
MapReduce 案例之倒排索引
MapReduce 案例之倒排索引
1. 倒排索引
倒排索引是文件檢索系統中最常用的資料結構,被廣泛地應用於全文搜尋引擎。 它主要是用來儲存某個單詞(或片語) 在一個文件或一組文件中的儲存位置的對映,即提供了一種根據內容來查詢文件的方式。由於不是根據文件來確定文件所包含的內容,而是進行相反的操作,因而稱為倒排索引( Inverted Index)。
2. 例項描述
通常情況下,倒排索引由一個單詞(或片語)以及相關的文件列表組成,文件列表中的文件或者是標識文件的 ID 號,或者是指文件所在位置的 URL。如下圖所示:
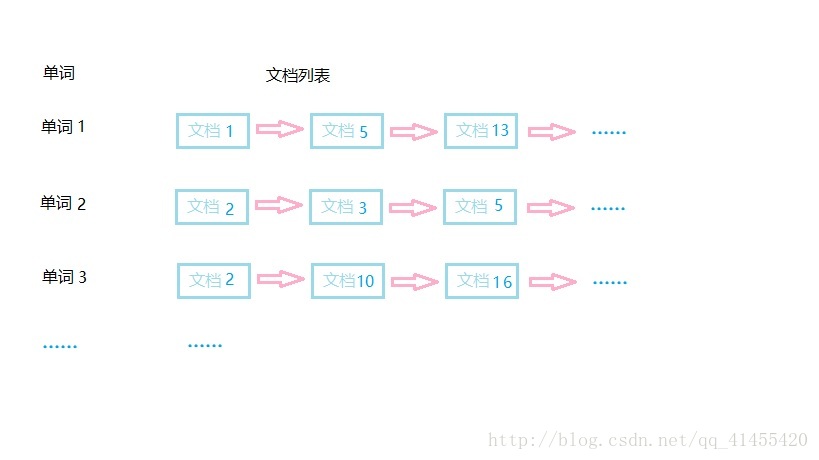
從上圖可以看出,單詞 1 出現在{文件 1,文件 5,文件 13, ……}中,單詞 2 出現在{文件 2,文件 3,文件 5, ……}中,而單詞 3 出現在{文件 2,文件 10,文件 16, ……}中。在實際應用中,還需要給每個文件新增一個權值,用來指出每個文件與搜尋內容的相關度,如下圖所示:
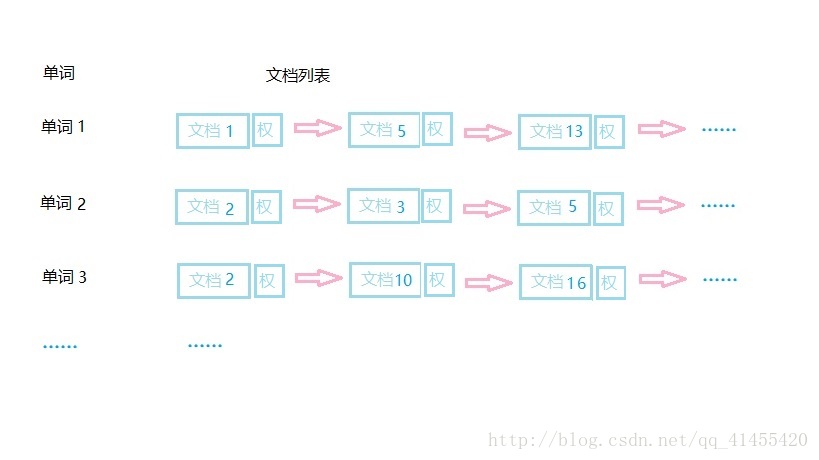
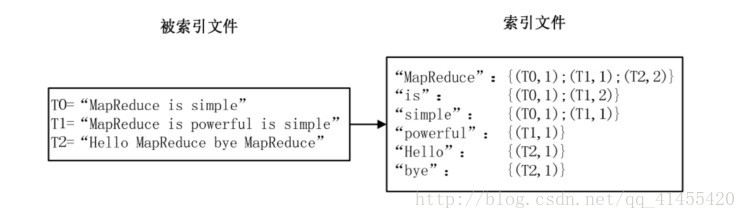
最常用的是使用詞頻作為權重,即記錄單詞在文件中出現的次數。以英文為例,如下圖所示,索引檔案中的“ MapReduce”一行表示:“ MapReduce”這個單詞在文字 T0 中 出現過 1 次,T1 中出現過 1 次,T2 中出現過 2 次。當搜尋條件為“ MapReduce”、“ is”、“ Simple” 時,對應的集合為: {T0, T1, T2}∩{T0, T1}∩{T0, T1}={T0, T1},即文件 T0 和 T1 包 含了所要索引的單詞,而且只有 T0 是連續的。
3. 設計思路
3.1 Map過程
首先使用預設的 TextInputFormat 類對輸入檔案進行處理,得到文字中每行的偏移量及其內容。顯然, Map 過程首先必須分析輸入的key/value對,得到倒排索引中需要的三個資訊:單詞、文件 URL 和詞頻,如下圖所示。
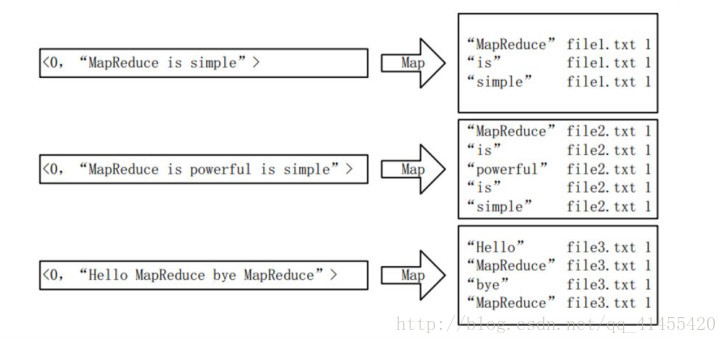
這裡存在兩個問題:第一, key/value對只能有兩個值,在不使用Hadoop 自定義資料型別的情況下,需要根據情況將其中兩個值合併成一個值,作為 key 或 value 值;
第二,通過一個 Reduce 過程無法同時完成詞頻統計和生成文件列表,所以必須增加一個 Combine 過程完成詞頻統計。
這裡將單詞和 URL 組成 key 值(如“ MapReduce: file1.txt”),將詞頻作為value,這樣做的好處是可以利用 MapReduce 框架自帶的Map 端排序,將同一文件的相同單詞的詞頻組成列表,傳遞給 Combine 過程,實現類似於 WordCount 的功能。
3.2 Combine 過程
經過 map 方法處理後, Combine 過程將 key 值相同 value 值累加,得到一個單詞在文件中的詞頻。 如果直接將圖所示的輸出作為 Reduce 過程的輸入,在 Shuffle 過程時將面臨一個問題:所有具有相同單詞的記錄(由單詞、 URL 和詞頻組成)應該交由同一個Reducer 處理,但當前的 key 值無法保證這一點,所以必須修改 key 值和 value 值。這次將單詞作為 key 值, URL 和詞頻組成 value 值(如“ file1.txt: 1”)。這樣做的好處是可以利用 MapReduce 框架預設的 HashPartitioner 類完成 Shuffle 過程,將相同單詞的所有記錄傳送給同一個 Reducer 進行處理。
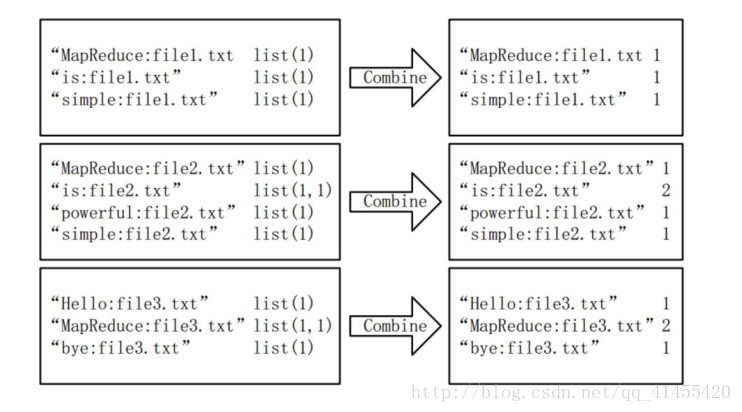
3.3 Reduce 過程
經過上述兩個過程後, Reduce 過程只需將相同 key 值的 value 值組合成倒排索引檔案所需的格式即可,剩下的事情就可以直接交給 MapReduce 框架進行處理了。
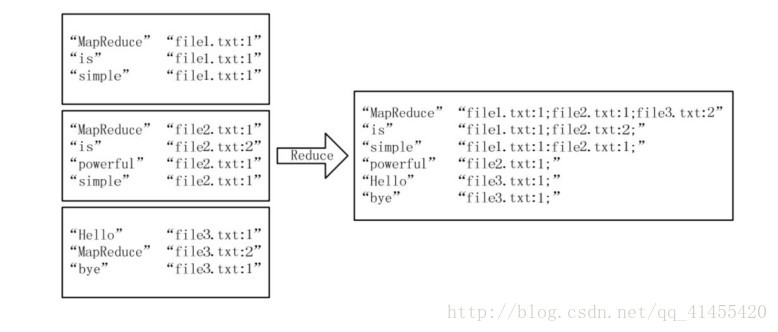
3.4 程式程式碼
- Map程式
package cn.demo.hadoop.mr.invertedIndex;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text>{
private static Text keyInfo = new Text();// 儲存單詞和 URL 組合
private static final Text valueInfo = new Text("1");// 儲存詞頻,初始化為1
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split(" ");// 得到欄位陣列
FileSplit fileSplit = (FileSplit) context.getInputSplit();// 得到這行資料所在的檔案切片
String fileName = fileSplit.getPath().getName();// 根據檔案切片得到檔名
for (String field : fields) {
// key值由單詞和URL組成,如“MapReduce:file1”
keyInfo.set(field + ":" + fileName);
context.write(keyInfo, valueInfo);
}
}
}
- combine程式
package cn.demo.hadoop.mr.invertedIndex;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text>{
private static Text info = new Text();
// 輸入: <MapReduce:file3 {1,1,...}>
// 輸出:<MapReduce file3:2>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int sum = 0;// 統計詞頻
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int splitIndex = key.toString().indexOf(":");
// 重新設定 value 值由 URL 和詞頻組成
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
// 重新設定 key 值為單詞
key.set(key.toString().substring(0, splitIndex));
context.write(key, info);
}
}- reduce程式
package cn.demo.hadoop.mr.invertedIndex;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text>{
private static Text result = new Text();
// 輸入:<MapReduce file3:2>
// 輸出:<MapReduce file1:1;file2:1;file3:2;>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 生成文件列表
String fileList = new String();
for (Text value : values) {
fileList += value.toString() + ";";
}
result.set(fileList);
context.write(key, result);
}
}- 主程式
package cn.demo.hadoop.mr.invertedIndex;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InvertedIndexRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(InvertedIndexRunner.class);
job.setMapperClass(InvertedIndexMapper.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("D:\\ziliao\\data\\InvertedIndex\\input"));
// 指定處理完成之後的結果所儲存的位置
FileOutputFormat.setOutputPath(job, new Path("D:\\ziliao\\data\\InvertedIndex\\output"));
// 向 yarn 叢集提交這個 job
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}