
機器學習之過擬合的解決方法
阿新 • • 發佈:2019-02-12
過擬合
過擬合,是指模型在訓練集上表現的很好,但是在交叉驗證集合測試集上表現一般,也就是說模型對未知樣本的預測表現一般,泛化(generalization)能力較差。
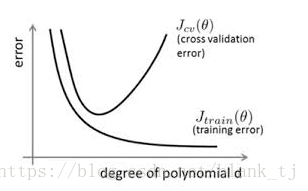
一般防止過擬合的方法有early stopping、資料集擴增(Data augmentation)、正則化(Regularization)、Dropout等。
Early stopping:
在模型對訓練資料集迭代收斂之前停止迭代來防止過擬合。
正則化
指的是在目標函式(損失函式)後面新增一個正則化項,一般有L1正則化與L2正則化。L1正則是基於L1範數,即引數絕對值之和與引數的乘積。
L2正則是基於L2範數,即在目標函式後面加上引數的L2範數和項,即引數的平方和與引數的乘積。
資料集擴增
有效的資料集擴增方法:
1)從資料來源頭採集更多資料
2)複製原有資料並加上隨機噪聲
3)重取樣
4)根據當前資料集估計資料分佈引數,使用該分佈產生更多資料等
DropOut:
簡單說就是在神經網路中,對隱藏層的神經元隨機的進行隱藏,認為這些神經元不存在,即不參與當前次訓練,同時保持輸入層與輸出層神經元的個數不變。下一次迭代中,同樣隨機刪除一些神經元,與上次不一樣,做隨機選擇。