
京東口紅top 30分析
阿新 • • 發佈:2017-11-03
urn gecko 寫入 turn 方法 mage 所有 pid 影響
一、抓取商品id
分析網頁源碼,發現所有id都是在class=“gl-item”的標簽裏,可以利用bs4的select方法查找標簽,獲取id:
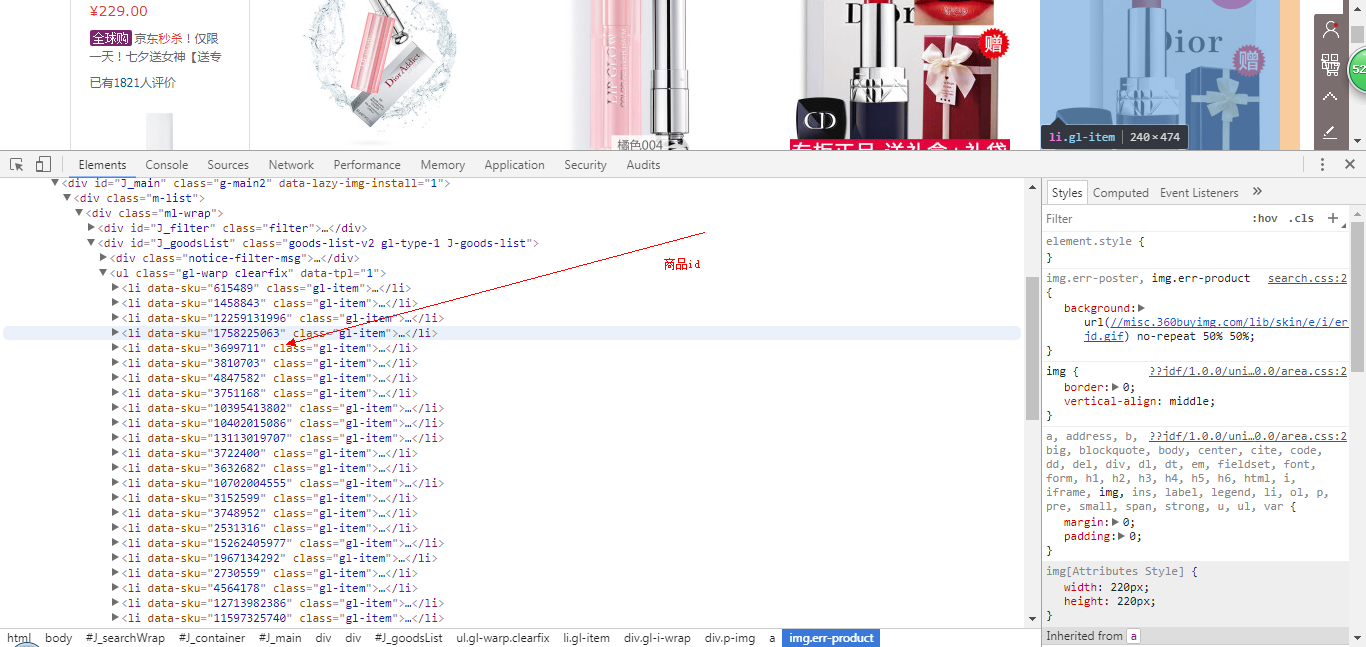
獲取id後,分析商品頁面可知道每個商品頁面就是id號不同,可構造url:
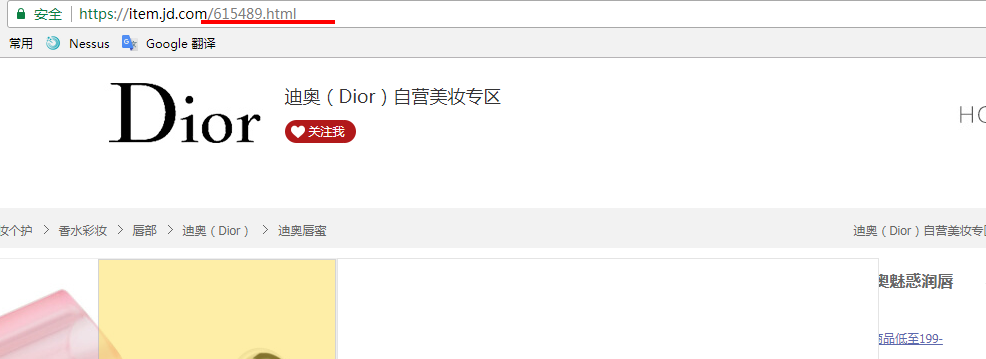
將獲取的id和構造的url保存在列表裏,如下源碼:
1 def get_product_url(url): 2 global pid 3 global links 4 req = urllib.request.Request(url) 5 req.add_header("User-Agent", 6 ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ‘ 7 ‘(KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36‘) 8 req.add_header("GET", url) 9 content = urllib.request.urlopen(req).read() 10 soup = bs4.BeautifulSoup(content, "lxml") 11 product_id = soup.select(‘.gl-item‘) 12 for i in range(len(product_id)): 13 lin = "https://item.jd.com/" + str(product_id[i].get(‘data-sku‘)) + ".html" 14 # 獲取鏈接 15 links.append(lin) 16 # 獲取id 17 pid.append(product_id[i].get(‘data-sku‘))
二、獲取商品信息
通過商品頁面獲取商品的基本信息(商品名,店名,價格等):
1 product_url = links[i]2 req = urllib.request.Request(product_url) 3 req.add_header("User-Agent", 4 ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0‘) 5 req.add_header("GET", product_url) 6 content = urllib.request.urlopen(req).read() 7 # 獲取商品頁面源碼 8 soup = bs4.BeautifulSoup(content, "lxml") 9 # 獲取商品名 10 sku_name = soup.select_one(‘.sku-name‘).getText().strip() 11 # 獲取商店名 12 try: 13 shop_name = soup.find(clstag="shangpin|keycount|product|dianpuname1").get(‘title‘) 14 except: 15 shop_name = soup.find(clstag="shangpin|keycount|product|zcdpmc_oversea").get(‘title‘) 16 # 獲取商品ID 17 sku_id = str(pid[i]).ljust(20) 18 # 獲取商品價格
通過抓取評論的json頁面獲取商品熱評、好評率、評論:
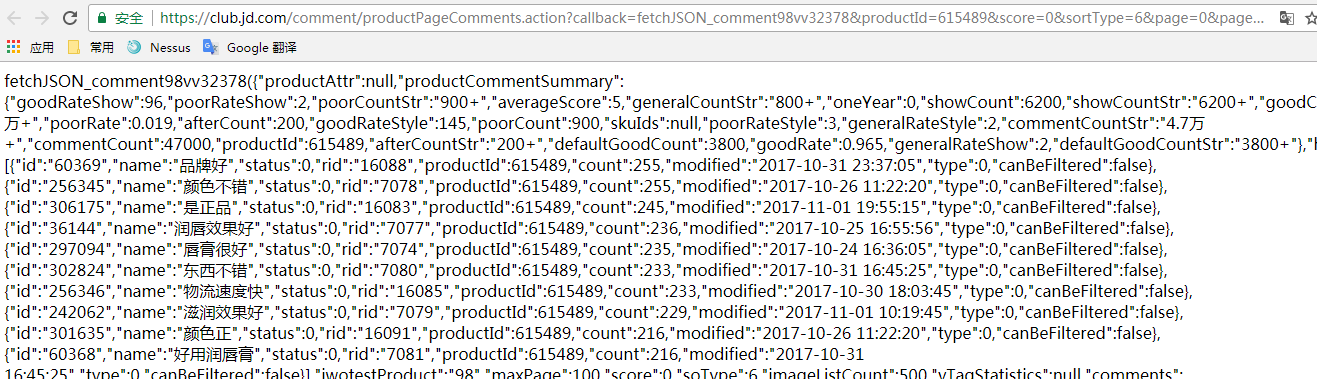
獲取熱評源碼:
1 def get_product_comment(product_id): 2 comment_url = ‘https://club.jd.com/comment/productPageComments.action?‘ 3 ‘callback=fetchJSON_comment98vv16496&‘ 4 ‘productId={}&‘ 5 ‘score=0&‘ 6 ‘sortType=6&‘ 7 ‘page=0&‘ 8 ‘pageSize=10‘ 9 ‘&isShadowSku=0‘.format(str(product_id)) 10 response = urllib.request.urlopen(comment_url).read().decode(‘gbk‘, ‘ignore‘) 11 response = re.search(r‘(?<=fetchJSON_comment98vv16496\().*(?=\);)‘, response).group(0) 12 response_json = json.loads(response) 13 # 獲取商品熱評 14 hot_comments = [] 15 hot_comment = response_json[‘hotCommentTagStatistics‘] 16 for h_comment in hot_comment: 17 hot = str(h_comment[‘name‘]) 18 count = str(h_comment[‘count‘]) 19 hot_comments.append(hot + ‘(‘ + count + ‘)‘) 20 return ‘,‘.join(hot_comments)
獲取好評率源碼:
1 def get_good_percent(product_id): 2 comment_url = ‘https://club.jd.com/comment/productPageComments.action?‘ 3 ‘callback=fetchJSON_comment98vv16496&‘ 4 ‘productId={}&‘ 5 ‘score=0&‘ 6 ‘sortType=6&‘ 7 ‘page=0&‘ 8 ‘pageSize=10‘ 9 ‘&isShadowSku=0‘.format(str(product_id)) 10 response = requests.get(comment_url).text 11 response = re.search(r‘(?<=fetchJSON_comment98vv16496\().*(?=\);)‘, response).group(0) 12 response_json = json.loads(response) 13 # 獲取好評率 14 percent = response_json[‘productCommentSummary‘][‘goodRateShow‘] 15 percent = str(percent) + ‘%‘ 16 return percent
獲取評論源碼:
1 def get_comment(product_id, page): 2 global word 3 comment_url = ‘https://club.jd.com/comment/productPageComments.action?‘ 4 ‘callback=fetchJSON_comment98vv16496&‘ 5 ‘productId={}&‘ 6 ‘score=0&‘ 7 ‘sortType=6&‘ 8 ‘page={}&‘ 9 ‘pageSize=10‘ 10 ‘&isShadowSku=0‘.format(str(product_id), str(page)) 11 response = urllib.request.urlopen(comment_url).read().decode(‘gbk‘, ‘ignore‘) 12 response = re.search(r‘(?<=fetchJSON_comment98vv16496\().*(?=\);)‘, response).group(0) 13 response_json = json.loads(response) 14 # 寫入評論.csv 15 comment_file = open(‘{0}\\評論.csv‘.format(path), ‘a‘, newline=‘‘, encoding=‘utf-8‘, errors=‘ignore‘) 16 write = csv.writer(comment_file) 17 # 獲取用戶評論 18 comment_summary = response_json[‘comments‘] 19 for content in comment_summary: 20 # 評論時間 21 creation_time = str(content[‘creationTime‘]) 22 # 商品顏色 23 product_color = str(content[‘productColor‘]) 24 # 商品名稱 25 reference_name = str(content[‘referenceName‘]) 26 # 客戶評分 27 score = str(content[‘score‘]) 28 # 客戶評論 29 content = str(content[‘content‘]).strip() 30 # 記錄評論 31 word.append(content) 32 write.writerow([product_id, reference_name, product_color, creation_time, score, content]) 33 comment_file.close()
整體獲取商品信息源碼:
1 def get_product_info(): 2 global pid 3 global links 4 global word 5 # 創建評論.csv 6 comment_file = open(‘{0}\\評論.csv‘.format(path), ‘w‘, newline=‘‘) 7 write = csv.writer(comment_file) 8 write.writerow([‘商品id‘, ‘商品‘, ‘顏色‘, ‘評論時間‘, ‘客戶評分‘, ‘客戶評論‘]) 9 comment_file.close() 10 # 創建商品.csv 11 product_file = open(‘{0}\\商品.csv‘.format(path), ‘w‘, newline=‘‘) 12 product_write = csv.writer(product_file) 13 product_write.writerow([‘商品id‘, ‘所屬商店‘, ‘商品‘, ‘價格‘, ‘商品好評率‘, ‘商品評價‘]) 14 product_file.close() 15 16 for i in range(len(pid)): 17 print(‘[*]正在收集數據。。。‘) 18 product_url = links[i] 19 req = urllib.request.Request(product_url) 20 req.add_header("User-Agent", 21 ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0‘) 22 req.add_header("GET", product_url) 23 content = urllib.request.urlopen(req).read() 24 # 獲取商品頁面源碼 25 soup = bs4.BeautifulSoup(content, "lxml") 26 # 獲取商品名 27 sku_name = soup.select_one(‘.sku-name‘).getText().strip() 28 # 獲取商店名 29 try: 30 shop_name = soup.find(clstag="shangpin|keycount|product|dianpuname1").get(‘title‘) 31 except: 32 shop_name = soup.find(clstag="shangpin|keycount|product|zcdpmc_oversea").get(‘title‘) 33 # 獲取商品ID 34 sku_id = str(pid[i]).ljust(20) 35 # 獲取商品價格 36 price_url = ‘https://p.3.cn/prices/mgets?pduid=1580197051&skuIds=J_{}‘.format(pid[i]) 37 response = requests.get(price_url).content 38 price = json.loads(response) 39 price = price[0][‘p‘] 40 # 寫入商品.csv 41 product_file = open(‘{0}\\商品.csv‘.format(path), ‘a‘, newline=‘‘, encoding=‘utf-8‘, errors=‘ignore‘) 42 product_write = csv.writer(product_file) 43 product_write.writerow( 44 [sku_id, shop_name, sku_name, price, get_good_percent(pid[i]), get_product_comment(pid[i])]) 45 product_file.close() 46 pages = int(get_comment_count(pid[i])) 47 word = [] 48 try: 49 for j in range(pages): 50 get_comment(pid[i], j) 51 except Exception as e: 52 print("[!!!]{}商品評論加載失敗!".format(pid[i])) 53 print("[!!!]Error:{}".format(e)) 54 55 print(‘[*]第{}件商品{}收集完畢!‘.format(i + 1, pid[i]))56 # 的生成詞雲 57 word = " ".join(word) 58 my_wordcloud = WordCloud(font_path=‘C:\Windows\Fonts\STZHONGS.TTF‘, background_color=‘white‘).generate(word) 59 my_wordcloud.to_file("{}.jpg".format(pid[i]))
將商品信息和評論寫入表格,生成評論詞雲:






三、總結
在爬取的過程中遇到最多的問題就是編碼問題,獲取頁面的內容requset到的都是bytes類型的要decode(”gbk”),後來還是存在編碼問題,最後找到一些文章說明,在後面加“ignore”可以解決,由於爬取的量太大,會有一些數據丟失,不過數據量夠大也不影響對商品分析。
京東口紅top 30分析