
mapreduce 高級案例倒排索引
阿新 • • 發佈:2018-04-11
大數據 hadoop mapreduce 倒排索引
- 理解【倒排索引】的功能
- 熟悉mapreduce 中的combine 功能
- 根據需求編碼實現【倒排索引】的功能,旨在理解mapreduce 的功能。
一:理解【倒排索引】的功能
1.1 倒排索引:
由於不是根據文檔來確定文檔所包含的內容,而是進行相反的操作,因而稱為倒排索引
簡單來說根據單詞,返回它在哪個文件中出現過,而且頻率是多少的結果。例如:就像百度裏的搜索,你輸入一個關鍵字,那麽百度引擎就迅速的在它的服務器裏找到有該關鍵字的文件,並根據頻率和其他一些策略(如頁面點擊投票率)等來給你返回結果二:熟悉mapreduce 中的combine 功能
2.1 mapreduce的combine 功能
1 Map過程:Map過程首先分析輸入的<key,value>對,得到索引中需要的信息:單詞,文檔URI 和詞頻。key:單詞和URI.value:出現同樣單詞的次數。
2 Combine過程:經過map方法處理後,Combine過程將key值相同的value值累加,得到一個單詞在文檔中的詞頻。
3 Reduce過程:經過上述的倆個過程後,Reduce過程只需要將相同的key值的value值組合成倒排引索文件的格式即可,其余的事情直接交給MapReduce框架進行處理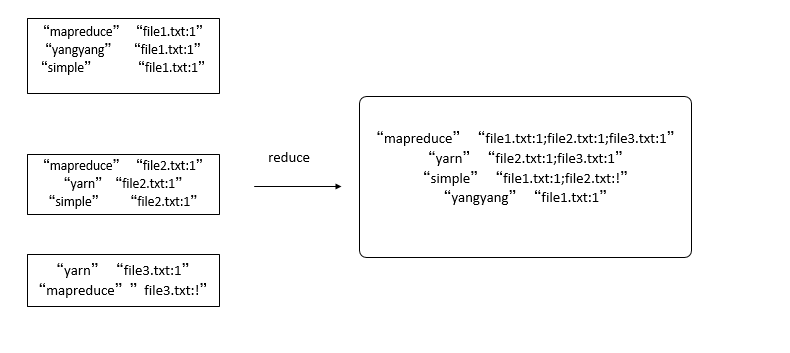
三:根據需求編碼實現【倒排索引】的功能,旨在理解mapreduce 的功能。
3.1 Java的編程代碼
InvertedIndexMapReduce.java package org.apache.hadoop.studyhadoop.index; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Mapper.Context; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * * @author zhangyy * */ public class InvertedIndexMapReduce extends Configured implements Tool { // step 1 : mapper /** * public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> */ public static class WordCountMapper extends // Mapper<LongWritable, Text, Text, Text> { private Text mapOutputKey = new Text(); private Text mapOutputValue = new Text("1"); @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // split1 String[] lines = value.toString().split("##"); // get url String url = lines[0]; // split2 String[] strs = lines[1].split(" "); for (String str : strs) { mapOutputKey.set(str + "," + url); context.write(mapOutputKey, mapOutputValue); } } } // set combiner class public static class InvertedIndexCombiner extends // Reducer<Text, Text, Text, Text> { private Text CombinerOutputKey = new Text(); private Text CombinerOutputValue = new Text(); @Override public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // split String[] strs = key.toString().split(","); // set key CombinerOutputKey.set(strs[0] + "\n"); // set value int sum = 0; for (Text value : values) { sum += Integer.valueOf(value.toString()); } CombinerOutputValue.set(strs[1] + ":" + sum); context.write(CombinerOutputKey, CombinerOutputValue); } } // step 2 : reducer public static class WordCountReducer extends // Reducer<Text, Text, Text, Text> { private Text outputValue = new Text(); @Override public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // TODO String result = new String(); for (Text value : values) { result += value.toString() + "\t"; } outputValue.set(result); context.write(key, outputValue); } } // step 3 : job public int run(String[] args) throws Exception { // 1 : get configuration Configuration configuration = super.getConf(); // 2 : create job Job job = Job.getInstance(// configuration,// this.getClass().getSimpleName()); job.setJarByClass(InvertedIndexMapReduce.class); // job.setNumReduceTasks(tasks); // 3 : set job // input --> map --> reduce --> output // 3.1 : input Path inPath = new Path(args[0]); FileInputFormat.addInputPath(job, inPath); // 3.2 : mapper job.setMapperClass(WordCountMapper.class); // TODO job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); // ====================shuffle========================== // 1: partition // job.setPartitionerClass(cls); // 2: sort // job.setSortComparatorClass(cls); // 3: combine job.setCombinerClass(InvertedIndexCombiner.class); // 4: compress // set by configuration // 5 : group // job.setGroupingComparatorClass(cls); // ====================shuffle========================== // 3.3 : reducer job.setReducerClass(WordCountReducer.class); // TODO job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); // 3.4 : output Path outPath = new Path(args[1]); FileOutputFormat.setOutputPath(job, outPath); // 4 : submit job boolean isSuccess = job.waitForCompletion(true); return isSuccess ? 0 : 1; } public static void main(String[] args) throws Exception { args = new String[] { "hdfs://namenode01.hadoop.com:8020/input/index.txt", "hdfs://namenode01.hadoop.com:8020/outputindex/" }; // get configuration Configuration configuration = new Configuration(); // configuration.set(name, value); // run job int status = ToolRunner.run(// configuration,// new InvertedIndexMapReduce(),// args); // exit program System.exit(status); } }
3.2 運行案例測試
上傳文件:
hdfs dfs -put index.txt /input
代碼運行結果:
輸出結果: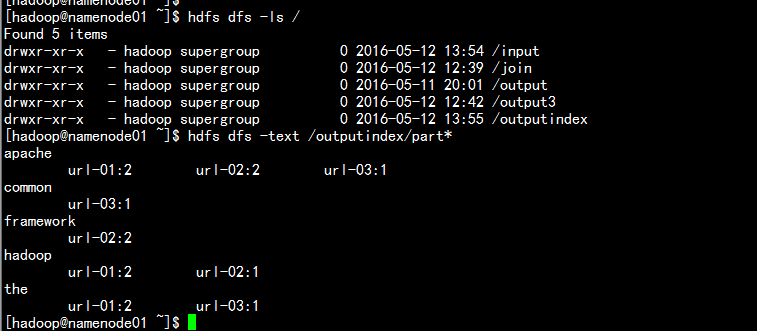
mapreduce 高級案例倒排索引