
計算機視覺從入門到放肆
計算機視覺從入門到放肆
一、基礎知識
1.1 計算機視覺到底是什麽?
計算機視覺是一門研究如何讓機器“看”的科學
更進一步的說,就是使用攝像機和電腦代替人眼對目標進行識別、跟蹤和測量等機器視覺,並進一步做圖形處理,使電腦處理成為更適合人眼觀察或傳送給儀器檢測的圖像。
作為一門科學學科,計算機視覺研究相關的理論和技術,視圖建立能夠從圖像或者多維數據中獲取’信息’的人工智能系統。
1.2 圖像
當程序在讀取一張圖片時,需要考慮以下數據:
-
高度、寬度
假如一張照片的分辨率為:1920*1080(單位為dpi,全稱為 dot per inch),1920 就是照片的寬度,1080 就是圖片的高度。
-
深度
存儲每個像素所用的位數,比如正常RGB的深度就是 2^8 * 3 = 256 * 3 = 768 , 那麽此類圖片中的深度為768,每個像素點都能夠代表768中顏色。
-
通道數
RGB圖片就是有三通道,RGBA類圖片就是有四通道
-
顏色格式
是將某種顏色表現為數字形式的模型,或者說是一種記錄圖像顏色的方式。比較常見的有:RGB模式、RGBA模式、CMYK模式、位圖模式、灰度模式、索引顏色模式、雙色調模式和多通道模式。
-
more
圖像中的知識點太多,做基本圖像處理,了解以上知識個人感覺可以了。等到以後如果做深入研究,或許有機會做更多的學習
1.3 視頻
原始視頻 = 圖片序列,視頻中的每張有序圖片被稱為“幀(frame)”。壓縮後的視頻,會采取各種算法減少數據的容量,其中IPB就是最常見的。
-
碼率
數據傳輸時單位時間傳送的數據位數,通俗一點的理解就是取樣率,單位時間取樣率越大,精度就越高,即分辨率越高
-
幀率
每秒傳輸的幀數,fps(有沒有一種似曾相識的感覺~~~),全稱為 frames per second
-
分辨率
每幀圖片的分辨率
-
清晰度
平常看片中,有不同清晰度,實際上就對應著不同的分辨率
-
IPB
在網絡視頻流中,並不是把每一幀圖片全部發送到客戶端來展示,而是傳輸每一幀的差別數據(IPB),客戶端然後對其進行解析,最終補充每一幀完整圖片
1.4 攝像機
在實際應用當中,基本上都是通過不同種類的攝像機來獲取數據,然後發送給服務端(AI Server)進行處理,分類有:
- 監控攝像機(網絡攝像機和模擬攝像機)
- 行業攝像機(超快動態攝像機、紅外攝像機、熱成像攝像機等)
- 智能攝像機
- 工業攝像機
1.5 CPU和GPU
我想大家肯定是知道,目前很多人工智能計算都遷移到GPU上進行,tensorflow甚至還有cpu和gpu版本,所以其兩者的差別和使用方法,這是繞不開的問題。
廢話少說,先來上圖:
-
架構上的對比
- 綠色:計算單元
- 橙紅色:存儲單元
- 橙黃色:控制單元
-
整體對比
- Cache、Local Memory : CPU > GPU
- Threads(線程數):GPU > CPU
- Registers(寄存器):GPU > CPU
- SIMD Unit(單指令多數據流):GPU > CPU
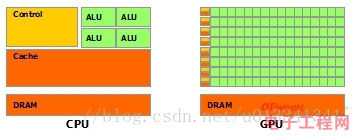
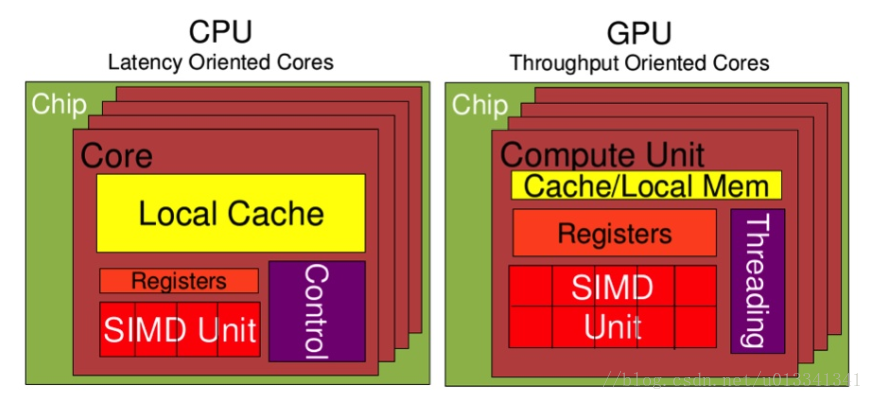
CPU在設計上,低延遲,可是低吞吐量,CPU的ALU(算數運算單元)雖然少,可是很強大,可以在很少的時鐘周期內完成算數計算,或許數量少,就可以任性的減少時鐘周期,所以其頻率非常高,能夠達到1.532 ~ 3 (千兆,10的9次方)。
大緩存容量、復雜的邏輯控制單元也可以減低延遲。
GPU在設計上,高延遲,可是高吞吐量。GPU的特點是有很多的ALU和很少的cache. 緩存的目的不是保存後面需要訪問的數據的,這點和CPU不同,而是為thread提高服務的。如果有很多線程需要訪問同一個相同的數據,緩存會合並這些訪問,然後再去訪問dram(因為需要訪問的數據保存在dram中而不是cache裏面),獲取數據後cache會轉發這個數據給對應的線程,這個時候是數據轉發的角色。但是由於需要訪問dram,自然會帶來延時的問題。
參考鏈接
-
Cuda (Compute Unified Device Architecture)
是顯卡廠商NVIDIA推出的運算平臺,采用並行計算架構,是GPU能夠解決復雜的計算問題。包含了CUDA指令集架構以及GPU內部的並行計算引擎。
安裝教程自行搜索腦補就行。
1.6 編程語言 + 數學基礎
-
python
推薦作為入門語言,簡單容易上手,需要了解一些庫:numpy、pandas、matplotlib等。
-
C++
作為深入了解並嘗試進行優化,C++必不可少,也是編寫並修改的最佳語言。當然,如果你了解C、Matlab等語言那也是甚好的。
-
線性代數
可以把重點放在矩陣運算上。
-
概率統計
了解基本概率統計知識、高斯分布、中值、標準差和方差等概念。
-
MachineLearning
能夠用公式表示代價函數、使用低度下降法來優化模型。當然機器學習內容實在是很多,建議能夠完整走一遍,也可以看斯坦福的CS229課程
1.7 計算機視覺的應用
計算機視覺之於未來人工智能,就好比眼睛之於人的重要性一樣。是未來很多領域自動化獲取數據的主要渠道之一,也是處理數據的重要工具之一。目前可以預想到的應用主要有如下:
- 無人駕駛
- 無人安防
- 人臉識別
- 文字識別
- 車輛車牌識別
- 以圖搜圖
- VR/AR
- 3D重構
- 醫學圖像分析
- 無人機
- more ……
二、推薦參考書和公開課
2.1 參考書籍
-
《Computer Vision : Models,Learning and Inference》
理論入門書籍
-
《Learning OpenCV》
計算機視覺必備工具
-
《Computer Vision : Algorithms and Applications》
計算機視覺算法和應用,屬於進階篇,這樣的書一般都有中文譯本。本人也是幾經周折,找到了一些資料,供大家下載學習。
2.2 公開課
-
李飛飛計算機視覺系列課程
這個課程作為入門非常合適,裏面也會分享一些幹貨
-
Stanford CS231N
B站資源鏈接
這兩門課我覺得經典的課程,如果認真學完的話,基本上是已經入門了,找一般的工作工作應該是沒有問題。
2.3 網站
-
Visionbib
這個網站是國外大佬從1994年開始專註於計算機視覺研究,上面收錄了很多與此相關文獻,大家可以看一些裏程碑文獻,讓自己能夠更好地理解視覺發展歷程。
-
vision.stanford
沒事上斯坦福大學計算機視覺研究團隊官網看看,大佬們有沒有發表一些研究成果文章,學習一番之後,將其翻譯成blog也不失為一個好的學習方法(裝逼方法)。
這兩個網站已經足夠了,不要太多,學好才是最關鍵的。
三、你還是需要學習一些深度學習知識
關於深度學習,評價最高的莫過於:《Deep Learning》Written by lan Goodfellow and YoshuaBengio

購買鏈接,這本AI聖經我就不多廢話了,攢錢買回去好好修煉吧!
四、開源框架必不可少
關於開源框架,仁者見仁智者見智,我也免得引起戰爭,所以就羅列給一下個人不成熟的小建議。
-
Caffe
深度學習卷積神經網絡開源框架。
-
Tensorflow
開源機器學習深度學習框架。
-
(Torch and Maxnet)
其他深度學習開源框架
-
ffmpeg
強大的視頻處理工具
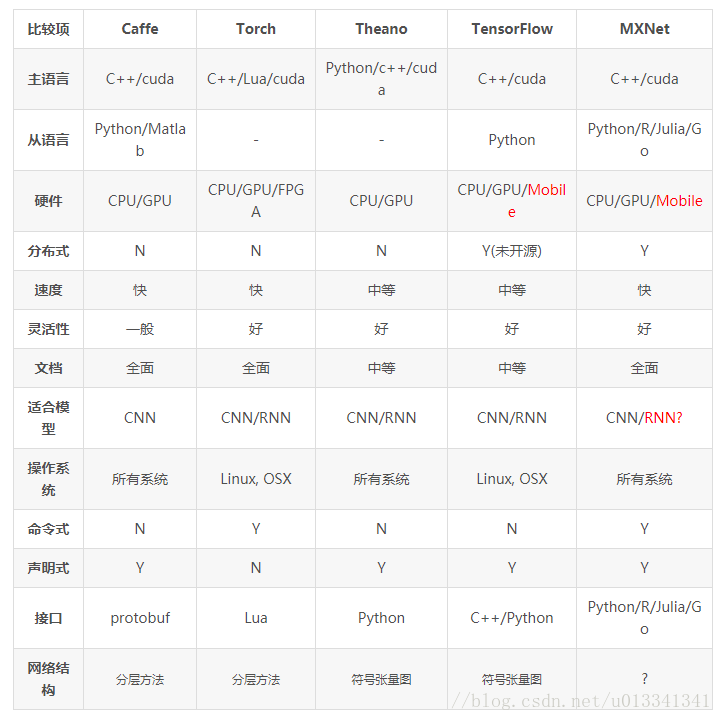
流行框架的對比圖:
參考鏈接
五、深入,則必須閱讀相關文獻
當我們需要學習各種經典模型的時候,到哪裏去找資料呢?一般大家都會直接wikipedia,可是我只想說,上面的也只是英文版漢譯過來的,最好還是找一手資料,不然你吸收的知識,就不知道是被多少人消化過多少遍後得來的。當然也是有好的,不過那些大牛都是直接看原版才能得出更加深刻的結論,所以看原版文獻是一件很重要的學習途徑,不然就永遠裝不了*(學習不到最純正的knowledge)。
5.1 裏程碑式的文獻
先熟悉所在方向的發展歷程,歷程中的裏程碑式的文獻必須要精讀。
例如,深度學習做目標檢測,RCNN、Fast RCNN、Fater RCNN、SPPNET、SSD和YOLO等模型;又例如,深度學習做目標跟蹤,DLT、SO-DLT等等;再例如,對抗網絡GAN、CGAN、DCGAN、LAPGAN等等。
- 1
- 2
- 3
- 4
5.2 文獻網站
[arxiv](https://arxiv.org/list/cs.CV/recent) :每天去更新一下別人最新的工作
- 1
- 2
5.3 計算視覺的頂會
- ICCV:國際計算機視覺大會
- CVPR:國際計算機視覺與模式識別大會
- ECCV:歐洲計算機視覺大會
5.4 計算機視覺的頂刊
- PAMI:IEEE 模式分析與機器智能雜誌
- IJCV:國際計算機視覺雜誌
六:總結
無論別人給出多好的資料,最終還是要靠自己踏實下來,對各種知識點細嚼慢咽。AI 不易,且行且珍惜
計算機視覺從入門到放肆