
Mask RCNN 原理
轉自:https://blog.csdn.net/ghw15221836342/article/details/80084861
https://blog.csdn.net/ghw15221836342/article/details/80084984
Mask RCNN 原理:
簡單說一下Mask R-CNN 是一個兩階段的框架,第一個階段掃描圖像並生成提議(proposals,即有可能包含一個目標的區域),第二階段分類提議並生成邊界框和掩碼。Mask R-CNN 擴展自 Faster R-CNN,由同一作者在去年提出。Faster R-CNN 是一個流行的目標檢測框架,Mask R-CNN 將其擴展為實例分割框架。

Mask R-CNN 的主要構建模塊:
1. 主幹架構
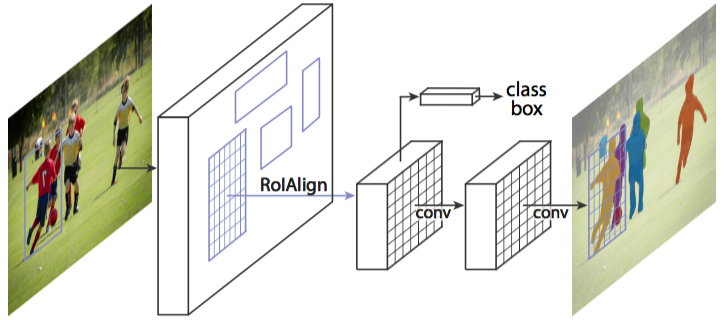
主幹網絡(上圖左邊第一個箭頭)的簡化圖示
這是一個標準的卷積神經網絡(通常來說是 ResNet50 和 ResNet101),作為特征提取器。底層檢測的是低級特征(邊緣和角等),較高層檢測的是更高級的特征(汽車、人、天空等)。
經過主幹網絡的前向傳播,圖像從 1024x1024x3(RGB)的張量被轉換成形狀為 32x32x2048 的特征圖。該特征圖將作為下一個階段的輸入。
特征金字塔網絡(FPN)
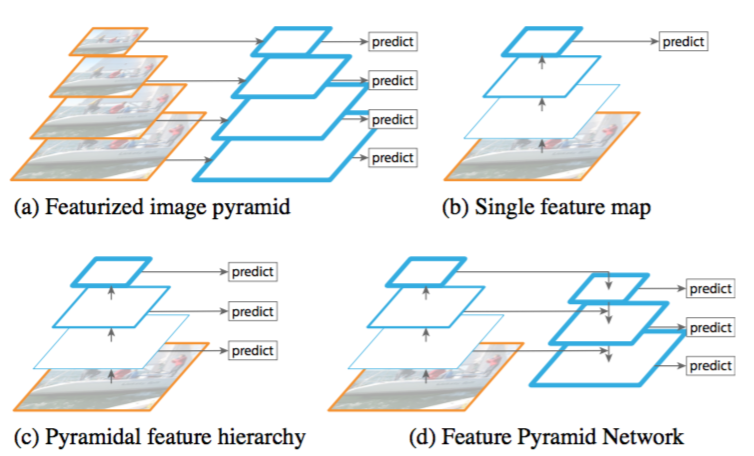
Feaature Pyramid Networks for Object Detection
上述的主幹網絡還可以進一步提升。由 Mask R-CNN 的同一作者引入的特征金字塔網絡(FPN)是對該主幹網絡的擴展,可以在多個尺度上更好地表征目標。
FPN 通過添加第二個金字塔提升了標準特征提取金字塔的性能,第二個金字塔可以從第一個金字塔選擇高級特征並傳遞到底層上。通過這個過程,它允許每一級的特征都可以和高級、低級特征互相結合。
在我們的 Mask R-CNN 實現中使用的是 ResNet101+FPN 主幹網絡。
2. 區域建議網絡(RPN)

RPN 是一個輕量的神經網絡,它用滑動窗口來掃描圖像,並尋找存在目標的區域。
RPN 掃描的區域被稱為 anchor,這是在圖像區域上分布的矩形,如上圖所示。這只是一個簡化圖。實際上,在不同的尺寸和長寬比下,圖像上會有將近 20 萬個 anchor,並且它們互相重疊以盡可能地覆蓋圖像。
RPN 掃描這些 anchor 的速度有多快呢?非常快。滑動窗口是由 RPN 的卷積過程實現的,可以使用 GPU 並行地掃描所有區域。此外,RPN 並不會直接掃描圖像,而是掃描主幹特征圖。這使得 RPN 可以有效地復用提取的特征,並避免重復計算。通過這些優化手段,RPN 可以在 10ms 內完成掃描(根據引入 RPN 的 Faster R-CNN 論文中所述)。在 Mask R-CNN 中,我們通常使用的是更高分辨率的圖像以及更多的 anchor,因此掃描過程可能會更久。
RPN 為每個 anchor 生成兩個輸出:
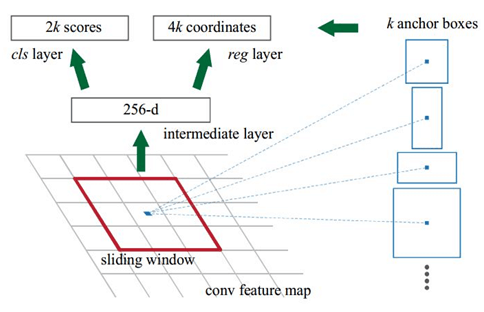
-
anchor 類別:前景或背景(FG/BG)。前景類別意味著可能存在一個目標在 anchor box 中。
-
邊框精調:前景 anchor(或稱正 anchor)可能並沒有完美地位於目標的中心。因此,RPN 評估了 delta 輸出(x、y、寬、高的變化百分數)以精調 anchor box 來更好地擬合目標。
使用 RPN 的預測,我們可以選出最好地包含了目標的 anchor,並對其位置和尺寸進行精調。如果有多個 anchor 互相重疊,我們將保留擁有最高前景分數的 anchor,並舍棄余下的(非極大值抑制)。然後我們就得到了最終的區域建議,並將其傳遞到下一個階段。
3. ROI 分類器和邊界框回歸器
這個階段是在由 RPN 提出的 ROI 上運行的。正如 RPN 一樣,它為每個 ROI 生成了兩個輸出:
-
類別:ROI 中的目標的類別。和 RPN 不同(兩個類別,前景或背景),這個網絡更深並且可以將區域分類為具體的類別(人、車、椅子等)。它還可以生成一個背景類別,然後就可以棄用 ROI 了。
-
邊框精調:和 RPN 的原理類似,它的目標是進一步精調邊框的位置和尺寸以將目標封裝。
ROI 池化
在我們繼續之前,需要先解決一些問題。分類器並不能很好地處理多種輸入尺寸。它們通常只能處理固定的輸入尺寸。但是,由於 RPN 中的邊框精調步驟,ROI 框可以有不同的尺寸。因此,我們需要用 ROI 池化來解決這個問題。
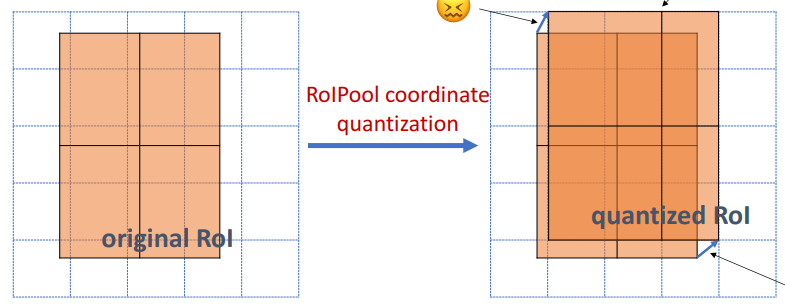
ROI 池化是指裁剪出特征圖的一部分,然後將其重新調整為固定的尺寸。這個過程實際上和裁剪圖片並將其縮放是相似的(在實現細節上有所不同)。
Mask R-CNN 的作者提出了一種方法 ROIAlign,在特征圖的不同點采樣,並應用雙線性插值,主要是減少量化操作帶來的特征損失https://www.cnblogs.com/MY0213/p/9567014.html。在我們的實現中,為簡單起見,我們使用 TensorFlow 的 crop_and_resize 函數來實現這個過程。
4. 分割掩碼
到第 3 節為止,我們得到的正是一個用於目標檢測的 Faster R-CNN。而分割掩碼網絡正是 Mask R-CNN 的論文引入的附加網絡。
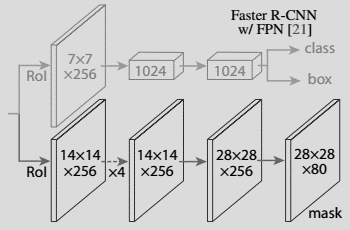
掩碼分支是一個卷積網絡,取 ROI 分類器選擇的正區域為輸入,並生成它們的掩碼。其生成的掩碼是低分辨率的:28x28 像素。但它們是由浮點數表示的軟掩碼,相對於二進制掩碼有更多的細節。掩碼的小尺寸屬性有助於保持掩碼分支網絡的輕量性。在訓練過程中,我們將真實的掩碼縮小為 28x28 來計算損失函數,在推斷過程中,我們將預測的掩碼放大為 ROI 邊框的尺寸以給出最終的掩碼結果,每個目標有一個掩碼。
Mask RCNN 原理