
Hadoop-MapReduce計算案例1:WordCount
案例描述:計算一個檔案中每個單詞出現的數量
程式碼:
package com.jeff.mr.wordCount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 案例1 : * 在一個很大的檔案中含有一行行的單詞,每行的單詞以空格分隔,計算每個單詞出現的個數 * @author jeffSheng * 2018年9月18日 */ public class RunJob { public static void main(String[] args) { //初始化Configuration自動裝載src或者class下的配置檔案 Configuration config = new Configuration(); try { FileSystem fs =FileSystem.get(config); //建立執行的任務,靜態建立方式,傳入config Job job = Job.getInstance(config); //設定入口類,就是當前類 job.setJarByClass(RunJob.class); //設定job任務名稱 job.setJobName("wordCount"); //job任務執行時Map Task執行類 job.setMapperClass(WordCountMapper.class); //job任務執行時Reduce Task執行類 job.setReducerClass(WordCountReducer.class); //map Task輸出的key的型別,就是單詞 job.setMapOutputKeyClass(Text.class); //map Task輸出的value的型別,就是單詞出現數量 job.setMapOutputValueClass(IntWritable.class); //先指定mapTask輸入資料的目錄:/usr/input/ FileInputFormat.addInputPath(job, new Path("/usr/input/")); //指定輸出資料的目錄:/usr/output/wc Path outpath =new Path("/usr/output/wc"); //判斷目錄是否存在,存在則遞迴刪除 if(fs.exists(outpath)){ fs.delete(outpath, true); } //指定輸出資料的目錄 FileOutputFormat.setOutputPath(job, outpath); //等待job任務完成 boolean f= job.waitForCompletion(true); if(f){ System.out.println("job任務執行成功"); } } catch (Exception e) { e.printStackTrace(); } } }
package com.jeff.mr.wordCount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.util.StringUtils; /** * Map Task定義 * 計算檔案中單詞出現次數和預設第一階段洗牌 * @author jeffSheng * 2018年9月18日 * 繼承Mapper介面,泛型引數:<MapTask輸入資料key,MapTask輸入資料value,MapTask輸出資料key,MapTask輸出資料value> * Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> * * KEYIN, VALUEIN * mapTask輸入資料從檔案切割後的碎片段來的按照行去傳遞給MapTask,預設以資料行的下標為鍵值,型別為LongWritable,value為Text型別表示一行的資料 * * KEYOUT, VALUEOUT * mapTask的輸出資料以單詞為key,就是字串型別Text,value則是單詞的數量型別IntWritable * Mapper<LongWritable, Text, Text, IntWritable> */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ /** * 該map方法迴圈呼叫,從檔案的split碎片段中逐行即讀取每行則呼叫一次,把該行所在的下標為key,該行的內容為value */ protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //value是split的每一行的值,在本例子中是空格分隔的字串 String[] words = StringUtils.split(value.toString(), ' '); for(String word :words){ //輸出以單詞word為鍵,1作為值的鍵值對,這裡mapTask只是輸出資料,統計則是在reduceTask /** * 輸出資料會經歷第一階段洗牌,即分割槽,排序,合併,溢寫。這些在mapTask端有預設的操作 */ context.write(new Text(word), new IntWritable(1)); } } }
package com.jeff.mr.wordCount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * reduce Task定義 * mapTask第一階段洗牌完成後輸出資料傳給reduce Task進行第二階段的洗牌(分割槽,排序,分組)後作為reduce的輸入,資料型別一致。 * Tips:分組後,每一組資料傳給reduce Task,即每一組呼叫一次,這一組資料的特點是key相等,value可能是多個 * @author jeffSheng * 2018年9月18日 */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ //迴圈呼叫此方法,每組呼叫一次,這一組資料特點:key相同,value可能有多個。 /** * Text arg0: 鍵,就是每一組中的key,即某個單詞。 * Iterable<IntWritable> arg1: 迭代器中可以拿到每一組中的所有值去迭代 */ protected void reduce(Text arg0, Iterable<IntWritable> arg1,Context arg2) throws IOException, InterruptedException { int sum =0; for(IntWritable i: arg1){ sum=sum + i.get(); } //輸出以單詞為key,總和為value的鍵值對 arg2.write(arg0, new IntWritable(sum)); } }
當前active狀態的節點為node1,埠8020

將node1和8020設定到Map/Reduce Locations,新建一個location

紅框中填入node1和8020.hadoop的使用者為root

新建輸入檔案的路徑為/usr/input

剛開始發現建立的目錄不能成功,解決辦法是在hdfs-site.xml加入:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
重啟,即可解決!
#關閉全部節點
stop-dfs.sh
我們啟動node1:
#start-dfs.sh



上傳wc.txt檔案即輸入資料到hdfs的/usr/input下:
| hadooo hello world hello hadoop hbase zookeeper |




在實際生產環境中,計算程式是先提交給ResourceManager的,所以我們先把程式打成jar包:

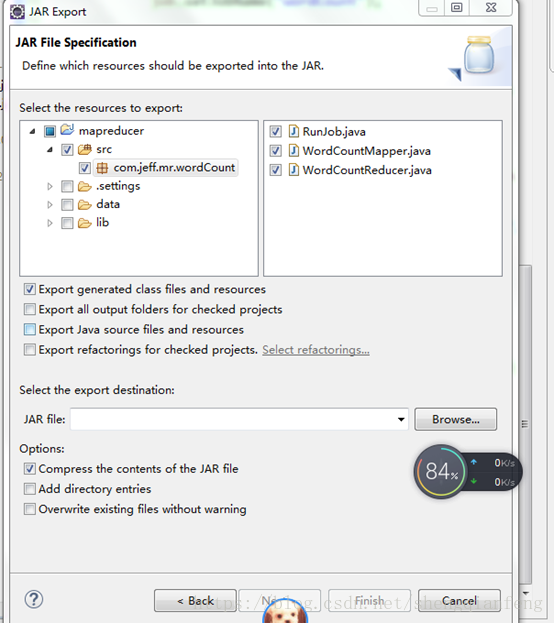


然後下一步,finish
然後我們把wc.jar上傳到我們的node4,注意node4不是我們的Resourcemanager的主節點,但是node4的配置檔案告訴我們了ResourceManager主節點node1的位置。



我們程式的入口類:
com.jeff.mr.wordCount.RunJob
# hadoop jar wc.jar com.jeff.mr.wordCount.RunJob

可以在監控介面看到計算進度:



執行日誌:
| [email protected] ~]# hadoop jar wc.jar com.jeff.mr.wordCount.RunJob
18/09/21 00:28:10 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2 18/09/21 00:28:10 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 18/09/21 00:28:11 INFO input.FileInputFormat: Total input paths to process : 1 18/09/21 00:28:11 INFO mapreduce.JobSubmitter: number of splits:1 18/09/21 00:28:11 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1537198202075_0002 18/09/21 00:28:12 INFO impl.YarnClientImpl: Submitted application application_1537198202075_0002 18/09/21 00:28:12 INFO mapreduce.Job: The url to track the job: http://node4:18088/proxy/application_1537198202075_0002/ 18/09/21 00:28:12 INFO mapreduce.Job: Running job: job_1537198202075_0002 18/09/21 00:28:38 INFO mapreduce.Job: Job job_1537198202075_0002 running in uber mode : false 18/09/21 00:28:38 INFO mapreduce.Job: map 0% reduce 0% 18/09/21 00:28:51 INFO mapreduce.Job: map 100% reduce 0% 18/09/21 00:29:04 INFO mapreduce.Job: map 100% reduce 100% 18/09/21 00:29:05 INFO mapreduce.Job: Job job_1537198202075_0002 completed successfully 18/09/21 00:29:05 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=96 FILE: Number of bytes written=198601 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=146 HDFS: Number of bytes written=54 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=11040 Total time spent by all reduces in occupied slots (ms)=9092 Total time spent by all map tasks (ms)=11040 Total time spent by all reduce tasks (ms)=9092 Total vcore-seconds taken by all map tasks=11040 Total vcore-seconds taken by all reduce tasks=9092 Total megabyte-seconds taken by all map tasks=11304960 Total megabyte-seconds taken by all reduce tasks=9310208 Map-Reduce Framework Map input records=3 Map output records=7 Map output bytes=76 Map output materialized bytes=96 Input split bytes=97 Combine input records=0 Combine output records=0 Reduce input groups=6 Reduce shuffle bytes=96 Reduce input records=7 Reduce output records=6 Spilled Records=14 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=214 CPU time spent (ms)=3550 Physical memory (bytes) snapshot=322617344 Virtual memory (bytes) snapshot=1724956672 Total committed heap usage (bytes)=136253440 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=49 File Output Format Counters Bytes Written=54 job任務執行成功 |
執行結果目錄/usr/output/wc下有兩個檔案:第一個_SUCCESS檔案是成功標識,第二個輸出結果檔案:

輸入檔案:

計算結果:
