Apache Flume介紹
本文是我發表在大華Share Or Out俱樂部中的文章,希望讀者閱讀後能初步瞭解flume的基本概念和用途,限於本人能力,有錯誤之處還請指出,謝謝!
介紹:
Flume是Apache下面的一個分散式元件,它提供高效,可靠的收集,整合,傳輸日誌資料的服務。Flume可以理解成一個管道,它連線資料的生產者和消費者,它從資料的生產者(Source)獲取資料,儲存在自己的快取(Channel)中,然後通過Sink傳送到消費者。它不對資料做儲存和複雜的處理(可以做簡單過濾和改寫)。
架構:
Flume在版本0.9x以前的版本統稱為Flume-og,1.X之後的版本統稱為Flume-ng
由於Flume-og版本中Flume的角色過多,比如agent, collector,master等,導致使用者使用起來存在困難,因此新的Flume-ng只設計了一個角色Agent,如下圖:
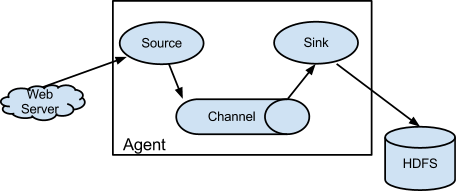
Flume的Agent有如下特點:
- 一個Agent是一個單獨的程序。
- 一個Agent由一個或多個管道組成。
- 一個管道由三個內部模組組成Source,Channel,Sink。
- 使用者可以隨意指定Agent
中Source,Channel,Sink的型別,只要該型別符合使用者自己的使用場景,Flume提供了相當大的靈活度,使用者可以隨意搭配。
Source
Source是Flume裡面的資料生成模組,它一般有三種方式:
1. Source作為服務的,開啟埠,接收其他服務發來的資料,如Avro,NetCat。
2. Source作為客戶端,從其他服務獲取資料,如Kafka。
3. Source自動生成資料,一般做除錯/測試使用,如Seq,StressSource。
Flume內建提供了很多開箱即用的Source供使用者選擇,包括Avro,Kafka,NetCat,
Exec,SyslogTcp,StressSource等。另外,Flume也支援使用者自定義Source。
Channel
Channel是Flume裡面的資料快取模組,它只提供資料的臨時快取。
Source將收到的資料放到Channel中,待Sink從Channel中取走該資料後,
Channel將清除該資料。
Flume內建了一些Channel供使用者選擇使用,比如Memory, File, Kafka, JDBC。
大體上分為記憶體,檔案,外部儲存系統,其中記憶體方式是最快速的。當然,使用者也可以定製化自己的Channel。
Sink
Sink是Flume裡面的資料處理模組,它負責從Channel中消費資料,可以存到HDFS,HBASE等資料庫中,也有可以發給下一級Agent。
Flume內建了一些Channel供使用者選擇使用,比如Kafka,HBase, AsyncHBase,Logger,null等,當然,使用者也可以定製化自己的Sink。
使用場景:
Flume靈活的架構設計,讓使用者可以根據自己的需要,任意的搭建。
總的來說有如下一些使用方式。
級聯
在某些場景下,我們需要將兩個agent級聯起來。如果一個agent的Source為選為Avro型別,而另一個agent的Sink也選為Avro型別,那麼我們可以將兩個agent級聯起來,只需要將下一級agent的IP資訊配置到上一級的Sink配置中即可。
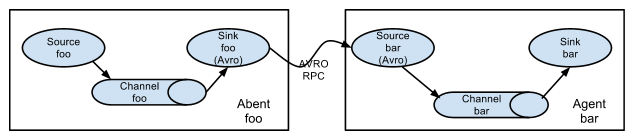
當然,是由於內建的Avro的Sink和內建的Avro型別的Source能對接起來,才能完成級聯,如果使用者有其他自定義的Source和Sink也能完成對接,那麼也可以會用自定義的型別。
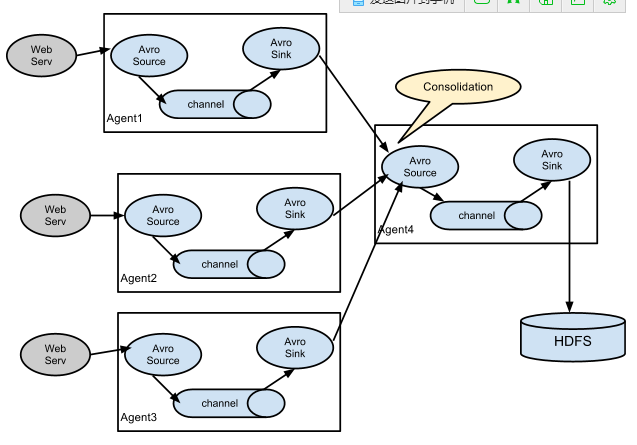
聚合
在一些場景下,我們需要收集多個系統的日誌聚合到一個地方,因此需要將agent合併到一起。我們只需要將多個agent的sink指向一個agent即可。
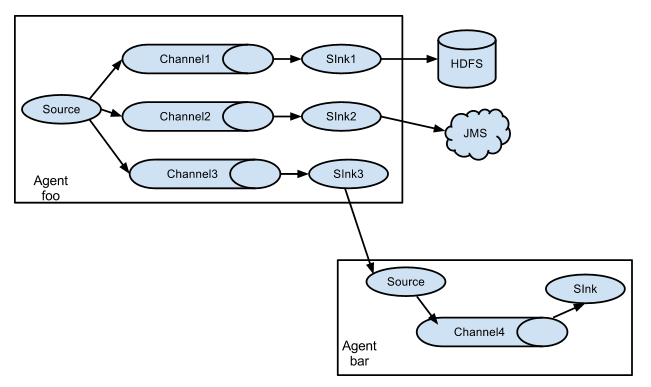
分發
在某些場景下,我們需要將一個系統的日誌收集後,f存到多個目的地,Flume支援這種應用。事實上,從一個source出來的資料,我們可以選擇資料是簡單的複製分發到所有的channel,,還是有針對資料做選擇性的分發,比如圖片傳送到Channel A, 文字傳送到Channel B等類似的功能。如下圖: