
爬取N個網頁,並將其記錄
阿新 • • 發佈:2017-11-06
color 完整 encode down utf 模塊 round 初始 函數 
挖的坑,終於能填上了,先共享出來,大家有個對比參考。也幫忙找找錯誤。我也正在看,看看原來是哪裏出了問題。
下面這段代碼已經實現了網頁的爬取:
其效果為:
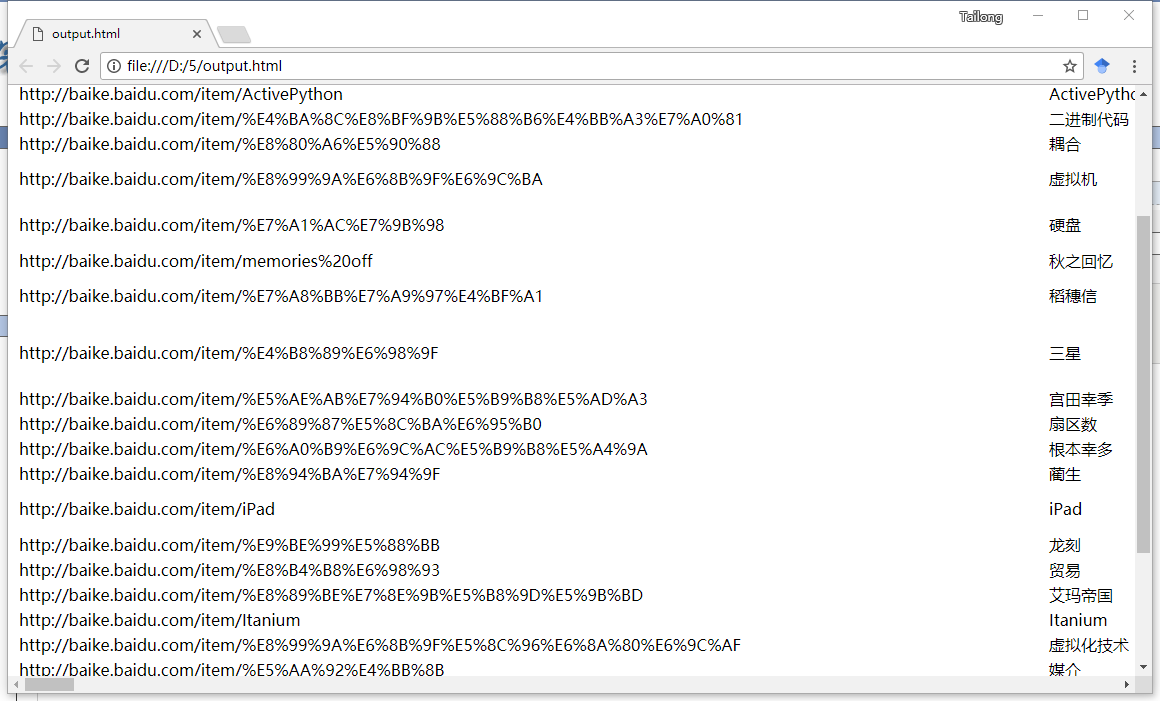
下面給出詳細說明:
上圖中出現的 __init__.py 文件,是一個空的,但是必須建立(我也沒想明白為啥)。
程序結束後,打開output.html 就可以了。
1.這是網頁管理模塊 url_manager.py (點擊+號,看代碼)

class UrlManager(object): def __init__(self): self.new_urls=set() self.old_urlsView Code=set() #向管理器中添加一個新的url def add_new_url(self,url): if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) #向管理器中添加多個新的url def add_new_urls(self,urls): if urls is None orlen(urls)==0: return for url in urls: self.add_new_url(url) #判斷管理器中是否還有新的待爬取的url def has_new_url(self): return len(self.new_urls)!=0 #從管理器中獲取一個新的待爬取的url def get_new_url(self): new_url=self.new_urls.pop()#獲取並移除 self.old_urls.add(new_url)#添加至舊的集合 return new_url
2.這是下載網頁模塊 html_downloader.py
import urllib.request class HtmlDownloader(object): #下載一個url裏的數據 def download(self,url): if url is None: return None response=urllib.request.urlopen(url)#註意py2和py3不同 if response.getcode()!=200:#狀態碼200表示獲取成功 return None return response.read()#返回下載好的內容View Code
3.這是網頁解析模塊 html_parser.py
from bs4 import BeautifulSoup import re import urllib.parse #py3中urlparse在urllib中 class HtmlParser(object): #返回新的url集合 def _get_new_urls(self,page_url,soup): new_urls=set() #獲取所有的鏈接,用正則匹配 links=soup.find_all(‘a‘,href=re.compile(r"/item/")) for link in links: new_url=link[‘href‘]#獲取它的鏈接(不完全) #將不完整的new_url按照page_url的格式拼成完整的 new_full_url=urllib.parse.urljoin(page_url,new_url) new_urls.add(new_full_url) return new_urls #返回對soup的解析結果 def _get_new_data(self,page_url,soup): res_data={} #url res_data[‘url‘]=page_url #<dd class="lemmaWgt-lemmaTitle-title"><h1>Python</h1> #獲取詞條名(用了兩次find) title_node=soup.find(‘dd‘,class_="lemmaWgt-lemmaTitle-title").find("h1") #註意這裏先split再做join,將\\變成了\ res_data[‘title‘]=‘\\‘.join(title_node.get_text().split(‘\\\\‘))#加入字典中 #<div class="lemma-summary"> #獲取摘要文字 summary_node=soup.find(‘div‘,class_="lemma-summary") #註意這裏先split再做join,將\\變成了\ res_data[‘summary‘]=‘\\‘.join(summary_node.get_text().split(‘\\\\‘))#加入字典中 return res_data #解析一個下載好的頁面的數據,並返回新的url列表和解析結果 def parse(self,page_url,html_cont): if page_url is None or html_cont is None: return #創建一個bs對象(將網頁字符串html_cont加載成一棵DOM樹) soup=BeautifulSoup(html_cont,‘html.parser‘) new_urls=self._get_new_urls(page_url,soup) new_data=self._get_new_data(page_url,soup) return new_urls,new_dataView Code
4.下面是網頁輸出模塊 html_outputer.py
class HtmlOutputer(object): def __init__(self): self.datas=[] #收集解析好的數據 def collect_data(self,data): if data is None: return self.datas.append(data) #輸出所有收集好的數據 def output_html(self): with open(‘output.html‘,‘w‘) as fout: fout.write("<html>") ‘‘‘fout.write("<head>") fout.write("<meta charset=\"utf-8\">") fout.write("</head>")‘‘‘ fout.write("<body>") fout.write("<table>") for data in self.datas: fout.write("<tr>") fout.write("<td>%s</td>"%data[‘url‘]) fout.write("<td>%s</td>"%data[‘title‘]) fout.write("<td>%s</td>"%data[‘summary‘].encode(‘utf-8‘)) fout.write("</tr>") fout.write("</table>") fout.write("</body>") fout.write("</html>") fout.close()View Code
5.主函數,運行這個就可以了
import url_manager,html_downloader,html_parser,html_outputer class SpiderMain(object): def __init__(self):#在構造器中初始化所需要的對象 self.urls=url_manager.UrlManager()#url管理器 self.downloader=html_downloader.HtmlDownloader()#下載器 self.parser=html_parser.HtmlParser()#解析器 self.outputer=html_outputer.HtmlOutputer()#價值數據的輸出 def craw(self,root_url): count=1#記錄當前爬取的是第幾個url self.urls.add_new_url(root_url)#先將入口url給url管理器 #啟動爬蟲的循環 while self.urls.has_new_url():#如果管理器中還有url try: new_url=self.urls.get_new_url()#就從中獲取一個url print (‘craw %d : %s‘%(count,new_url))#打印正在爬的url html_cont=self.downloader.download(new_url)#然後用下載器下載它 #調用解析器去解析這個頁面的數據 new_urls,new_data=self.parser.parse(new_url,html_cont) self.urls.add_new_urls(new_urls)#新得到的url補充至url管理器 self.outputer.collect_data(new_data)#收集數據 if count==30:#如果已經爬了30個直接退出 break count+=1 except: print (‘craw failed‘)#標記這個url爬取失敗 self.outputer.output_html()#循環結束後輸出收集好的數據 if __name__=="__main__": root_url="http://baike.baidu.com/item/Python"#入口url obj_spider=SpiderMain() obj_spider.craw(root_url)View Code
以上內容,來自:http://blog.csdn.net/shu15121856/article/details/72903146
爬取N個網頁,並將其記錄