
《Enhanced LSTM for Natural Language Inference》(自然語言推理)
阿新 • • 發佈:2018-05-28
nta posit red mask 顯示 del sim repr ret
解決的問題
自然語言推理,判斷a是否可以推理出b。簡單講就是判斷2個句子ab是否有相同的含義。
方法
我們的自然語言推理網絡由以下部分組成:輸入編碼(Input Encoding ),局部推理模型(Local Inference Modeling ),和推斷合成(inference composition)。結構圖如下所示:
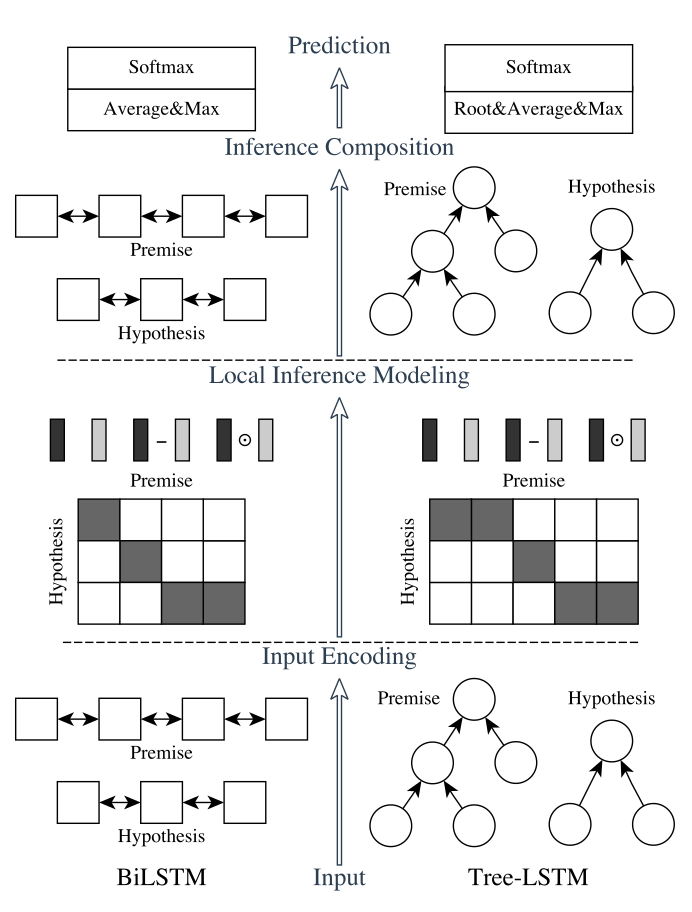
垂直來看,上圖顯示了系統的三個主要組成部分;水平來看,左邊代表稱為ESIM的序列NLI模型,右邊代表包含了句法解析信息的樹形LSTM網絡。
輸入編碼
1 # Based on arXiv:1609.06038 2 q1 = Input(name=‘q1‘, shape=(maxlen,)) 3 q2 = Input(name=‘q2‘, shape=(maxlen,)) 4 5 # Embedding 6 embedding = create_pretrained_embedding( 7 pretrained_embedding, mask_zero=False) 8 bn = BatchNormalization(axis=2) 9 q1_embed = bn(embedding(q1)) 10 q2_embed = bn(embedding(q2)) 11 12# Encode 13 encode = Bidirectional(LSTM(lstm_dim, return_sequences=True)) 14 q1_encoded = encode(q1_embed) 15 q2_encoded = encode(q2_embed)
有2種lstm:
A: sequential model 的做法
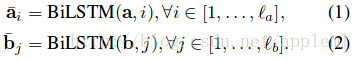
句子中的每個詞都有了包含周圍信息的 word representation
B: Tree-LSTM model的做法
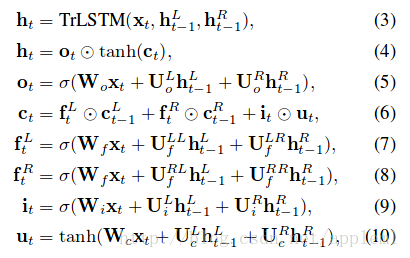
樹中的每個節點(短語或字句)有了向量表示 htt
關於tree-LSTM 的介紹需要看文章:
[1] Improved semantic representations from tree-structured long short-term memory networks
[2] Natural Language inference by tree-based convolution and heuristic matching
[3] Long short-term memory over recursive structures
第二部分:Local Inference Modeling
A: sequential model
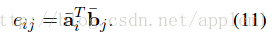
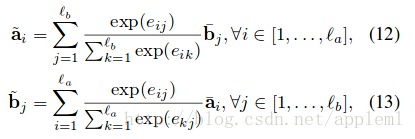
兩句話相似或相反的對應
B: Tree-LSTM model
兩棵樹任意兩個節點利用公式(11)計算
《Enhanced LSTM for Natural Language Inference》(自然語言推理)