
k-means+python︱scikit-learn中的KMeans聚類實現( + MiniBatchKMeans)
之前一直用R,現在開始學python之後就來嘗試用Python來實現Kmeans。
之前用R來實現kmeans的博客:筆記︱多種常見聚類模型以及分群質量評估(聚類註意事項、使用技巧)
聚類分析在客戶細分中極為重要。有三類比較常見的聚類模型,K-mean聚類、層次(系統)聚類、最大期望EM算法。在聚類模型建立過程中,一個比較關鍵的問題是如何評價聚類結果如何,會用一些指標來評價。
.
一、scikit-learn中的Kmeans介紹
scikit-learn 是一個基於Python的Machine Learning模塊,裏面給出了很多Machine
Learning相關的算法實現,其中就包括K-Means算法。
官網scikit-learn案例地址:http://scikit-learn.org/stable/modules/clustering.html#k-means
部分來自:scikit-learn 源碼解讀之Kmeans——簡單算法復雜的說
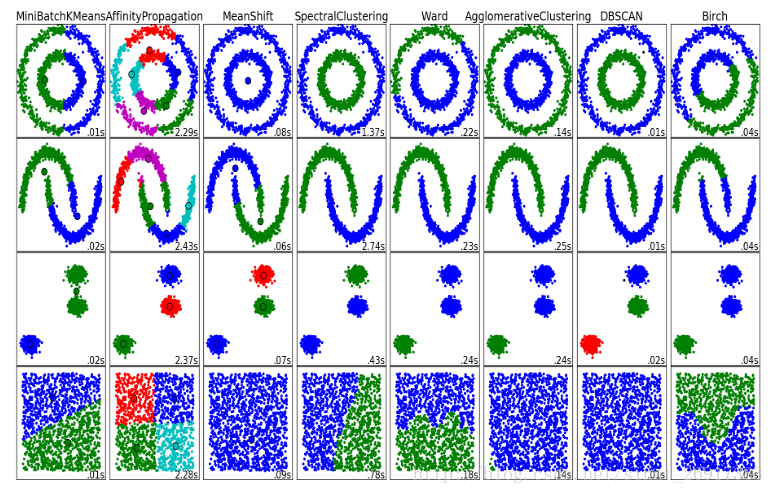
各個聚類的性能對比:
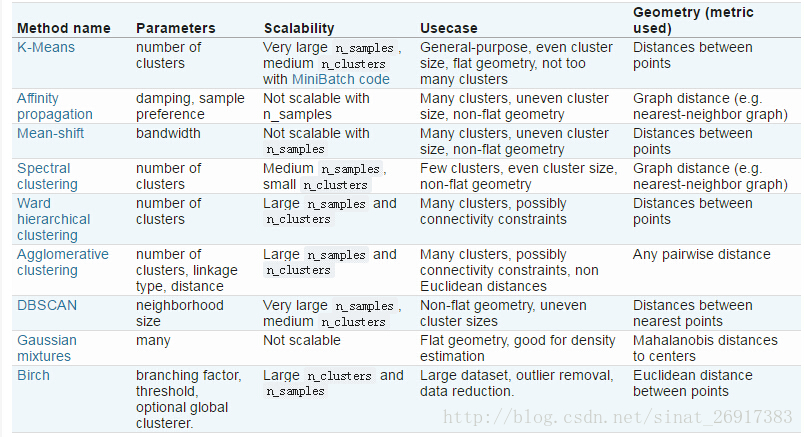
優點:
原理簡單
速度快
對大數據集有比較好的伸縮性
缺點:
需要指定聚類 數量K
對異常值敏感
對初始值敏感- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1、相關理論
參考:K-means算法及文本聚類實踐
- (1)中心點的選擇
k-meams算法的能夠保證收斂,但不能保證收斂於全局最優點,當初始中心點選取不好時,只能達到局部最優點,整個聚類的效果也會比較差。可以采用以下方法:k-means中心點
選擇彼此距離盡可能遠的那些點作為中心點;
先采用層次進行初步聚類輸出k個簇,以簇的中心點的作為k-means的中心點的輸入。
多次隨機選擇中心點訓練k-means,選擇效果最好的聚類結果
- (2)k值的選取
k-means的誤差函數有一個很大缺陷,就是隨著簇的個數增加,誤差函數趨近於0,最極端的情況是每個記錄各為一個單獨的簇,此時數據記錄的誤差為0,但是這樣聚類結果並不是我們想要的,可以引入結構風險對模型的復雜度進行懲罰:
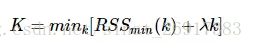
λλ是平衡訓練誤差與簇的個數的參數,但是現在的問題又變成了如何選取λλ了,有研究[參考文獻1]指出,在數據集滿足高斯分布時,λ=2mλ=2m,其中m是向量的維度。
另一種方法是按遞增的順序嘗試不同的k值,同時畫出其對應的誤差值,通過尋求拐點來找到一個較好的k值,詳情見下面的文本聚類的例子。
2、主函數KMeans
參考博客:python之sklearn學習筆記
來看看主函數KMeans:
sklearn.cluster.KMeans(n_clusters=8,
init=‘k-means++‘,
n_init=10,
max_iter=300,
tol=0.0001,
precompute_distances=‘auto‘,
verbose=0,
random_state=None,
copy_x=True,
n_jobs=1,
algorithm=‘auto‘
)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
參數的意義:
- n_clusters:簇的個數,即你想聚成幾類
- init: 初始簇中心的獲取方法
- n_init: 獲取初始簇中心的更叠次數,為了彌補初始質心的影響,算法默認會初始10次質心,實現算法,然後返回最好的結果。
- max_iter: 最大叠代次數(因為kmeans算法的實現需要叠代)
- tol: 容忍度,即kmeans運行準則收斂的條件
- precompute_distances:是否需要提前計算距離,這個參數會在空間和時間之間做權衡,如果是True 會把整個距離矩陣都放到內存中,auto 會默認在數據樣本大於featurs*samples 的數量大於12e6 的時候False,False 時核心實現的方法是利用Cpython 來實現的
- verbose: 冗長模式(不太懂是啥意思,反正一般不去改默認值)
- random_state: 隨機生成簇中心的狀態條件。
- copy_x: 對是否修改數據的一個標記,如果True,即復制了就不會修改數據。bool 在scikit-learn 很多接口中都會有這個參數的,就是是否對輸入數據繼續copy 操作,以便不修改用戶的輸入數據。這個要理解Python 的內存機制才會比較清楚。
- n_jobs: 並行設置
- algorithm: kmeans的實現算法,有:’auto’, ‘full’, ‘elkan’, 其中 ‘full’表示用EM方式實現
雖然有很多參數,但是都已經給出了默認值。所以我們一般不需要去傳入這些參數,參數的。可以根據實際需要來調用。
3、簡單案例一
參考博客:python之sklearn學習筆記
本案例說明了,KMeans分析的一些類如何調取與什麽意義。
import numpy as np
from sklearn.cluster import KMeans
data = np.random.rand(100, 3) #生成一個隨機數據,樣本大小為100, 特征數為3
#假如我要構造一個聚類數為3的聚類器
estimator = KMeans(n_clusters=3)#構造聚類器
estimator.fit(data)#聚類
label_pred = estimator.labels_ #獲取聚類標簽
centroids = estimator.cluster_centers_ #獲取聚類中心
inertia = estimator.inertia_ # 獲取聚類準則的總和- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
estimator初始化Kmeans聚類;estimator.fit聚類內容擬合;
estimator.label_聚類標簽,這是一種方式,還有一種是predict;estimator.cluster_centers_聚類中心均值向量矩陣
estimator.inertia_代表聚類中心均值向量的總和
4、案例二
案例來源於:使用scikit-learn進行KMeans文本聚類
from sklearn.cluster import KMeans
num_clusters = 3
km_cluster = KMeans(n_clusters=num_clusters, max_iter=300, n_init=40, init=‘k-means++‘,n_jobs=-1)
#返回各自文本的所被分配到的類索引
result = km_cluster.fit_predict(tfidf_matrix)
print "Predicting result: ", result- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
km_cluster是KMeans初始化,其中用init的初始值選擇算法用’k-means++’;
km_cluster.fit_predict相當於兩個動作的合並:km_cluster.fit(data)+km_cluster.predict(data),可以一次性得到聚類預測之後的標簽,免去了中間過程。
- n_clusters: 指定K的值
- max_iter: 對於單次初始值計算的最大叠代次數
- n_init: 重新選擇初始值的次數
- init: 制定初始值選擇的算法
- n_jobs: 進程個數,為-1的時候是指默認跑滿CPU
- 註意,這個對於單個初始值的計算始終只會使用單進程計算,
- 並行計算只是針對與不同初始值的計算。比如n_init=10,n_jobs=40,
- 服務器上面有20個CPU可以開40個進程,最終只會開10個進程
其中:
km_cluster.labels_
km_cluster.predict(data)- 1
- 2
這是兩種聚類結果標簽輸出的方式,結果貌似都一樣。都需要先km_cluster.fit(data),然後再調用。
5、案例四——Kmeans的後續分析
Kmeans算法之後的一些分析,參考來源:用Python實現文檔聚類
from sklearn.cluster import KMeans
num_clusters = 5
km = KMeans(n_clusters=num_clusters)
%time km.fit(tfidf_matrix)
clusters = km.labels_.tolist()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分為五類,同時用%time來測定運行時間,把分類標簽labels格式變為list。
- (1)模型保存與載入
from sklearn.externals import joblib
# 註釋語句用來存儲你的模型
joblib.dump(km, ‘doc_cluster.pkl‘)
km = joblib.load(‘doc_cluster.pkl‘)
clusters = km.labels_.tolist()- 1
- 2
- 3
- 4
- 5
- 6
- (2)聚類類別統計
frame = pd.DataFrame(films, index = [clusters] , columns = [‘rank‘, ‘title‘, ‘cluster‘, ‘genre‘])
frame[‘cluster‘].value_counts()- 1
- 2
- (3)質心均值向量計算組內平方和
選擇更靠近質心的點,其中 km.cluster_centers_代表著一個 (聚類個數*維度數),也就是不同聚類、不同維度的均值。
該指標可以知道:
一個類別之中的,那些點更靠近質心;
整個類別組內平方和。
類別內的組內平方和要參考以下公式: 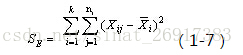
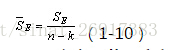
通過公式可以看出:
質心均值向量每一行數值-每一行均值(相當於均值的均值)
註意是平方。其中,n代表樣本量,k是聚類數量(譬如聚類5)
其中,整篇的組內平方和可以通過來獲得總量:
km.inertia_k-means+python︱scikit-learn中的KMeans聚類實現( + MiniBatchKMeans)