
淺析 Bigtable 和 LevelDB 的實現
在 2006 年的 OSDI 上,Google 發布了名為 Bigtable: A Distributed Storage System for Structured Data 的論文,其中描述了一個用於管理結構化數據的分布式存儲系統 - Bigtable 的數據模型、接口以及實現等內容。
![]()
本文會先對 Bigtable 一文中描述的分布式存儲系統進行簡單的描述,然後對 Google 開源的 KV 存儲數據庫 LevelDB 進行分析;LevelDB 可以理解為單點的 Bigtable 的系統,雖然其中沒有 Bigtable 中與 tablet 管理以及一些分布式相關的邏輯,不過我們可以通過對 LevelDB 源代碼的閱讀增加對 Bigtable 的理解。
Bigtable
Bigtable 是一個用於管理結構化數據的分布式存儲系統,它有非常優秀的擴展性,可以同時處理上千臺機器中的 PB 級別的數據;Google 中的很多項目,包括 Web 索引都使用 Bigtable 來存儲海量的數據;Bigtable 的論文中聲稱它實現了四個目標:
在作者看來這些目標看看就好,其實並沒有什麽太大的意義,所有的項目都會對外宣稱它們達到了高性能、高可用性等等特性,我們需要關註的是 Bigtable 到底是如何實現的。
數據模型
Bigtable 與數據庫在很多方面都非常相似,但是它提供了與數據庫不同的接口,它並沒有支持全部的關系型數據模型,反而使用了簡單的數據模型,使數據可以被更靈活的控制和管理。
在實現中,Bigtable 其實就是一個稀疏的、分布式的、多維持久有序哈希。
A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map.
它的定義其實也就決定了其數據模型非常簡單並且易於實現,我們使用 row、column 和 timestamp 三個字段作為這個哈希的鍵,值就是一個字節數組,也可以理解為字符串。
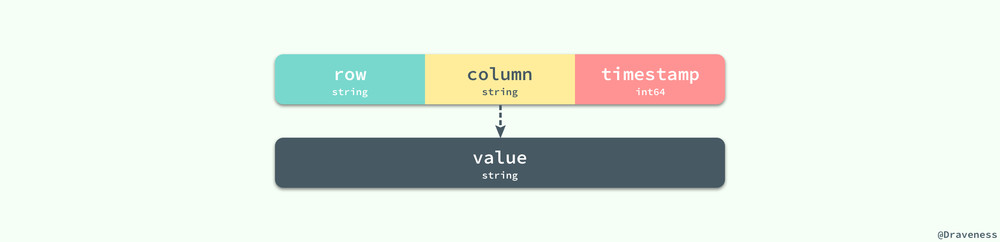
這裏最重要的就是 row 的值,它的長度最大可以為 64KB,對於同一 row 下數據的讀寫都可以看做是原子的;因為 Bigtable 是按照 row 的值使用字典順序進行排序的,每一段 row
實現
在這一節中,我們將介紹 Bigtable 論文對於其本身實現的描述,其中包含很多內容:tablet 的組織形式、tablet 的管理、讀寫請求的處理以及數據的壓縮等幾個部分。
tablet 的組織形式
我們使用類似 B+ 樹的三層結構來存儲 tablet 的位置信息,第一層是一個單獨的 Chubby 文件,其中保存了根 tablet 的位置。
Chubby 是一個分布式鎖服務,我們可能會在後面的文章中介紹它。

每一個 METADATA tablet 包括根節點上的 tablet 都存儲了 tablet 的位置和該 tablet 中 key 的最小值和最大值;每一個 METADATA 行大約在內存中存儲了 1KB 的數據,如果每一個 METADATA tablet 的大小都為 128MB,那麽整個三層結構可以存儲 2^61 字節的數據。
tablet 的管理
既然在整個 Bigtable 中有著海量的 tablet 服務器以及數據的分片 tablet,那麽 Bigtable 是如何管理海量的數據呢?Bigtable 與很多的分布式系統一樣,使用一個主服務器將 tablet 分派給不同的服務器節點。
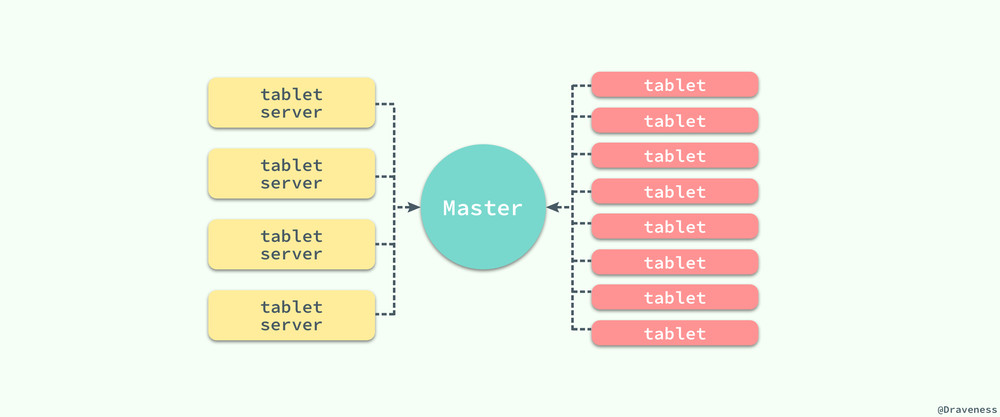
為了減輕主服務器的負載,所有的客戶端僅僅通過 Master 獲取 tablet 服務器的位置信息,它並不會在每次讀寫時都請求 Master 節點,而是直接與 tablet 服務器相連,同時客戶端本身也會保存一份 tablet 服務器位置的緩存以減少與 Master 通信的次數和頻率。
讀寫請求的處理
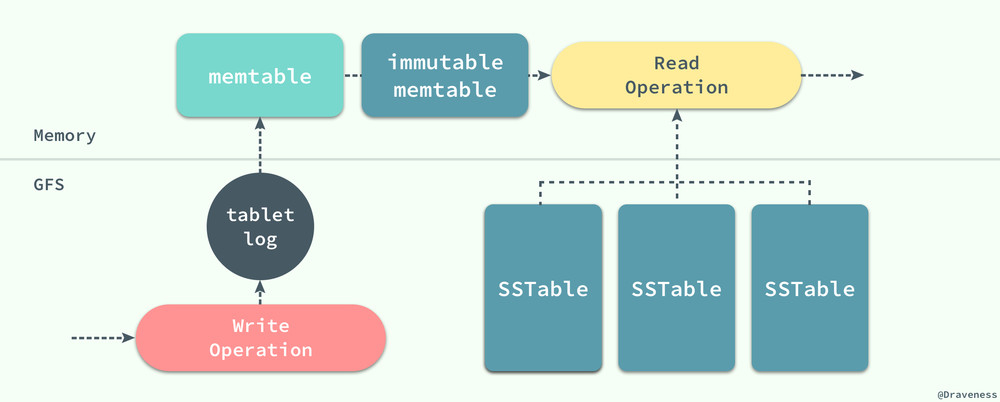
從讀寫請求的處理,我們其實可以看出整個 Bigtable 中的各個部分是如何協作的,包括日誌、memtable 以及 SSTable 文件。

當有客戶端向 tablet 服務器發送寫操作時,它會先向 tablet 服務器中的日誌追加一條記錄,在日誌成功追加之後再向 memtable 中插入該條記錄;這與現在大多的數據庫的實現完全相同,通過順序寫向日誌追加記錄,然後再向數據庫隨機寫,因為隨機寫的耗時遠遠大於追加內容,如果直接進行隨機寫,可能由於發生設備故障造成數據丟失。
當 tablet 服務器接收到讀操作時,它會在 memtable 和 SSTable 上進行合並查找,因為 memtable 和 SSTable 中對於鍵值的存儲都是字典順序的,所以整個讀操作的執行會非常快。
表的壓縮
隨著寫操作的進行,memtable 會隨著事件的推移逐漸增大,當 memtable 的大小超過一定的閾值時,就會將當前的 memtable 凍結,並且創建一個新的 memtable,被凍結的 memtable 會被轉換為一個 SSTable 並且寫入到 GFS 系統中,這種壓縮方式也被稱作 Minor Compaction。
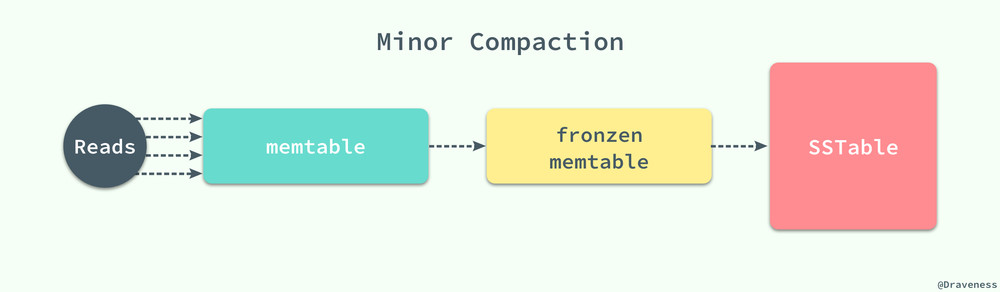
每一個 Minor Compaction 都能夠創建一個新的 SSTable,它能夠有效地降低內存的占用並且降低服務進程異常退出後,過大的日誌導致的過長的恢復時間。既然有用於壓縮 memtable 中數據的 Minor Compaction,那麽就一定有一個對應的 Major Compaction 操作。
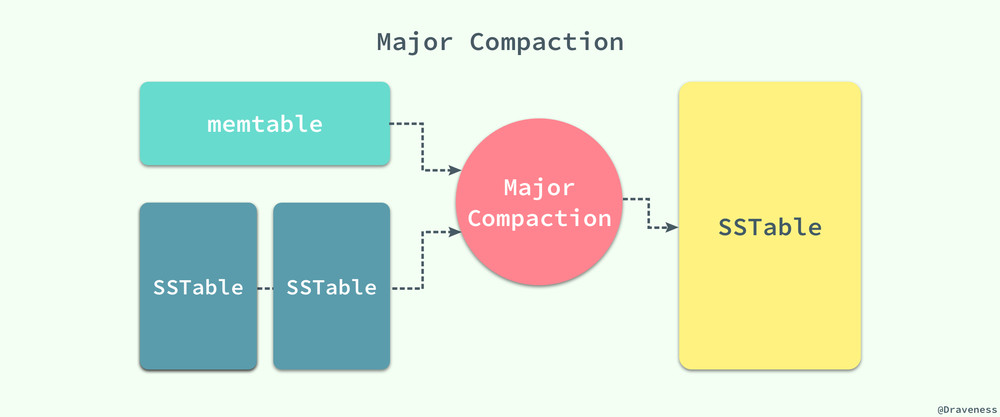
Bigtable 會在後臺周期性地進行 Major Compaction,將 memtable 中的數據和一部分的 SSTable 作為輸入,將其中的鍵值進行歸並排序,生成新的 SSTable 並移除原有的 memtable 和 SSTable,新生成的 SSTable 中包含前兩者的全部數據和信息,並且將其中一部分標記未刪除的信息徹底清除。
小結
到這裏為止,對於 Google 的 Bigtable 論文的介紹就差不多完成了,當然本文只介紹了其中的一部分內容,關於壓縮算法的實現細節、緩存以及提交日誌的實現等問題我們都沒有涉及,想要了解更多相關信息的讀者,這裏強烈推薦去看一遍 Bigtable 這篇論文的原文 Bigtable: A Distributed Storage System for Structured Data 以增強對其實現的理解。
LevelDB
文章前面對於 Bigtable 的介紹其實都是對 LevelDB 這部分內容所做的鋪墊,當然這並不是說前面的內容就不重要,LevelDB 是對 Bigtable 論文中描述的鍵值存儲系統的單機版的實現,它提供了一個極其高速的鍵值存儲系統,並且由 Bigtable 的作者 Jeff Dean 和 Sanjay Ghemawat 共同完成,可以說高度復刻了 Bigtable 論文中對於其實現的描述。
因為 Bigtable 只是一篇論文,同時又因為其實現依賴於 Google 的一些不開源的基礎服務:GFS、Chubby 等等,我們很難接觸到它的源代碼,不過我們可以通過 LevelDB 更好地了解這篇論文中提到的諸多內容和思量。
概述
LevelDB 作為一個鍵值存儲的『倉庫』,它提供了一組非常簡單的增刪改查接口:
class DB {
public:
virtual Status Put(const WriteOptions& options, const Slice& key, const Slice& value) = 0;
virtual Status Delete(const WriteOptions& options, const Slice& key) = 0;
virtual Status Write(const WriteOptions& options, WriteBatch* updates) = 0;
virtual Status Get(const ReadOptions& options, const Slice& key, std::string* value) = 0;
}
Put方法在內部最終會調用Write方法,只是在上層為調用者提供了兩個不同的選擇。
Get 和 Put 是 LevelDB 為上層提供的用於讀寫的接口,如果我們能夠對讀寫的過程有一個非常清晰的認知,那麽理解 LevelDB 的實現就不是那麽困難了。
在這一節中,我們將先通過對讀寫操作的分析了解整個工程中的一些實現,並在遇到問題和新的概念時進行解釋,我們會在這個過程中一步一步介紹 LevelDB 中一些重要模塊的實現以達到掌握它的原理的目標。
從寫操作開始
首先來看 Get 和 Put 兩者中的寫方法:
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
batch.Put(key, value);
return Write(opt, &batch);
}
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {
...
}
正如上面所介紹的,DB::Put 方法將傳入的參數封裝成了一個 WritaBatch,然後仍然會執行 DBImpl::Write 方法向數據庫中寫入數據;寫入方法 DBImpl::Write 其實是一個是非常復雜的過程,包含了很多對上下文狀態的判斷,我們先來看一個寫操作的整體邏輯:

從總體上看,LevelDB 在對數據庫執行寫操作時,會有三個步驟:
- 調用
MakeRoomForWrite方法為即將進行的寫入提供足夠的空間;- 在這個過程中,由於 memtable 中空間的不足可能會凍結當前的 memtable,發生 Minor Compaction 並創建一個新的
MemTable對象; - 在某些條件滿足時,也可能發生 Major Compaction,對數據庫中的 SSTable 進行壓縮;
- 在這個過程中,由於 memtable 中空間的不足可能會凍結當前的 memtable,發生 Minor Compaction 並創建一個新的
- 通過
AddRecord方法向日誌中追加一條寫操作的記錄; - 再向日誌成功寫入記錄後,我們使用
InsertInto直接插入 memtable 中,完成整個寫操作的流程;
在這裏,我們並不會提供 LevelDB 對於 Put 方法實現的全部代碼,只會展示一份精簡後的代碼,幫助我們大致了解一下整個寫操作的流程:
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {
Writer w(&mutex_);
w.batch = my_batch;
MakeRoomForWrite(my_batch == NULL);
uint64_t last_sequence = versions_->LastSequence();
Writer* last_writer = &w;
WriteBatch* updates = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(updates, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(updates);
log_->AddRecord(WriteBatchInternal::Contents(updates));
WriteBatchInternal::InsertInto(updates, mem_);
versions_->SetLastSequence(last_sequence);
return Status::OK();
}
不可變的 memtable
在寫操作的實現代碼 DBImpl::Put 中,寫操作的準備過程 MakeRoomForWrite 是我們需要註意的一個方法:
Status DBImpl::MakeRoomForWrite(bool force) {
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile* lfile = NULL;
env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
delete log_;
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
log_ = new log::Writer(lfile);
imm_ = mem_;
has_imm_.Release_Store(imm_);
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
MaybeScheduleCompaction();
return Status::OK();
}
當 LevelDB 中的 memtable 已經被數據填滿導致內存已經快不夠用的時候,我們會開始對 memtable 中的數據進行凍結並創建一個新的 MemTable 對象。
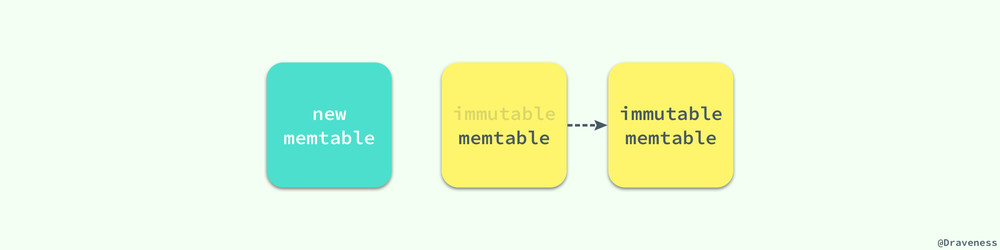
你可以看到,與 Bigtable 中論文不同的是,LevelDB 中引入了一個不可變的 memtable 結構 imm,它的結構與 memtable 完全相同,只是其中的所有數據都是不可變的。
在切換到新的 memtable 之後,還可能會執行 MaybeScheduleCompaction 來觸發一次 Minor Compaction 將 imm 中數據固化成數據庫中的 SSTable;imm 的引入能夠解決由於 memtable 中數據過大導致壓縮時不可寫入數據的問題。
引入 imm 後,如果 memtable 中的數據過多,我們可以直接將 memtable 指針賦值給 imm,然後創建一個新的 MemTable 實例,這樣就可以繼續接受外界的寫操作,不再需要等待 Minor Compaction 的結束了。
日誌記錄的格式
作為一個持久存儲的 KV 數據庫,LevelDB 一定要有日誌模塊以支持錯誤發生時恢復數據,我們想要深入了解 LevelDB 的實現,那麽日誌的格式是一定繞不開的問題;這裏並不打算展示用於追加日誌的方法 AddRecord 的實現,因為方法中只是實現了對表頭和字符串的拼接。
日誌在 LevelDB 是以塊的形式存儲的,每一個塊的長度都是 32KB,固定的塊長度也就決定了日誌可能存放在塊中的任意位置,LevelDB 中通過引入一位 RecordType 來表示當前記錄在塊中的位置:
enum RecordType {
// Zero is reserved for preallocated files
kZeroType = 0,
kFullType = 1,
// For fragments
kFirstType = 2,
kMiddleType = 3,
kLastType = 4
};
日誌記錄的類型存儲在該條記錄的頭部,其中還存儲了 4 字節日誌的 CRC 校驗、記錄的長度等信息:
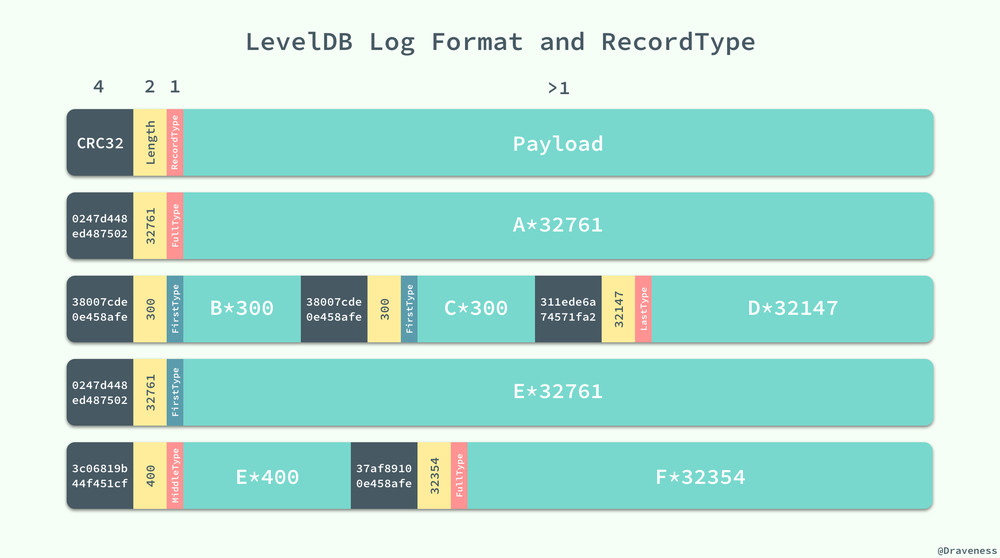
上圖中一共包含 4 個塊,其中存儲著 6 條日誌記錄,我們可以通過 RecordType 對每一條日誌記錄或者日誌記錄的一部分進行標記,並在日誌需要使用時通過該信息重新構造出這條日誌記錄。
virtual Status Sync() {
Status s = SyncDirIfManifest();
if (fflush_unlocked(file_) != 0 ||
fdatasync(fileno(file_)) != 0) {
s = Status::IOError(filename_, strerror(errno));
}
return s;
}
因為向日誌中寫新記錄都是順序寫的,所以它寫入的速度非常快,當在內存中寫入完成時,也會直接將緩沖區的這部分的內容 fflush 到磁盤上,實現對記錄的持久化,用於之後的錯誤恢復等操作。
記錄的插入
當一條數據的記錄寫入日誌時,這條記錄仍然無法被查詢,只有當該數據寫入 memtable 後才可以被查詢,而這也是這一節將要介紹的內容,無論是數據的插入還是數據的刪除都會向 memtable 中添加一條記錄。
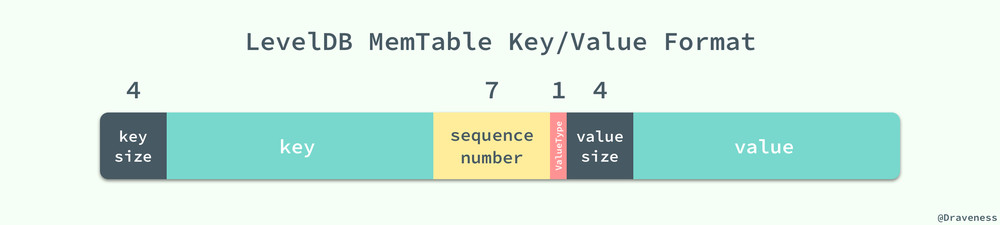
添加和刪除的記錄的區別就是它們使用了不用的 ValueType 標記,插入的數據會將其設置為 kTypeValue,刪除的操作會標記為 kTypeDeletion;但是它們實際上都向 memtable 中插入了一條數據。
virtual void Put(const Slice& key, const Slice& value) {
mem_->Add(sequence_, kTypeValue, key, value);
sequence_++;
}
virtual void Delete(const Slice& key) {
mem_->Add(sequence_, kTypeDeletion, key, Slice());
sequence_++;
}
我們可以看到它們都調用了 memtable 的 Add 方法,向其內部的數據結構 skiplist 以上圖展示的格式插入數據,這條數據中既包含了該記錄的鍵值、序列號以及這條記錄的種類,這些字段會在拼接後存入 skiplist;既然我們並沒有在 memtable 中對數據進行刪除,那麽我們是如何保證每次取到的數據都是最新的呢?首先,在 skiplist 中,我們使用了自己定義的一個 comparator:
int InternalKeyComparator::Compare(const Slice& akey, const Slice& bkey) const {
int r = user_comparator_->Compare(ExtractUserKey(akey), ExtractUserKey(bkey));
if (r == 0) {
const uint64_t anum = DecodeFixed64(akey.data() + akey.size() - 8);
const uint64_t bnum = DecodeFixed64(bkey.data() + bkey.size() - 8);
if (anum > bnum) {
r = -1;
} else if (anum < bnum) {
r = +1;
}
}
return r;
}
比較的兩個 key 中的數據可能包含的內容都不完全相同,有的會包含鍵值、序列號等全部信息,但是例如從
Get方法調用過來的 key 中可能就只包含鍵的長度、鍵值和序列號了,但是這並不影響這裏對數據的提取,因為我們只從每個 key 的頭部提取信息,所以無論是完整的 key/value 還是單獨的 key,我們都不會取到 key 之外的任何數據。
該方法分別從兩個不同的 key 中取出鍵和序列號,然後對它們進行比較;比較的過程就是使用 InternalKeyComparator 比較器,它通過 user_key 和 sequence_number 進行排序,其中 user_key 按照遞增的順序排序、sequence_number 按照遞減的順序排序,因為隨著數據的插入序列號是不斷遞增的,所以我們可以保證先取到的都是最新的數據或者刪除信息。

在序列號的幫助下,我們並不需要對歷史數據進行刪除,同時也能加快寫操作的速度,提升 LevelDB 的寫性能。
數據的讀取
從 LevelDB 中讀取數據其實並不復雜,memtable 和 imm 更像是兩級緩存,它們在內存中提供了更快的訪問速度,如果能直接從內存中的這兩處直接獲取到響應的值,那麽它們一定是最新的數據。
LevelDB 總會將新的鍵值對寫在最前面,並在數據壓縮時刪除歷史數據。
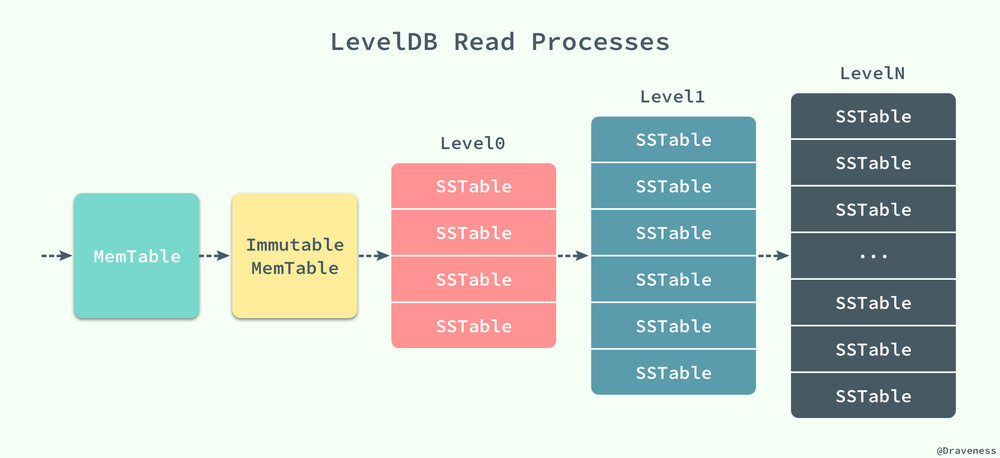
數據的讀取是按照 MemTable、Immutable MemTable 以及不同層級的 SSTable 的順序進行的,前兩者都是在內存中,後面不同層級的 SSTable 都是以 *.ldb 文件的形式持久存儲在磁盤上,而正是因為有著不同層級的 SSTable,所以我們的數據庫的名字叫做 LevelDB。
精簡後的讀操作方法的實現代碼是這樣的,方法的脈絡非常清晰,作者相信這裏也不需要過多的解釋:
Status DBImpl::Get(const ReadOptions& options, const Slice& key, std::string* value) {
LookupKey lkey(key, versions_->LastSequence());
if (mem_->Get(lkey, value, NULL)) {
// Done
} else if (imm_ != NULL && imm_->Get(lkey, value, NULL)) {
// Done
} else {
versions_->current()->Get(options, lkey, value, NULL);
}
MaybeScheduleCompaction();
return Status::OK();
}
當 LevelDB 在 memtable 和 imm 中查詢到結果時,如果查詢到了數據並不一定表示當前的值一定存在,它仍然需要判斷 ValueType 來確定當前記錄是否被刪除。
多層級的 SSTable
當 LevelDB 在內存中沒有找到對應的數據時,它才會到磁盤中多個層級的 SSTable 中進行查找,這個過程就稍微有一點復雜了,LevelDB 會在多個層級中逐級進行查找,並且不會跳過其中的任何層級;在查找的過程就涉及到一個非常重要的數據結構 FileMetaData:

FileMetaData 中包含了整個文件的全部信息,其中包括鍵的最大值和最小值、允許查找的次數、文件被引用的次數、文件的大小以及文件號,因為所有的 SSTable 都是以固定的形式存儲在同一目錄下的,所以我們可以通過文件號輕松查找到對應的文件。

查找的順序就是從低到高了,LevelDB 首先會在 Level0 中查找對應的鍵。但是,與其他層級不同,Level0 中多個 SSTable 的鍵的範圍有重合部分的,在查找對應值的過程中,會依次查找 Level0 中固定的 4 個 SSTable。
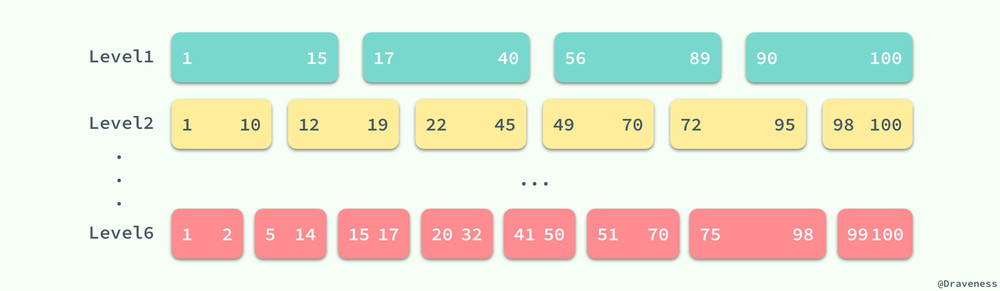
但是當涉及到更高層級的 SSTable 時,因為同一層級的 SSTable 都是沒有重疊部分的,所以我們在查找時可以利用已知的 SSTable 中的極值信息 smallest/largest 快速查找到對應的 SSTable,再判斷當前的 SSTable 是否包含查詢的 key,如果不存在,就繼續查找下一個層級直到最後的一個層級 kNumLevels(默認為 7 級)或者查詢到了對應的值。
SSTable 的『合並』
既然 LevelDB 中的數據是通過多個層級的 SSTable 組織的,那麽它是如何對不同層級中的 SSTable 進行合並和壓縮的呢;與 Bigtable 論文中描述的兩種 Compaction 幾乎完全相同,LevelDB 對這兩種壓縮的方式都進行了實現。
無論是讀操作還是寫操作,在執行的過程中都可能調用 MaybeScheduleCompaction 來嘗試對數據庫中的 SSTable 進行合並,當合並的條件滿足時,最終都會執行 BackgroundCompaction 方法在後臺完成這個步驟。
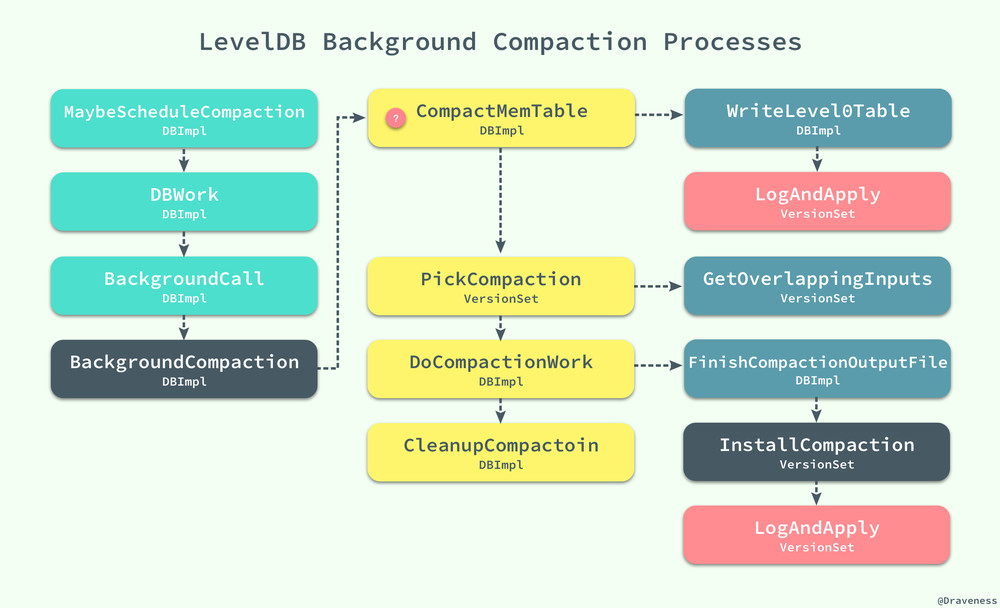
這種合並分為兩種情況,一種是 Minor Compaction,即內存中的數據超過了 memtable 大小的最大限制,改 memtable 被凍結為不可變的 imm,然後執行方法 CompactMemTable() 對內存表進行壓縮。
void DBImpl::CompactMemTable() {
VersionEdit edit;
Version* base = versions_->current();
WriteLevel0Table(imm_, &edit, base);
versions_->LogAndApply(&edit, &mutex_);
DeleteObsoleteFiles();
}
CompactMemTable 會執行 WriteLevel0Table 將當前的 imm 轉換成一個 Level0 的 SSTable 文件,同時由於 Level0 層級的文件變多,可能會繼續觸發一個新的 Major Compaction,在這裏我們就需要在這裏選擇需要壓縮的合適的層級:
Status DBImpl::WriteLevel0Table(MemTable* mem, VersionEdit* edit, Version* base) {
FileMetaData meta;
meta.number = versions_->NewFileNumber();
Iterator* iter = mem->NewIterator();
BuildTable(dbname_, env_, options_, table_cache_, iter, &meta);
const Slice min_user_key = meta.smallest.user_key();
const Slice max_user_key = meta.largest.user_key();
int level = base->PickLevelForMemTableOutput(min_user_key, max_user_key);
edit->AddFile(level, meta.number, meta.file_size, meta.smallest, meta.largest);
return Status::OK();
}
所有對當前 SSTable 數據的修改由一個統一的 VersionEdit 對象記錄和管理,我們會在後面介紹這個對象的作用和實現,如果成功寫入了就會返回這個文件的元數據 FileMetaData,最後調用 VersionSet 的方法 LogAndApply 將文件中的全部變化如實記錄下來,最後做一些數據的清理工作。
當然如果是 Major Compaction 就稍微有一些復雜了,不過整理後的 BackgroundCompaction 方法的邏輯非常清晰:
void DBImpl::BackgroundCompaction() {
if (imm_ != NULL) {
CompactMemTable();
return;
}
Compaction* c = versions_->PickCompaction();
CompactionState* compact = new CompactionState(c);
DoCompactionWork(compact);
CleanupCompaction(compact);
DeleteObsoleteFiles();
}
我們從當前的 VersionSet 中找到需要壓縮的文件信息,將它們打包存入一個 Compaction 對象,該對象需要選擇兩個層級的 SSTable,低層級的表很好選擇,只需要選擇大小超過限制的或者查詢次數太多的 SSTable;當我們選擇了低層級的一個 SSTable 後,就在更高的層級選擇與該 SSTable 有重疊鍵的 SSTable 就可以了,通過 FileMetaData 中數據的幫助我們可以很快找到待壓縮的全部數據。
查詢次數太多的意思就是,當客戶端調用多次
Get方法時,如果這次Get方法在某個層級的 SSTable 中找到了對應的鍵,那麽就算做上一層級中包含該鍵的 SSTable 的一次查找,也就是這次查找由於不同層級鍵的覆蓋範圍造成了更多的耗時,每個 SSTable 在創建之後的allowed_seeks都為 100 次,當allowed_seeks < 0時就會觸發該文件的與更高層級和合並,以減少以後查詢的查找次數。
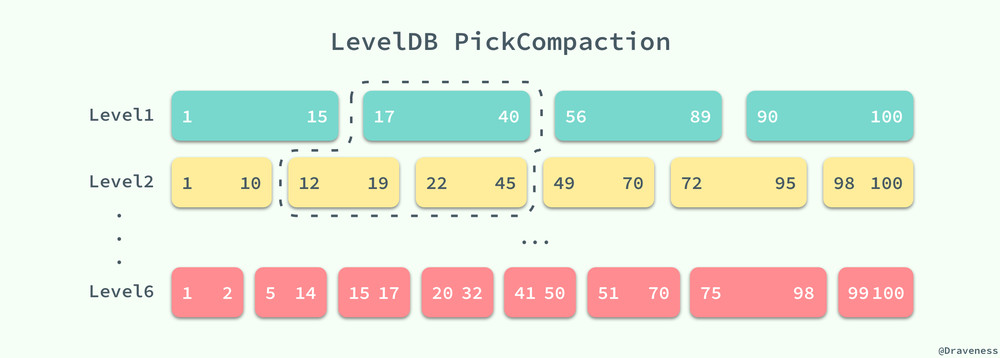
LevelDB 中的 DoCompactionWork 方法會對所有傳入的 SSTable 中的鍵值使用歸並排序進行合並,最後會在高高層級(圖中為 Level2)中生成一個新的 SSTable。
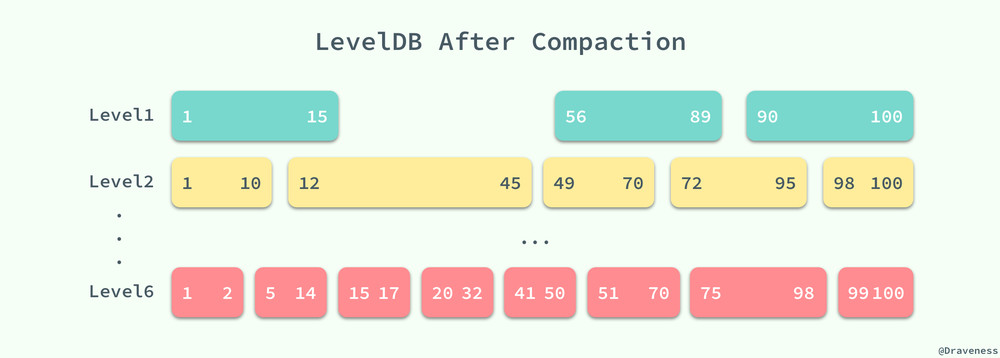
這樣下一次查詢 17~40 之間的值時就可以減少一次對 SSTable 中數據的二分查找以及讀取文件的時間,提升讀寫的性能。
存儲 db 狀態的 VersionSet
LevelDB 中的所有狀態其實都是被一個 VersionSet 結構所存儲的,一個 VersionSet 包含一組 Version 結構體,所有的 Version 包括歷史版本都是通過雙向鏈表連接起來的,但是只有一個版本是當前版本。
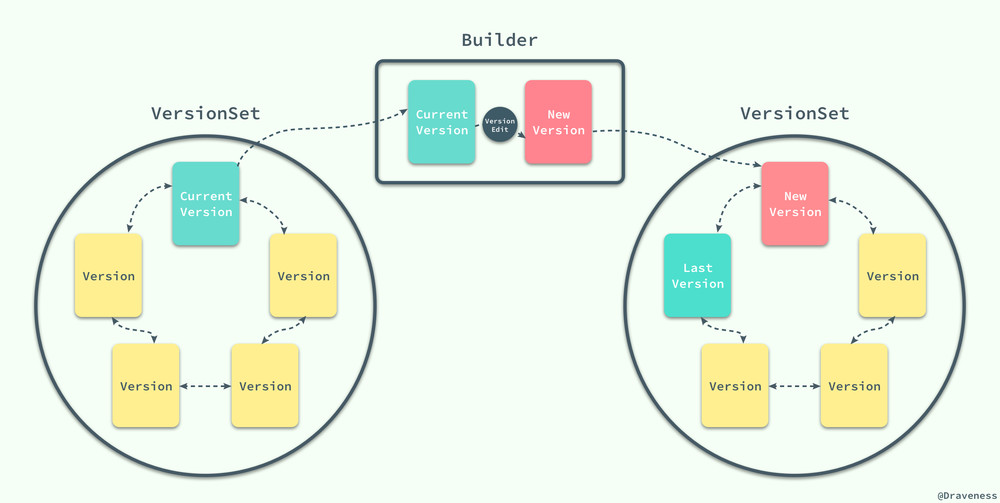
當 LevelDB 中的 SSTable 發生變動時,它會生成一個 VersionEdit 結構,最終執行 LogAndApply 方法:
Status VersionSet::LogAndApply(VersionEdit* edit, port::Mutex* mu) {
Version* v = new Version(this);
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
std::string new_manifest_file;
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
env_->NewWritableFile(new_manifest_file, &descriptor_file_);
std::string record;
edit->EncodeTo(&record);
descriptor_log_->AddRecord(record);
descriptor_file_->Sync();
SetCurrentFile(env_, dbname_, manifest_file_number_);
AppendVersion(v);
return Status::OK();
}
該方法的主要工作是使用當前版本和 VersionEdit 創建一個新的版本對象,然後將 Version 的變更追加到 MANIFEST 日誌中,並且改變數據庫中全局當前版本信息。
MANIFEST 文件中記錄了 LevelDB 中所有層級中的表、每一個 SSTable 的 Key 範圍和其他重要的元數據,它以日誌的格式存儲,所有對文件的增刪操作都會追加到這個日誌中。
SSTable 的格式
SSTable 中其實存儲的不只是數據,其中還保存了一些元數據、索引等信息,用於加速讀寫操作的速度,雖然在 Bigtable 的論文中並沒有給出 SSTable 的數據格式,不過在 LevelDB 的實現中,我們可以發現 SSTable 是以這種格式存儲數據的:
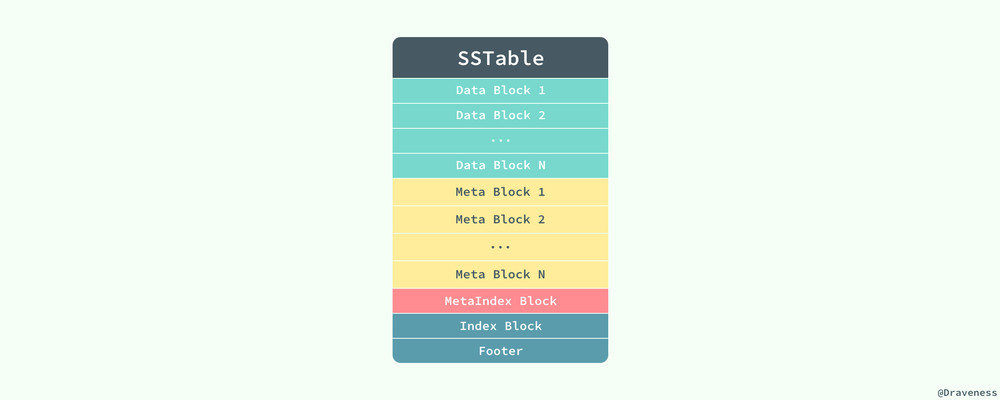
當 LevelDB 讀取 SSTable 存在的 ldb 文件時,會先讀取文件中的 Footer 信息。
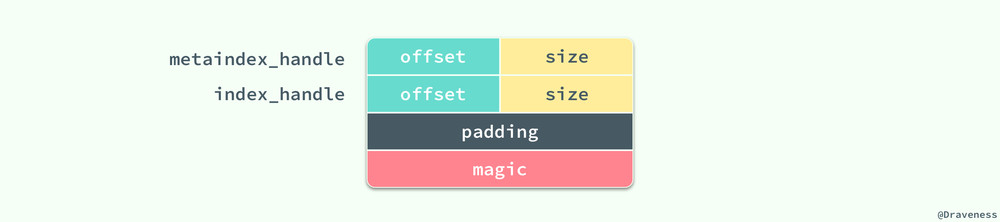
整個 Footer 在文件中占用 48 個字節,我們能在其中拿到 MetaIndex 塊和 Index 塊的位置,再通過其中的索引繼而找到對應值存在的位置。
TableBuilder::Rep 結構體中就包含了一個文件需要創建的全部信息,包括數據塊、索引塊等等:
struct TableBuilder::Rep {
WritableFile* file;
uint64_t offset;
BlockBuilder data_block;
BlockBuilder index_block;
std::string last_key;
int64_t num_entries;
bool closed;
FilterBlockBuilder* filter_block;
...
}
到這裏,我們就完成了對整個數據讀取過程的解析了;對於讀操作,我們可以理解為 LevelDB 在它內部的『多級緩存』中依次查找是否存在對應的鍵,如果存在就會直接返回,唯一與緩存不同可能就是,在數據『命中』後,它並不會把數據移動到更近的地方,而是會把數據移到更遠的地方來減少下一次的訪問時間,雖然這麽聽起來卻是不可思議,不過仔細想一下確實是這樣。
小結
在這篇文章中,我們通過對 LevelDB 源代碼中讀寫操作的分析,了解了整個框架的絕大部分實現細節,包括 LevelDB 中存儲數據的格式、多級 SSTable、如何進行合並以及管理版本等信息,不過由於篇幅所限,對於其中的一些問題並沒有展開詳細地進行介紹和分析,例如錯誤恢復以及緩存等問題;但是對 LevelDB 源代碼的閱讀,加深了我們對 Bigtable 論文中描述的分布式 KV 存儲數據庫的理解。
LevelDB 的源代碼非常易於閱讀,也是學習 C++ 語言非常優秀的資源,如果對文章的內容有疑問,可以在博客下面留言。
Reference
- Bigtable: A Distributed Storage System for Structured Data
- LevelDB
- The Chubby lock service for loosely-coupled distributed systems
- LevelDB · Impl
- leveldb 中的 SSTable
原文鏈接:淺析 Bigtable 和 LevelDB 的實現 · 面向信仰編程
Follow: Draveness · GitHub
淺析 Bigtable 和 LevelDB 的實現