
Apache Flume
阿新 • • 發佈:2018-09-13
col image img flume 數據采集 3.2 聚合 sha 版本 1. 概述
Flume是Cloudera提供的一個高可用的,高可靠的,分布式的海量日誌采集、聚合和傳輸的軟件。
Flume的核心是把數據從數據源(source)收集過來,再將收集到的數據送到指定的目的地(sink)。為了保證輸送的過程一定成功,在送到目的地(sink)之前,會先緩存數據(channel),待數據真正到達目的地(sink)後,flume在刪除自己緩存的數據。
Flume支持定制各類數據發送方,用於收集各類型數據;同時,Flume支持定制各種數據接受方,用於最終存儲數據。一般的采集需求,通過對flume的簡單配置即可實現。針對特殊場景也具備良好的自定義擴展能力。因此,flume可以適用於大部分的日常數據采集場景。
最終存儲系統傳遞數據;
Channel:agent內部的數據傳輸通道,用於從source將數據傳遞到sink;
在整個數據的傳輸的過程中,流動的是event,它是Flume內部數據傳輸的最基本單元。event將傳輸的數據進行封裝。如果是文本文件,通常是一行記錄,event也是事務的基本單位。event從source,流向channel,再到sink,本身為一個字節數組,並可攜帶headers(頭信息)信息。event代表著一個數據的最小完整單元,從外部數據源來,向外部的目的地去。
一個完整的event包括:event headers、event body、event信息,其中event信息就是flume收集到的日記記錄。
Flume是Cloudera提供的一個高可用的,高可靠的,分布式的海量日誌采集、聚合和傳輸的軟件。
Flume的核心是把數據從數據源(source)收集過來,再將收集到的數據送到指定的目的地(sink)。為了保證輸送的過程一定成功,在送到目的地(sink)之前,會先緩存數據(channel),待數據真正到達目的地(sink)後,flume在刪除自己緩存的數據。
Flume支持定制各類數據發送方,用於收集各類型數據;同時,Flume支持定制各種數據接受方,用於最終存儲數據。一般的采集需求,通過對flume的簡單配置即可實現。針對特殊場景也具備良好的自定義擴展能力。因此,flume可以適用於大部分的日常數據采集場景。
2. 運行機制
Flume系統中核心的角色是agent,agent本身是一個Java進程,一般運行在日誌收集節點。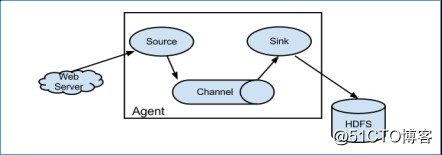
每一個agent相當於一個數據傳遞員,內部有三個組件:
Source:采集源,用於跟數據源對接,以獲取數據;
最終存儲系統傳遞數據;
Channel:agent內部的數據傳輸通道,用於從source將數據傳遞到sink;
在整個數據的傳輸的過程中,流動的是event,它是Flume內部數據傳輸的最基本單元。event將傳輸的數據進行封裝。如果是文本文件,通常是一行記錄,event也是事務的基本單位。event從source,流向channel,再到sink,本身為一個字節數組,並可攜帶headers(頭信息)信息。event代表著一個數據的最小完整單元,從外部數據源來,向外部的目的地去。
一個完整的event包括:event headers、event body、event信息,其中event信息就是flume收集到的日記記錄。
3. Flume采集系統結構圖3.1. 簡單結構
單個agent采集數據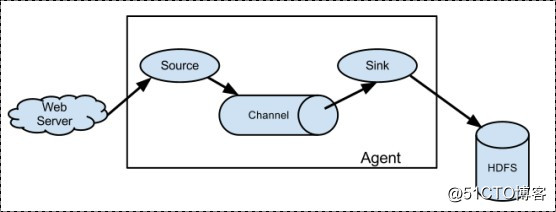
3.2. 復雜結構
多級agent之間串聯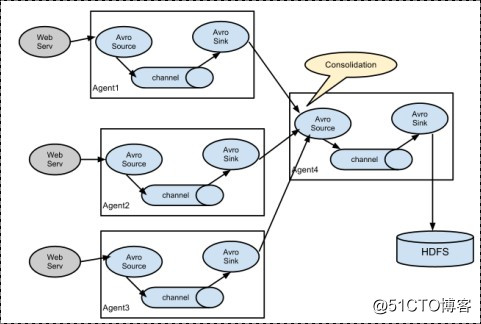
Apache Flume