
[golang] 數據結構-堆排序
阿新 • • 發佈:2018-07-20
pen images 如果 sha 關於 也說 size 時間復雜度 當前位置 接上文 樹形選擇排序
上篇也說了,樹形選擇排序相較簡單選擇排序,雖然減少了時間復雜度,但是使用了較多空間去儲存每輪比較的結果,並且每次還要再和勝出節點比較。而堆排序就是為了優化這個問題而在1964年被兩位大佬發明。
上篇也說了,樹形選擇排序相較簡單選擇排序,雖然減少了時間復雜度,但是使用了較多空間去儲存每輪比較的結果,並且每次還要再和勝出節點比較。而堆排序就是為了優化這個問題而在1964年被兩位大佬發明。
原理
首先有幾個關於樹的定義:
如果一棵樹每個節點的值都大於(小於)或等於其字節點的話,那麽這棵樹就是大(小)根樹
如果一棵大(小)根樹正好又是完全二叉樹,則被稱為大根堆(小根堆)
堆排序就是利用大根堆(小根堆)的特性進行排序的。
從小到大排序一般用大根堆,從大到小一般用小根堆。
流程
- 先把待排序的數組8、4、12、7、35、9、22、41、2用完全二叉樹表示
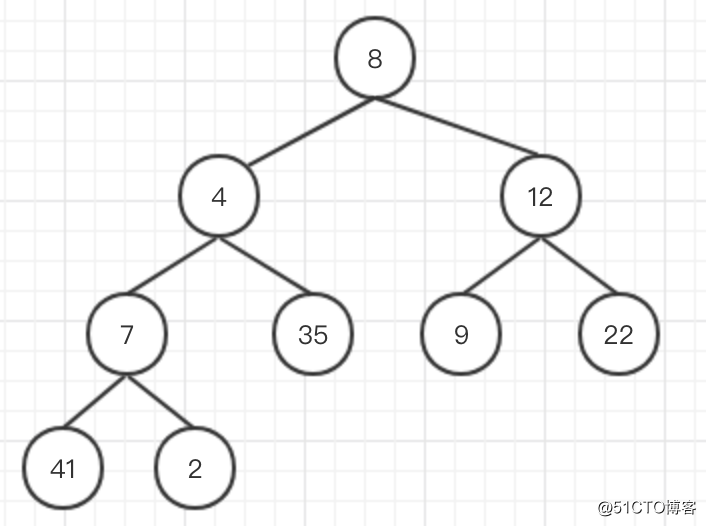
-
按大根堆的特性把這個完全二叉樹從最後一個非葉子節點開始比較,把較大值交換到當前位置。遇到上層節點順序影響下層節點不滿足大根堆特性時,再對下層節點進行排序。最終得到初始狀態的大根堆。
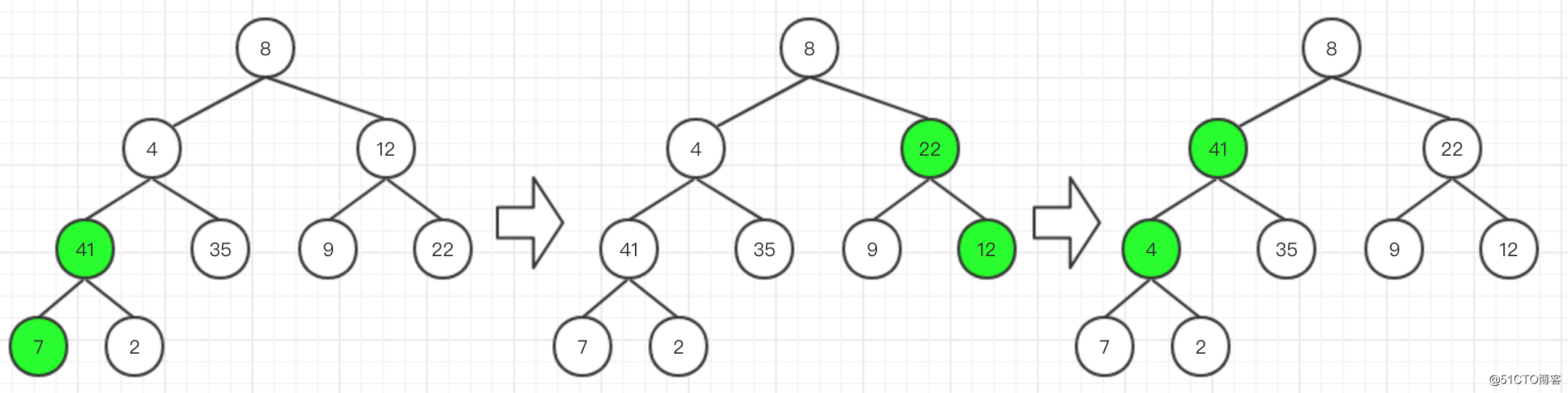
-
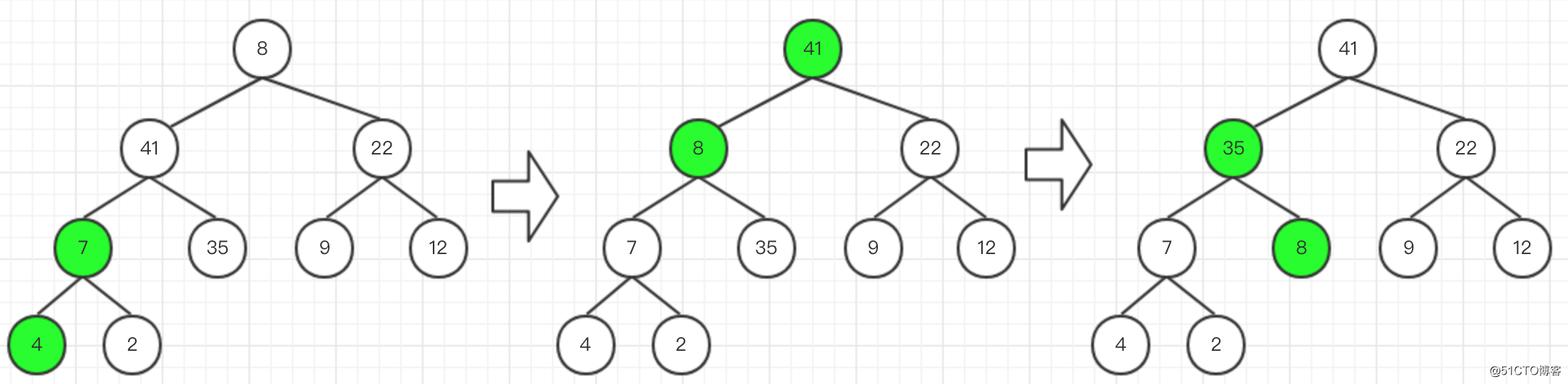
然後將根節點與最後一個葉子節點進行交換
-
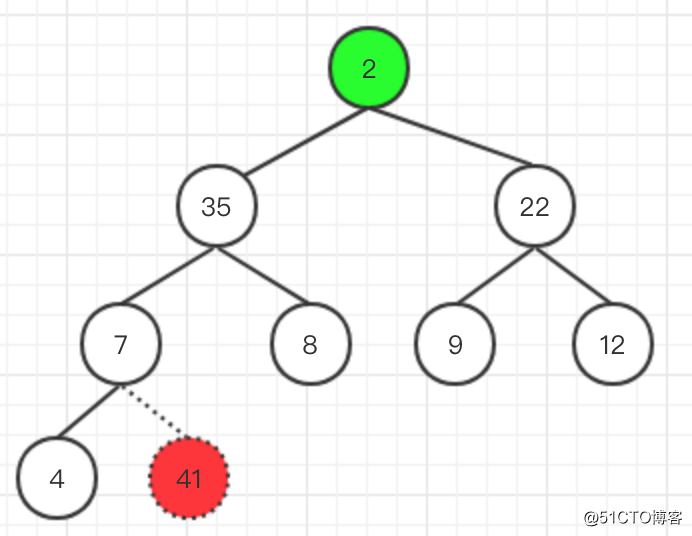
交換後,忽略最後一個葉子節點,再對這棵樹的節點進行比較與交換,再次得到符合大根堆要求的樹。然後繼續將根節點與最後的葉子節點進行交換
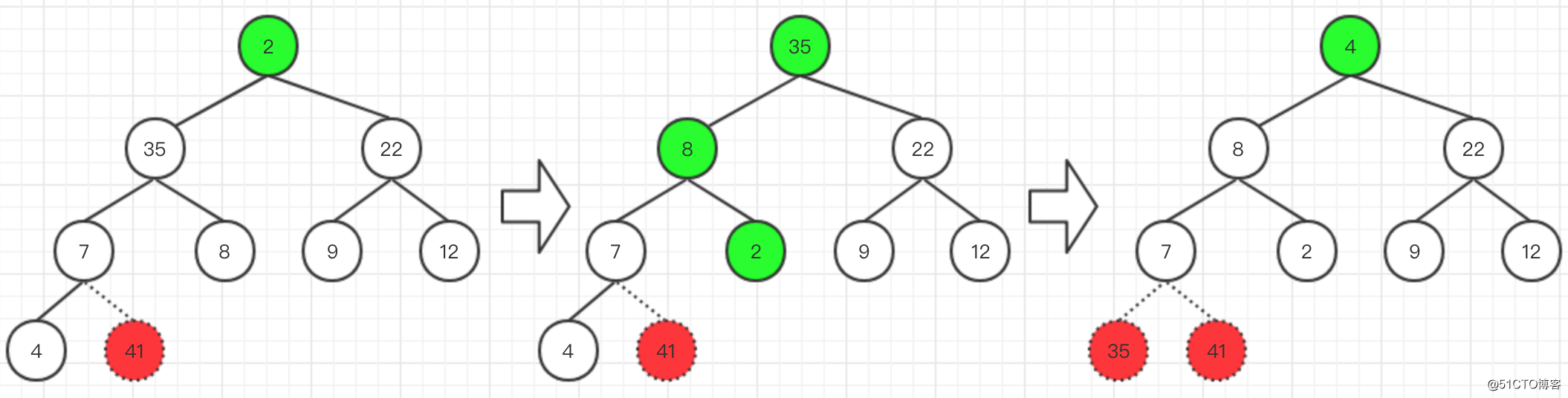
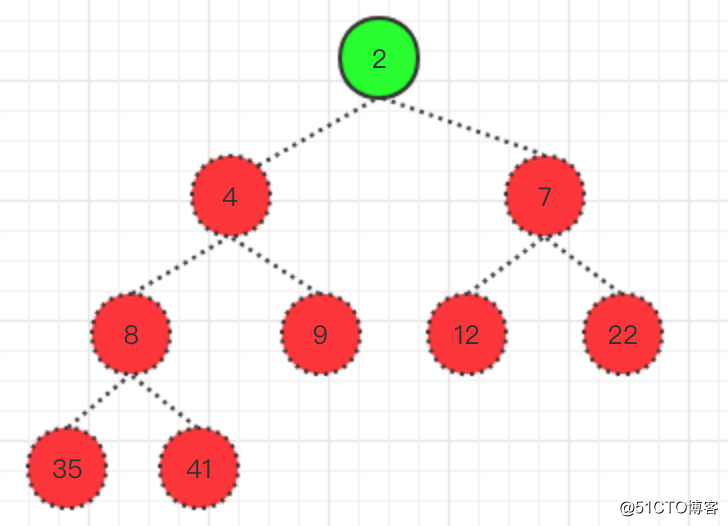
- 以此類推,最終可以得到一個有序的數組
復雜度
平均o(n*logn)
由於初次構建大根堆時有較多次的排序,所以不適合對少量元素進行排序。由於相同數值的節點在比較過程中不能保證順序,所以是種不穩定的排序方法。
代碼
package main import ( "fmt" "math/rand" ) func main() { var length = 20 var tree []int for i := 0; i < length; i++ { tree = append(tree, int(rand.Intn(1000))) } fmt.Println(tree) // 此時的切片o可以理解為初始狀態二叉樹的數(qie)組(pian)表示,然後需要將這個亂序的樹調整為大根堆的狀態 // 由於是從樹的右下角第一個非葉子節點開始從右向左從下往上進行比較,所以可以知道是從n/2-1這個位置的節點開始算 for i := length/2 - 1; i >= 0; i-- { nodeSort(tree, i, length-1) } // 次數tree已經是個大根堆了。只需每次交換根節點和最後一個節點,並減少一個比較範圍。再進行一輪比較 for i := length - 1; i > 0; i-- { // 如果只剩根節點和左孩子節點,就可以提前結束了 if i == 1 && tree[0] <= tree[i] { break } // 交換根節點和比較範圍內最後一個節點的數值 tree[0], tree[i] = tree[i], tree[0] // 這裏遞歸的把較大值一層層提上來 nodeSort(tree, 0, i -1) fmt.Println(tree) } } func nodeSort(tree []int, startNode, latestNode int) { var largerChild int leftChild := startNode*2 + 1 rightChild := leftChild + 1 // 子節點超過比較範圍就跳出遞歸 if leftChild >= latestNode { return } // 左右孩子節點中找到較大的,右孩子不能超出比較的範圍 if rightChild <= latestNode && tree[rightChild] > tree[leftChild] { largerChild = rightChild } else { largerChild = leftChild } // 此時startNode節點數值已經最大了,就不用再比下去了 if tree[largerChild] <= tree[startNode] { return } // 到這裏發現孩子節點數值比父節點大,所以交換位置,並繼續比較子孫節點,直到把大魚撈上來 tree[startNode], tree[largerChild] = tree[largerChild], tree[startNode] nodeSort(tree, largerChild, latestNode) }
註:代碼裏用遞歸並不是最優解
運行結果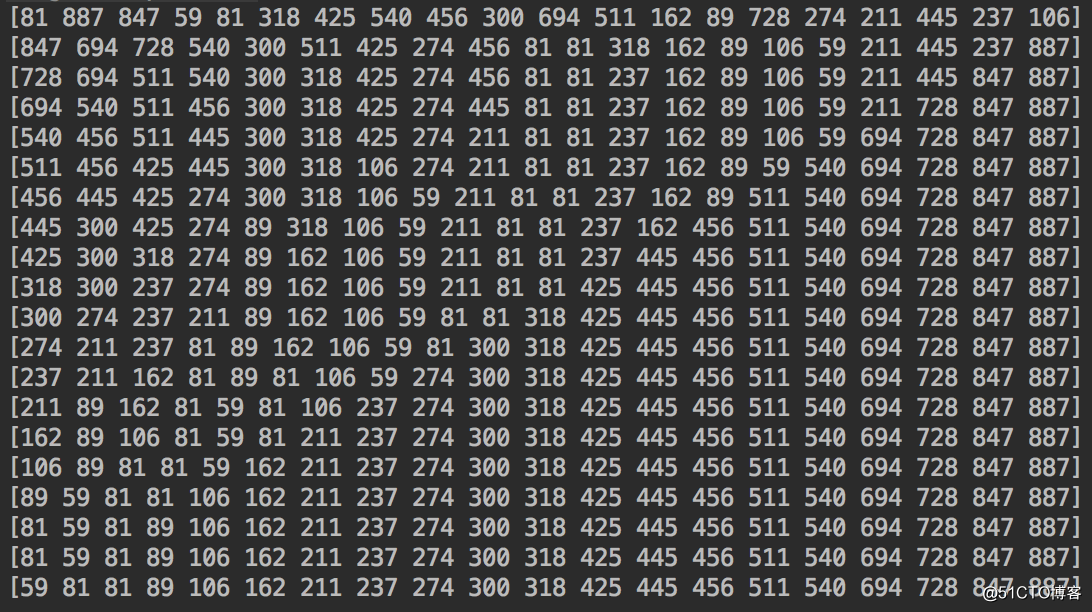
[golang] 數據結構-堆排序