題,採用SmoothL1Loss進行訓練。那麼,RPN怎麼實現呢?這個問題通過RPN的本質很好求解,RPN的本質是一個樹狀結構,樹幹是一個3×3的卷積層,樹枝是兩個1×1的卷積層,第一個1×1的卷積層解決了前後景的輸出,第二個1×1的卷積層解決了邊框修正的輸出。來看看在程式碼中是怎麼做的:


從如上程式碼中可以看到,對於RPN輸出的特徵圖中的每一個點,一個1×1的卷積層輸出了18個值,因為是每一個點對應9個anchor,每個anchor有一個前景分數和一個背景分數,所以9×2=18。另一個1×1的卷積層輸出了36個值,因為是每一個點對應9個anchor,每個anchor對應了4個修正座標的值,所以9×4=36。那麼,要得到這些值,RPN網路需要訓練。在訓練的時候,就需要對應的標籤。那麼,如何判定一個anchor是前景還是背景呢?文中做出瞭如下定義:如果一個anchor與ground truth的IoU在0.7以上,那這個anchor就算前景(positive)。類似地,如果這個anchor與ground truth的IoU在0.3以下,那麼這個anchor就算背景(negative)。在作者進行RPN網路訓練的時候,只使用了上述兩類anchor,與ground truth的IoU介於0.3和0.7的anchor沒有使用。在訓練anchor屬於前景與背景的時候,是在一張圖中,隨機抽取了128個前景anchor與128個背景anchor。
在上一段中描述了前景與背景分類的訓練方法,本段描述anchor邊框修正的訓練方法。邊框修正主要由4個值完成,tx,ty,th,tw。這四個值的意思是修正後的框在anchor的x和y方向上做出平移(由tx和ty決定),並且長寬各自放大一定的倍數(由th和ty決定)。那麼,如何訓練網路引數得到這四個值呢?Fast R-CNN給出了答案,採用SmoothL1loss進行訓練,具體可以描述為:
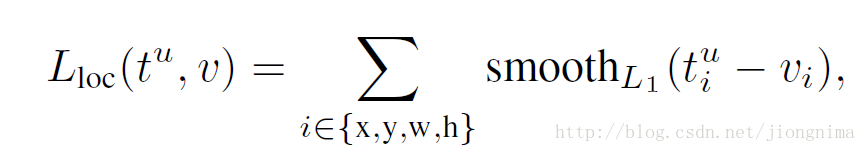
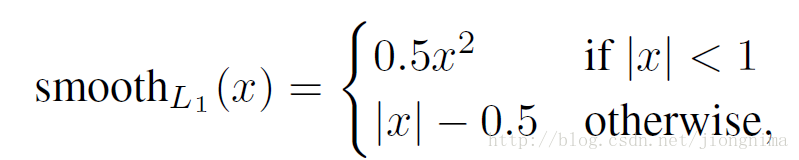
到這裡有個問題,就是不是對於所有的anchor,都需要進行anchor包圍框修正的引數訓練,只是對positive的anchors有這一步。因此,在訓練RPN的時候,只有對128個隨機抽取的positive anchors有這一步訓練。因此,訓練RPN的損失函式可以寫成:
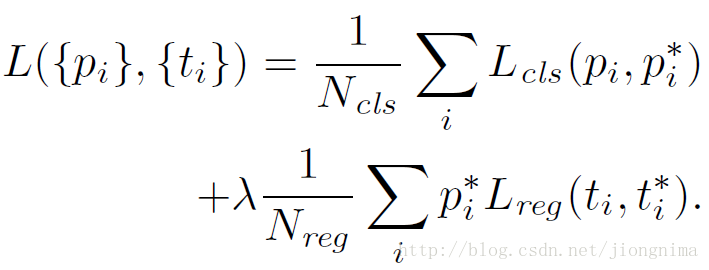
在這裡Lreg就是上面的Lloc,λ被設定為10,Ncls為256,Nreg為2400。這樣設定的話,RPN的兩部分loss值能保持平衡。
到這裡RPN就解析完畢了,下面我們來看看後面的classifier,但是在介紹classifier之前,我們先來看看RoI Pooling到底做了什麼?
首先第一個問題是為什麼需要RoI Pooling?答案是在Fast R-CNN中,特徵被共享卷積層一次性提取。因此,對於每個RoI而言,需要從共享卷積層上摘取對應的特徵,並且送入全連線層進行分類。因此,RoI Pooling主要做了兩件事,第一件是為每個RoI選取對應的特徵,第二件事是為了滿足全連線層的輸入需求,將每個RoI對應的特徵的維度轉化成某個定值。RoI Pooling示意圖如下所示:
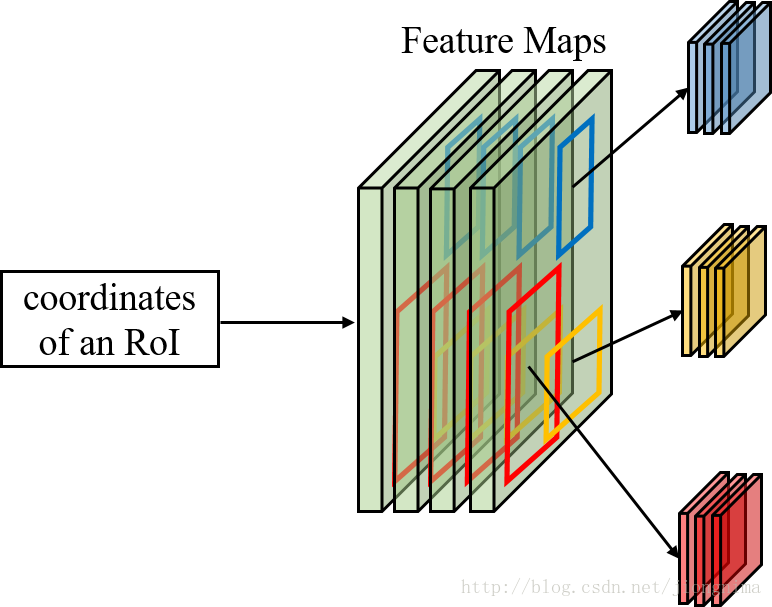
如上圖所示,對於每一個RoI,RoI Pooling Layer將其對應的特徵從共享卷積層上拿出來,並轉化成一樣的大小(6×6)。
在RoI Pooling Layer之後,就是Fast R-CNN的分類器和RoI邊框修正訓練。分類器主要是分這個提取的RoI具體是什麼類別(人,車,馬等等),一共C+1類(包含一類背景)。RoI邊框修正和RPN中的anchor邊框修正原理一樣,同樣也是SmoothL1 Loss,值得注意的是,RoI邊框修正也是對於非背景的RoI進行修正,對於類別標籤為背景的RoI,則不進行RoI邊框修正的引數訓練。對於分類器和RoI邊框修正的訓練,可以公式描述如下:
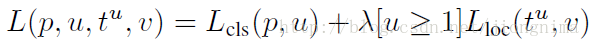
上式中u>=1表示RoI邊框修正是對於非背景的RoI而言的,實驗中,上式的λ取1。
在訓練分類器和RoI邊框修正時,步驟如下所示:
1) 首先通過RPN生成約20000個anchor(40×60×9)。
2) 對20000個anchor進行第一次邊框修正,得到修訂邊框後的proposal。
3) 對超過影象邊界的proposal的邊進行clip,使得該proposal不超過影象範圍。
4) 忽略掉長或者寬太小的proposal。
5) 將所有proposal按照前景分數從高到低排序,選取前12000個proposal。
6) 使用閾值為0.7的NMS演算法排除掉重疊的proposal。
7) 針對上一步剩下的proposal,選取前2000個proposal進行分類和第二次邊框修正。
總的來說,Faster R-CNN的loss分兩大塊,第一大塊是訓練RPN的loss(包含一個SoftmaxLoss和SmoothL1Loss),第二大塊是訓練Fast R-CNN中分類器的loss(包含一個SoftmaxLoss和SmoothL1Loss),Faster R-CNN的總的loss函式描述如下:
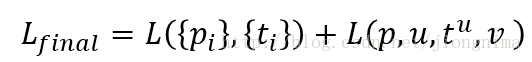
然後,對於Faster R-CNN的訓練方式有三種,可以被描述如下:
1) RPN和Fast R-CNN交替訓練,這種方式也是作者採用的方式。
2) 近似聯合RPN和Fast R-CNN的訓練,在訓練時忽略掉了RoI邊框修正的誤差,也就是說只對anchor做了邊框修訂,這也是為什麼叫"近似聯合"的原因。
3) 聯合RPN和Fast R-CNN的訓練。
對於作者採用的交替訓練的方式,步驟如下:
1) 使用在ImageNet上預訓練的模型初始化共享卷積層並訓練RPN。
2) 使用上一步得到的RPN引數生成RoI proposal。再使用ImageNet上預訓練的模型初始化共享卷積層,訓練Fast R-CNN部分(分類器和RoI邊框修訂)。
3) 將訓練後的共享卷積層引數固定,同時將Fast R-CNN的引數固定,訓練RPN。(從這一步開始,共享卷積層的引數真正被兩大塊網路共享)
4) 同樣將共享卷積層引數固定,並將RPN的引數固定,訓練Fast R-CNN部分。
Faster R-CNN的測試流程和訓練流程挺相似,描述如下:
1) 首先通過RPN生成約20000個anchor(40×60×9)通過RPN。
2) 對20000個anchor進行第一次邊框修正,得到修訂邊框後的proposal。
3) 對超過影象邊界的proposal的邊進行clip,使得該proposal不超過影象範圍。
4) 忽略掉長或者寬太小的proposal。
5) 將所有proposal按照前景分數從高到低排序,選取前6000個proposal。
6) 使用閾值為0.7的NMS演算法排除掉重疊的proposal。
7) 針對上一步剩下的proposal,選取前300個proposal進行分類和第二次邊框修正。
到這裡,Faster R-CNN就介紹完畢了。接下來到了Mask R-CNN,我們來看看RoI Pooling出了什麼問題:問題1:從輸入圖上的RoI到特徵圖上的RoI feature,RoI Pooling是直接通過四捨五入取整得到的結果。
這一點可以在程式碼中印證:

可以看到直接用round取的值,這樣會帶來什麼壞處呢?就是RoI Pooling過後的得到的輸出可能和原影象上的RoI對不上,如下圖所示:

右圖中藍色部分表示包含了轎車主體的的資訊的方格,RoI Pooling Layer的四捨五入取整操作導致其進行了偏移。
問題2:再將每個RoI對應的特徵轉化為固定大小的維度時,又採用了取整操作。在這裡筆者舉例講解一下RoI Pooling的操作:
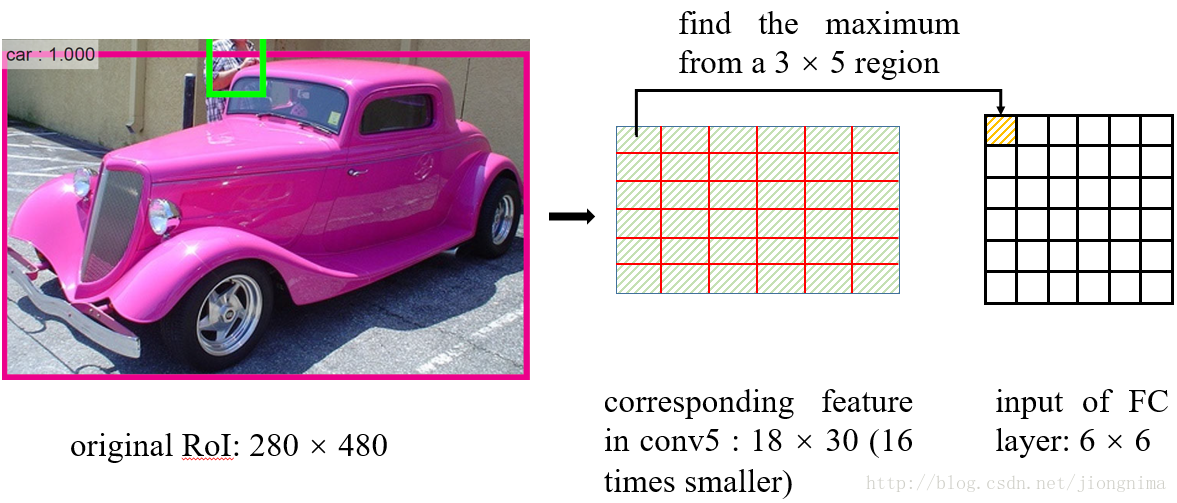
在從RoI得到對應的特徵圖時,進行了問題1描述的取整,在得到特徵圖後,如何得到一個6×6的全連線層的輸入呢?RoI Pooling這樣做:將RoI對應的特徵圖分成6×6塊,然後直接從每塊中找到最大值。在上圖中的例子中,比如原圖上的的RoI大小是280×480,得到對應的特徵圖是18×30。將特徵圖分成6塊,每塊大小是3×5,然後在每一塊中分別選擇最大值放入6×6的對應區域中。在將特徵圖分塊的時候,又用到了取整,這點同樣可以在程式碼中得到佐證:

這種取整操作(在Mask R-CNN中被稱為quantization)對RoI分類影響不大,可是對逐畫素的預測目標是有害的,因為對每個RoI取得的特徵並沒有與RoI對齊。因此,Mask R-CNN對RoI Pooling做了改進並提出了RoI Align。
RoI Align的主要創新點是,針對問題1,不再進行取整操作。針對問題2,使用雙線性插值來更精確地找到每個塊對應的特徵。總的來說,RoI Align的作用主要就是剔除了RoI Pooling的取整操作,並且使得為每個RoI取得的特徵能夠更好地對齊原圖上的RoI區域。
下圖闡述了Mask R-CNN的Mask branch:
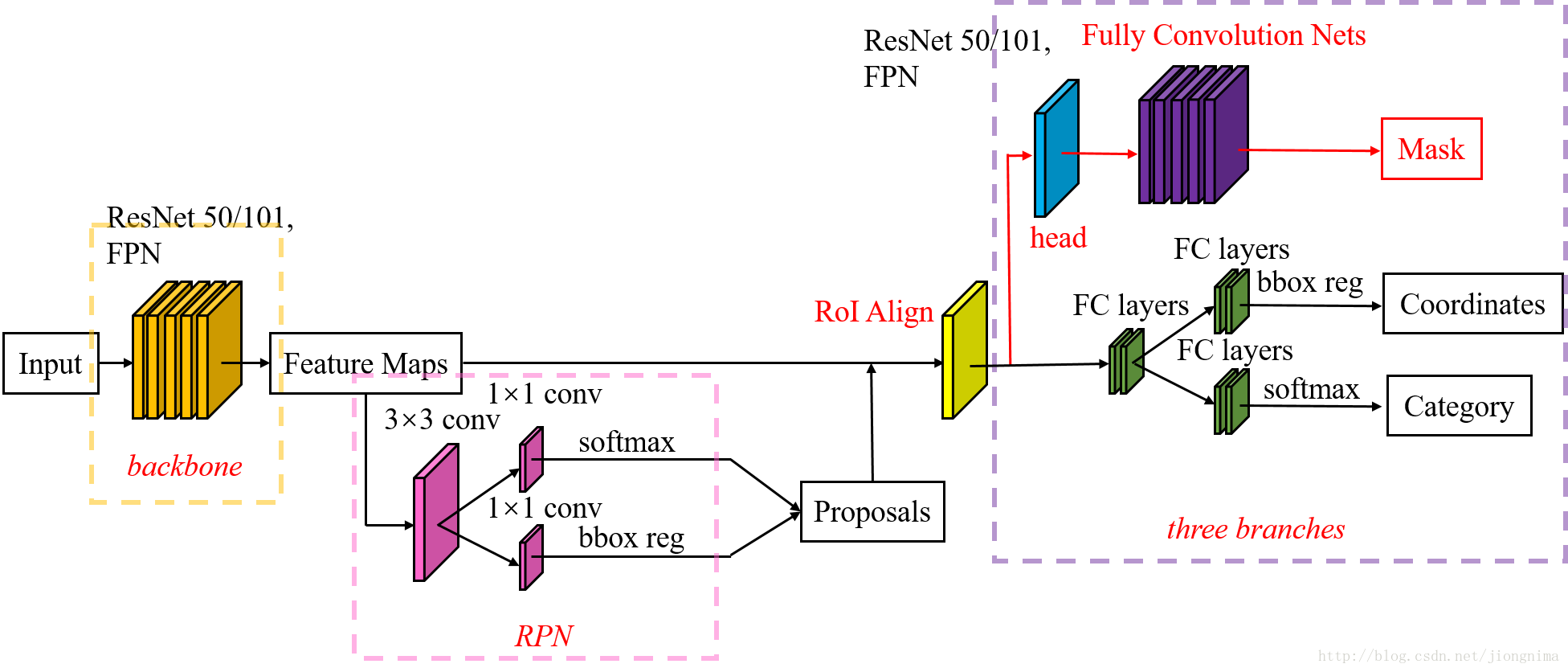
在Mask R-CNN中的RoI Align之後有一個"head"部分,主要作用是將RoI Align的輸出維度擴大,這樣在預測Mask時會更加精確。在Mask Branch的訓練環節,作者沒有采用FCN式的SoftmaxLoss,反而是輸出了K個Mask預測圖(為每一個類都輸出一張),並採用average binary cross-entropy loss訓練,當然在訓練Mask branch的時候,輸出的K個特徵圖中,也只是對應ground truth類別的那一個特徵圖對Mask loss有貢獻。
Mask R-CNN的訓練損失函式可以描述為:
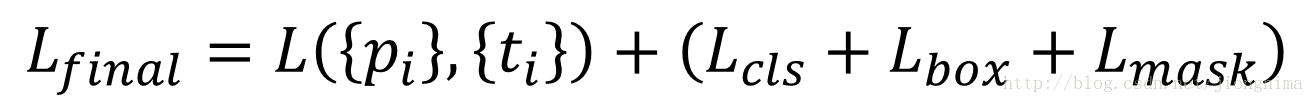
在上式中,Lbox和Lmask都是對positive RoI才會起作用的。
在Mask R-CNN中,相較於Faster R-CNN還有些略微的調整,比如positive RoI被定義成了與Ground truth的IoU大於0.5的(Faster R-CNN中是0.7)。太過於細節的東西本篇博文不再贅述,詳情參見Mask R-CNN中的Implementation Details。
到這裡再將Mask R-CNN和FCIS做個比較,首先兩者的相同點是均繼承了Faster R-CNN的RPN部分。不同點是對於FCIS,預測mask和分類是共享的引數。而Mask R-CNN則是各玩各的,兩個任務各自有各自的可訓練引數。對於這一點,Mask R-CNN論文裡還專門作了比較,顯示對於預測mask和分類如果使用共享的特徵圖對於某些重疊目標可能會出現問題。

Mask R-CNN的實驗取得了很好的效果,達到甚至超過了state-of-the-art的水平。不過訓練代價也是相當大的,需要8塊GPU聯合訓練。
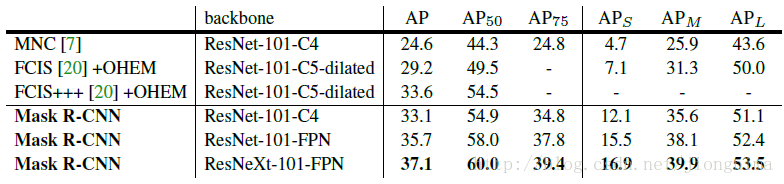
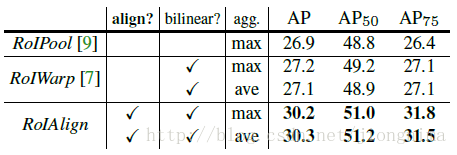
Mask R-CNN的實驗非常詳細,還做了很多對比實驗,比如說改換網路深度,在訓練mask branch時的誤差種類,將RoI Align同RoI Pooling和RoI Warping進行比較,改變預測mask的方式(FCN和全連線層)等,詳情請參見Mask R-CNN的實驗部分。
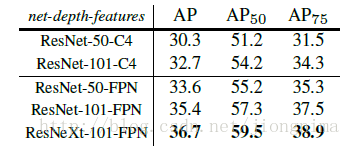
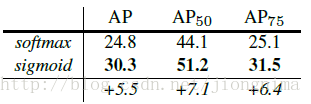

到這裡Mask R-CNN介紹就接近尾聲了,筆者還想說一些自己的思考與感想:
1) 可繼承工作的充分體現。大家看到Mask R-CNN的結構相當複雜,實際上是繼承了大量之前的工作。首先bounding box regression在2014年的R-CNN中就出現過。Mask R-CNN的主要創新點RoI Align改良於RoI Pooling,而RoI Pooling是在2015年的Fast R-CNN中提出的。對於RPN的應用,更是直接繼承了2016年的Faster R-CNN。值得一提的是,上述的每一篇文章,都是顛覆目標檢測領域計算架構的傑出作品。
2)整合的工作。還是那句老話,到了2017-2018年,隨著深度學習的高速發展,單任務模型已經逐漸被拋棄。取而代之的是更整合,更綜合,更強大的多工模型。Mask R-CNN就是其中的代表。
3)引領潮流。再次向何凱明和Ross Girshick致敬,他們的實力引領了目標檢測領域的發展,因此無論他們在哪,無論是在微軟還是FaceBook,他們的idea和作品都被非常多的人應用或者繼承。
歡迎閱讀筆者後續部落格,各位讀者朋友的支援與鼓勵是我最大的動力!
written by jiong
鴻爪踏雪泥,還是來得及。
相關推薦
例項分割模型Mask R-CNN詳解:從R-CNN,Fast R-CNN,Faster R-CNN再到Mask R-CNN
Mask R-CNN是ICCV 2017的best paper,彰顯了機器學習計算機視覺領域在2017年的最新成果。在機器學習2017年的最新發展中,單任務的網路結構已經逐漸不再引人矚目,取而代之
#圖文詳解:從實際和理論出發,帶你瞭解Java中的多執行緒
這裡並沒有講什麼新東西,只是把多執行緒一些知識來個總結。大家懂得可以複習複習,還有些童鞋對多執行緒朦朧的可以拿這個做為入門~ 舉個栗子說明啥是多執行緒:玩遊戲,前面一堆怪,每個怪都是一個執行緒,你射了一槍,子彈飛出去了,這顆子彈也是一個執行緒。你開啟你的程序管理,看到你遊戲的後臺程序,這就是程序
Faster RCNN詳解:從region proposal到bounding box迴歸
一基於Region Proposal候選區域的深度學習目標檢測演算法 二R-CNNFast R-CNNFaster R-CNN三者關係 1 R-CNN目標檢測流程介紹 2 Fast R-CNN目標檢測流程介紹
【 專欄 】- Android DataBinding詳解:從入門到深入
Android DataBinding詳解:從入門到深入 Android DataBinding(View Model繫結)技術詳解:從入門到深入。從簡單的Android DataBinding技術到複雜的雙向繫結,單向繫結和反向
大資料架構詳解:從資料獲取到深度學習
機器學習(Machine Learning,ML)是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、演算法複雜度理論等多門學科。其專門研究計算機是怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構,使之不斷改善自身的效能。此外,資料探勘和機
【目標檢測】【語義分割】—Mask-R-CNN詳解
一、mask rcnn簡介 論文連結:論文連結 論文程式碼:Facebook程式碼連結;Tensorflow版本程式碼連結; Keras and TensorFlow版本程式碼連結;MxNet版本程式碼連結 mask rcnn是基於faster rcnn架構提出的卷積網
Mask R-CNN詳解
論文題目:Mask R-CNN 論文連結:論文連結論文程式碼:Facebook程式碼連結;Tensorflow版本程式碼連結; Keras and TensorFlow版本程式碼連結;MxNet版本程式碼連結一、Mask R-CNN是什麼,可以做哪些任務?圖1 Mask R-
深度學習 + 論文詳解: Fast R-CNN 原理與優勢
論文連結p.s. 鑑於斯坦福大學公開課裡面模糊的 R-CNN 描述,這邊決定精讀對應的論文並把心得和摘要記錄於此。前言在機器視覺領域的物體識別分支中,有兩個主要的兩大難題需要解決:目標圖片裡面含了幾種“物體”,幾個“物體”?該些物體分別坐落於圖片的哪個位置?而 R-CNN 的
資料庫設計之概念結構設計---------E-R圖詳解 (各種各樣的例項)
http://blog.csdn.net/zxq1138634642/article/details/9121363 0、試述採用E-R方法進行資料庫概念設計的過程。 答:採用E-R方法進行資料庫概念設計,可以分成3步進行:首先設計區域性E-R模式,然後把各區域性E-R
CNN詳解
title http 信號與系統 left 圖像 col 過程 過渡 spec CNN詳解 版權聲明:本文為博主原創文章,轉載請指明轉載地址 http://www.cnblogs.com/fydeblog/p/7450413.html 前言 這篇博客主要就是卷積神經
教程 | Kaggle網站流量預測任務第一名解決方案:從模型到代碼詳解時序預測
abs rdf reg lock 集成 deep 月份 current 均值 https://mp.weixin.qq.com/s/JwRXBNmXBaQM2GK6BDRqMw 選自GitHub 作者:Artur Suilin 機器之心編譯 參與:蔣思源、路雪、黃小天
R-FCN詳解
論文題目:R-FCN: Object Detection via Region-based Fully Convolutional Networks 論文連結:論文連結 論文程式碼:Caffe版本連結地址;Python版本連結地址;Deformable R-FCN版本連結地址
例項化vue發生了什麼?(詳解vue生命週期)
例項化vue發生了什麼?(詳解vue生命週期) 本文將對vue的生命週期進行詳細的講解,讓你瞭解一個vue例項的誕生都經歷了什麼~ 我在Github上建立了一個存放vue筆記的倉庫,以後會陸續更新一些知識和專案中遇到的坑,有興趣的同學可以去看看哈(歡迎star)! 傳送門 例項化一個Vue c
R DESeq2 詳解
DESeq2結果p-value和padj設為NA的理由: Note on p-values set to NA: some values in the results table can be set to NA for one of the following reasons:
Django 模型層 Meta 選項詳解
Meta 是 Django 模型類的一個內部類,用於定義一些與 Django 特定模型相關的一些選項。 可選的選項有 1. abstract 表示模型是否是抽象基類,abstract = True,則表示模型是抽象基類。 所謂抽象基類,指該模型不會對應資料庫表,即 Dj
Django模型之Meta選項詳解
Django模型類的Meta是一個內部類,它用於定義一些Django模型類的行為特性。而可用的選項大致包含以下幾類 abstract 這個屬性是定義當前的模型是不是一個抽象類。所謂抽象類是不會對應資料庫表的。一般我們用它來歸納一些公共屬性欄位,然後繼承它的子類可以繼承這些
CSS例項詳解:Flex佈局
本文由雲+社群發表 本文將通過三個簡單的例項,實際應用上篇文章的基礎理論知識,展示下Flex佈局是如何解決CSS佈局問題。 一.垂直居中 這裡同時用非flex佈局和flex佈局兩種方式來實現,可以對比兩種實現方式的差異。 1.1用margin實現垂直居中 實現方式: 父元素採用相對定位,
統計引數 SSE,MSE,RMSE,R-square 詳解
原文章地址:http://blog.sina.com.cn/s/blog_628033fa0100kjjy.html 在學習線性迴歸的過程中,遇到下面幾個名詞:SSE(和方差、誤差平方和):The sum of squares dueto error MSE(均方差、方差):Meansqua
Spark MLlib 貝葉斯分類演算法例項具體程式碼及執行過程詳解
import org.apache.log4j.{Level, Logger} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.mllib.classification.{NaiveBayes, Naiv
Python 例項詳解:銀行 ATM 等待時間分析
這是一道 Python 面向物件程式設計的例項,包含面向物件程式設計、Class 類相關知識,請讀者先自行掌握。本文分析已有程式碼,主要理解其中邏輯,學習程式設計方法。程式碼乍看之下稍微複雜,拆解之後,弄通邏輯,還是很清晰明瞭的。 前部分為程式碼分析,可以重點看