
spark==RDD
阿新 • • 發佈:2018-08-21
park 多少 基本 ges shc set hdf 結束 ase 在spark的簡介中我們已經說過了,為了讓spark的處理速度加快,其中有一個解決辦法就是引入了一個分布式的彈性數據集--RDD
那什麽是RDD:RDD(Resilient Distributed Dataset)彈性數據集,是spark中的最基本的數據抽象,雖然說RDD是一個數據集,但是,它不存儲數據,他表示的是一個不可變的,可分區的元素並行計算的集合,允許用戶在執行多個查詢時將工作緩存到內存中,當後面的計算需要使用到這部分數據的時候可以直接調用,而且內存的運行速度較之磁盤的速度非常之快,極大的提升了spark的運行效率
RDD的屬性:
1、A list of partiton:RDD是由一個個的partition組成的,每一個partition會被一個計算任務處理,並由最後一個RDD中的partiton的個數決定整個程序有多少並行的任務,,在創建任務的時候可以指定partition的個數,默認是程序分配的core的個數
3、A list of dependencies on other RDDs :RDD沒經過一個計算算子都會重新生成一個RDD,但RDD以來其他的RDD,這就構成了RDD之間的依賴關系,形成一個類似管道的通路,當有數據丟失的時候,可以根據依賴關系,直接去其他的RDD上重新計算生成,不用從頭讀取文件在計算,節省了時間和資源
5、Optionally, a list of preferred locations to conpute each spllit on:為了提升計算的性能,所以遵循計算向數據移動的理念,,RDD會提供一系列的最佳的計算位置,而且見底了網絡和磁盤IO,提升了效率
在書寫sparkRDD的運行程序的步驟,
1、將HDFS數據加載到RDD textfile
3、當遇到action類算子之後啟動,觸發執行
RDD的依賴關系以及區別
RDD分為寬依賴和窄依賴兩種依賴關系,通過這兩種依賴關系切割job,劃分stage,將RDD分成不同的塊進行計算
寬依賴:父與子的對應關系是一對多的關系,在運行過程中會發生shuffle,每一個RDD的執行要等上一個RDD的所有task都結束之後再運行,
窄依賴:父與子的對應關系是一對一的關系,在運行過程中不會發生shuffle,所有的RDD同時運行,沒有先後關系
在計算RDD的時候的兩種個算子
Transformation算子(懶執行,需要Action類算子進行觸發):
1、不發生shuffle(map、flatmap)
2、發生shuffle(groupByKey),在分組過程中會發生磁盤或者網絡之間的IO,這個過程我們稱之為shuffle,關於shuffle會單獨講解
Action算子:觸發程序執行的算子,會將程序推送到Executor上執行
控制類算子:cache。Persist,將RDD進行持久化,cache默認的持久化到內存中進行計算,而persist可以設置不同的持久化級別
1、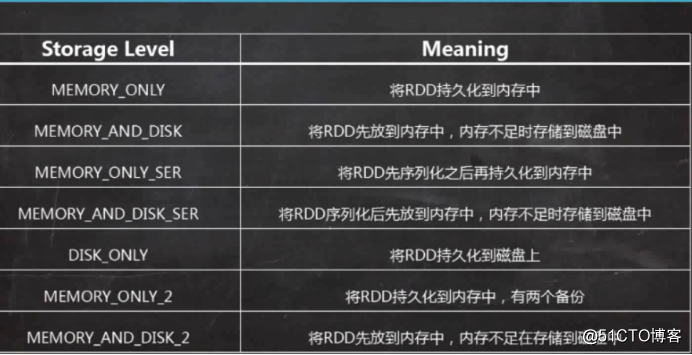
那什麽是RDD:RDD(Resilient Distributed Dataset)彈性數據集,是spark中的最基本的數據抽象,雖然說RDD是一個數據集,但是,它不存儲數據,他表示的是一個不可變的,可分區的元素並行計算的集合,允許用戶在執行多個查詢時將工作緩存到內存中,當後面的計算需要使用到這部分數據的時候可以直接調用,而且內存的運行速度較之磁盤的速度非常之快,極大的提升了spark的運行效率
RDD的屬性:
1、A list of partiton:RDD是由一個個的partition組成的,每一個partition會被一個計算任務處理,並由最後一個RDD中的partiton的個數決定整個程序有多少並行的任務,,在創建任務的時候可以指定partition的個數,默認是程序分配的core的個數
3、A list of dependencies on other RDDs :RDD沒經過一個計算算子都會重新生成一個RDD,但RDD以來其他的RDD,這就構成了RDD之間的依賴關系,形成一個類似管道的通路,當有數據丟失的時候,可以根據依賴關系,直接去其他的RDD上重新計算生成,不用從頭讀取文件在計算,節省了時間和資源
5、Optionally, a list of preferred locations to conpute each spllit on:為了提升計算的性能,所以遵循計算向數據移動的理念,,RDD會提供一系列的最佳的計算位置,而且見底了網絡和磁盤IO,提升了效率
在書寫sparkRDD的運行程序的步驟,
1、將HDFS數據加載到RDD textfile
3、當遇到action類算子之後啟動,觸發執行
RDD的依賴關系以及區別
RDD分為寬依賴和窄依賴兩種依賴關系,通過這兩種依賴關系切割job,劃分stage,將RDD分成不同的塊進行計算
寬依賴:父與子的對應關系是一對多的關系,在運行過程中會發生shuffle,每一個RDD的執行要等上一個RDD的所有task都結束之後再運行,
窄依賴:父與子的對應關系是一對一的關系,在運行過程中不會發生shuffle,所有的RDD同時運行,沒有先後關系
在計算RDD的時候的兩種個算子
Transformation算子(懶執行,需要Action類算子進行觸發):
1、不發生shuffle(map、flatmap)
2、發生shuffle(groupByKey),在分組過程中會發生磁盤或者網絡之間的IO,這個過程我們稱之為shuffle,關於shuffle會單獨講解
Action算子:觸發程序執行的算子,會將程序推送到Executor上執行
控制類算子:cache。Persist,將RDD進行持久化,cache默認的持久化到內存中進行計算,而persist可以設置不同的持久化級別
1、
2、將數據持久化到內存中,提高了計算的效率
關於RDD的相關知識基本總結完了,但是,為了一個更加直觀的方式展示,下面會介紹一個spark中的hello world案例----wordcount
特別的,RDD4中的每一個partition的數據是根據分區器的策略來決定的,默認是hashPartiton(就是根據key的hashcode與RDD4的分區數來取莫,決定這條記錄要去哪一個分區,相同的key一定在一個分區中)
spark==RDD