
Hadoop:WordCount分析
阿新 • • 發佈:2017-12-21
詳細 tex string 實現 col 一個 mapper 信息 job
相關代碼:
1 package com.hadoop; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.Mapper; 9import org.apache.hadoop.mapreduce.Reducer; 10 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 13 import java.io.IOException; 14 import java.util.StringTokenizer; 15 16 public class WordCount { 17 18 19/** 20 * Mapper接口是個泛型類型,它有4個形式參數類型,分別指定map函數的輸入鍵、輸入值、輸出鍵和輸出值的類型。 21 * WordCount為例:輸入鍵是一個長整數偏移量,輸入的值是一行文本,輸出的鍵是單詞,輸出的值是單詞個數(整型) 22 * Hadoop規定了自己的一套用於網絡序列化的基本類型,而不直接使用Java內嵌的類型。這些類型在org.apache.hadoop.io包中。 23 * LongWritable類型相當於Java的Long類型 24 * Text類型相當於Java的String類型25 * IntWritable類型相當於Java的Integer類型 26 27 */ 28 public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { 29 30 private final static IntWritable one = new IntWritable(1); 31 private Text word = new Text(); 32 33 /** 34 * 35 * @param key 36 * @param value 37 * @param context 38 * @throws IOException 39 * @throws InterruptedException 40 * map( )方法的輸入是一個鍵和一個值。首先使用StringTokenizer類將輸入的Text值轉換成String類型,然後使用nextToken( )方法將單詞提取出來。 41 * map( )方法還提供Context實例用於輸出內容的寫入。將單詞數據按照Text類型進行讀寫,因為單詞作為鍵。將單詞數據數封裝為IntWritable類型。 42 */ 43 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 44 StringTokenizer itr = new StringTokenizer(value.toString()); // 有三個重載方法,這裏以空白字符(“ ”,“\t”,“\n”)為分隔符分割字符串 45 while (itr.hasMoreTokens()) { // 判斷是否還有分隔符 46 // set方法將String轉換成Text 47 // nextToken返回當前位置到下一個分隔符位置的字符串 48 word.set(itr.nextToken()); 49 context.write(word, one); // 使用Context實例用於輸出內容的寫入 50 } 51 } 52 } 53 54 /** 55 * reduce函數也有四個形式參數類型用於指定輸入和輸出類型。reduce函數的輸入類型必須匹配map函數的輸出類型:即Text類型和IntWritable類型。 56 */ 57 public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 58 private IntWritable result = new IntWritable(); 59 60 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 61 int sum = 0; 62 for (IntWritable val : values) { // 遍歷相同的key(單詞)對應的values,並進行相加 63 sum += val.get(); 64 } 65 result.set(sum); 66 context.write(key, result); // 將統計的數目賦給每一個不同的單詞 67 } 68 } 69 70 public static void main(String[] args) throws Exception { 71 /** 72 * Configuration類是作業的配置信息類,任何作用的配置信息必須通過Configuration傳遞, 73 * 因為通過Configuration可以實現在多個mapper和多個reducer任務之間共享信息。 74 */ 75 Configuration conf = new Configuration(); 76 Job job = Job.getInstance(conf, "word count"); //Job對象制定作業執行規範,用它來控制整個作業的運行。 77 78 /** 79 * 在Hadoop集群上運行這個作業時,要把代碼打包成一個JAR包,發布在集群上。 80 * 不必明確指定JAR文件的名稱,在Job對象的setJarByClass( )方法中傳遞一個類即可,Hadoop利用這個類查找包含它的JAR文件。 81 */ 82 job.setJarByClass(WordCount.class); 83 84 /** 85 * setMapperClass( ) 和setReducerClass( )方法指定要用的map類型和reduce類型 86 */ 87 job.setMapperClass(TokenizerMapper.class); 88 job.setReducerClass(IntSumReducer.class); 89 job.setCombinerClass(IntSumReducer.class); 90 91 92 /** 93 * setOutputKeyClass( ) 和setOutputValueClass( )方法控制reduce函數的輸出類型,必須要和Reduce類產生的相匹配。 94 * 輸入的類型沒有設置,因為使用了默認的TextInputFormat(文本輸入格式) 95 */ 96 job.setOutputKeyClass(Text.class); 97 job.setOutputValueClass(IntWritable.class); 98 99 /** 100 * FileInputFormat類的靜態方法addInputPath( )來指定輸入數據的路徑 101 * 該路徑可以是單個的文件、一個目錄或符合特定文件模式的一系列文件。 102 * ‘可以多次調用addInputPath( )來實現多路徑的輸入。 103 */ 104 FileInputFormat.addInputPath(job, new Path(args[0])); 105 106 /** 107 * FileOutputFormat類中的靜態方法setOutputPath( )來指定輸出路徑(只能有一個輸出路徑),即reduce函數輸出文件的寫入目錄。 108 * 在運行作業前該目錄不能存在,否則Hadoop會報錯並拒絕運行作業。 109 * 目的:防止數據丟失,假如一個作業運行了很久才得出結果,現在被另一個作業不小心覆蓋會令人崩潰。 110 */ 111 FileOutputFormat.setOutputPath(job, new Path(args[1])); 112 113 114 /** 115 * waitForCompletion( )方法提交作業並等待執行完成。該方法的唯一參數是一個標識,指示是否已生成詳細輸出。 116 */ 117 System.exit(job.waitForCompletion(true) ? 0 : 1); 118 } 119 }
運行結果:
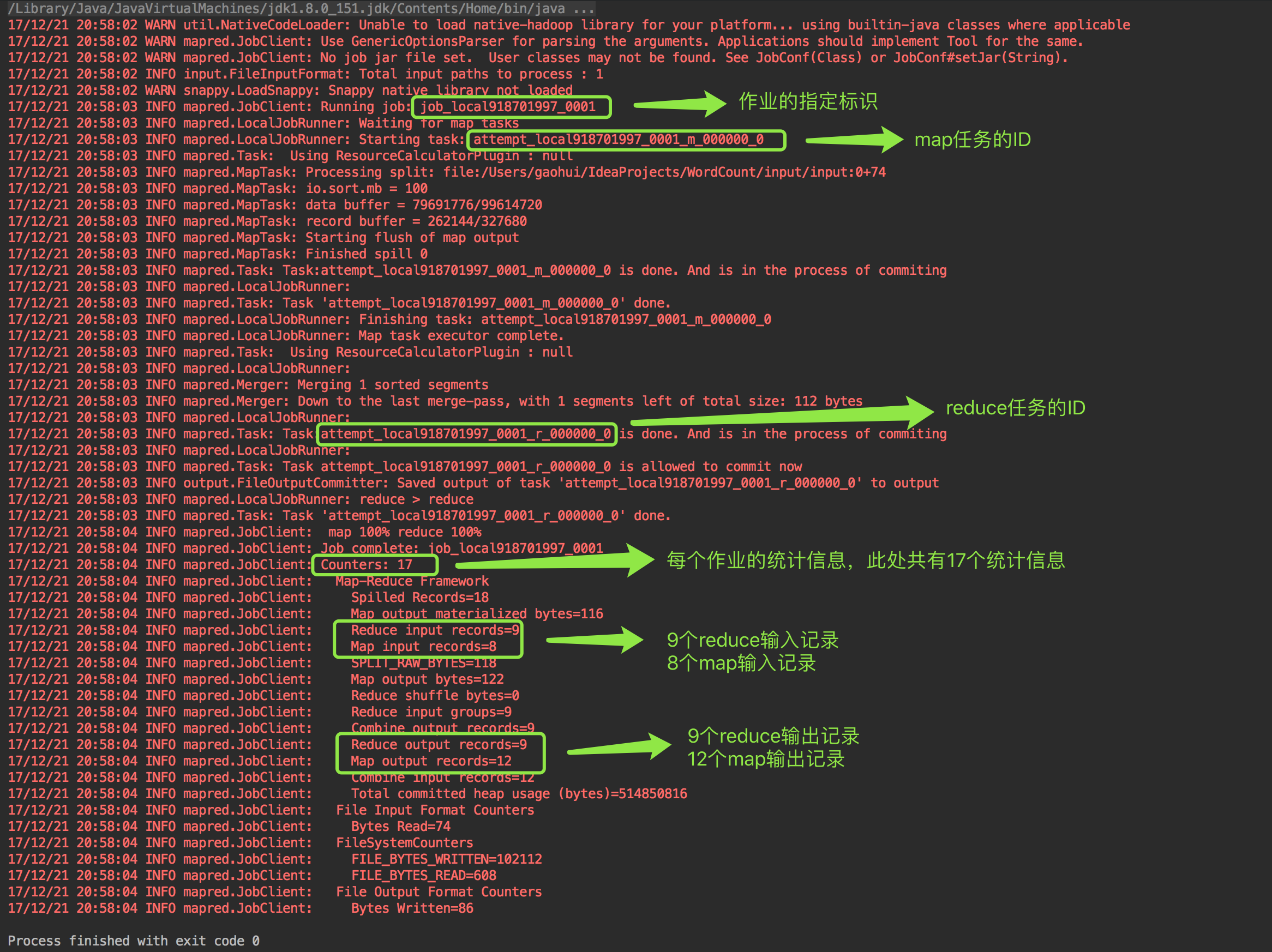
Hadoop:WordCount分析