
深度學習高速路上,PaddlePaddle正在彎道超車
深度學習是機器學習中一種基於對數據進行表證學習的方法,近些年不斷發展並廣受歡迎。研究熱潮的持續高漲,帶來各種開源深度學習框架層出不窮,其中包括TensorFlow、Caffe、Keras、CNTK、Torch7、MXNet、Leaf、PaddlePaddle、Theano、DeepLearning4、Lasagne、Neon等,在此背景下,PaddlePaddle如何在這條深度學習的高速路上彎道超車,看PaddlePaddle架構師潘欣如何解答。

以下為潘欣老師演講實錄
借助傳統編程語言理念的全功能深度學習框架
PaddlePaddle是國內唯一的開源深度學習平臺,由百度自主研發並具備完全的自主核心技術和知識產權,支持從建模、網絡、強化學習、語音識別到最後部署的全部環節,具有易學、易用、安全、高效等特點,是全功能的深度學習框架。

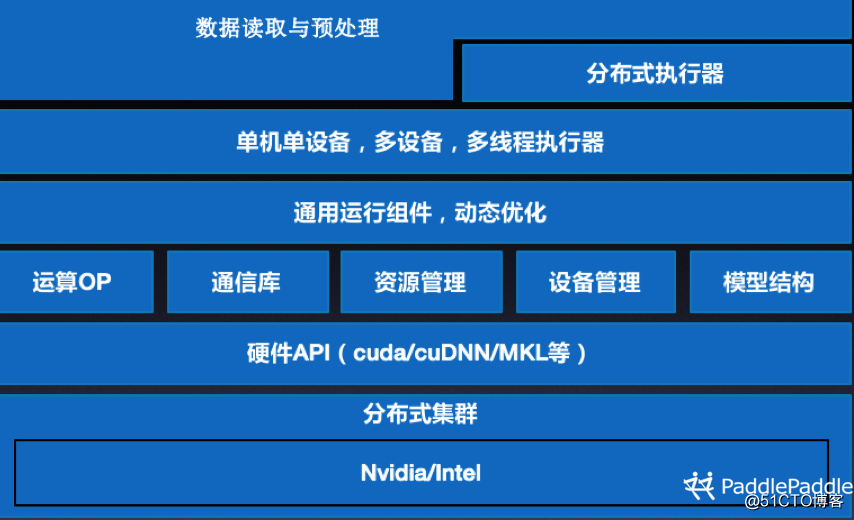
圖一 PaddlePaddle核心框架結構
PaddlePaddle的核心架構如圖所示,它的整體運行流程是通過API接口組輸入/輸出網絡,並在底層做統一轉化,然後通過Runtime進行訓練,最後轉換成線上部署的模型。線上部署分為服務端和移動端,為應對不同體系平臺、能耗的要求,我們部署不同的設備。
其中左側第一層是API接口,它采用Python語言編寫,大致分為兩大類,一類是組網類API,包括控制邏輯、構成邏輯、計算邏輯、IO的模塊、讀取數據的模塊等;另一類是執行類底層API,把用戶組好的模型進行分析,並將計算方法進行合並優化,以此提高訓練速度。
除此之外,對於API的組網,PaddlePaddle還有一些新特性。眾所周知,目前很多的框架是在用戶層暴露出來一個圖的接口,以此進行組網。但我們認為,大多數的程序員更熟悉的是傳統的如變量、block的流式程序的概念,而不是通過一個圖去連接算子、編寫模型。所以在PaddlePaddle API接口的設計中,我們使用了這些傳統編程語言的理念,使得最終編寫更類似於傳統編程語言。
組網類API
組網類API包含通用、控制、計算、優化、IO等類型的API。
? Variables:PaddlePaddle中的變量,可以是Tensor、 Parameter,或RPCClient。概念類似高級語言中的變量,有不同類型。
? Layers:PaddlePaddle中用戶配置模型的基礎模塊,Layer表示一個或者一組緊密關聯的計算,Layers可以通過輸入輸出連接起來。
? Block:Block表示一組連續的計算邏輯,通常是一個或多個順序Layer組成。通常主模型是一個Block0。另外在Control Flow中,比如While、Iflese,也會單獨形成一個子Block。
? Program:包含了1個或者多個Block,表示一個完整的模型執行單元。執行器需要完整的執行Program,並保證讀寫關系符合用戶的預期。
執行類API


示例
訓練Runtime
多卡並行-SSA Graph
? 將模型Program轉換成一個可並發執行的Intermediate Representation(IR);利用Static Single Assignment為Variable加Version,得到一個正確的依賴關系;Build Pass中插入通信節點和額外的依賴關系。
? 基於圖依賴的執行:Input ready的所有Operator可以並發執行;Operators在多個GPU上數據並行執行;多卡Gradient聚合,確保數據並行中參數一致。

多卡並行-Profile
多機分布式
多機分布式支持Ring、Pserver兩種模式。
? Ring:自動插入多機Communicator,多機同步訓練,支持高性能RDMA通信。
? Pserver:拆分成Trainer Program和PserverProgram。支持同步和異步的分布式訓練。Trainer端多線程異步發送Gradient;Pserver端多線程異步Apply Optimization。
用戶Focus Modeling, 框架自動多機化部署:
? 發現Optimizer Operators、Parameters、Gradients。
? Split和Assign到Parameter Server上。
? 在Trainer和Parameter Server上插入發送和接收的通信節點。
? 生成在Trainer執行的Program。
? 生成在Parameter Server執行的Program。
多機分布式的通信和集群
? 支持MPI、RPC等通信方式。
? RPC將來會換成Brpc,並提供原生的RPC+RDMA支持,極大提高通信效率。
? 支持Kubernetes集群部署。
多機分布式下的容錯
Trainer或者PserverFailure後可以重啟恢復訓練。即將支持Pserver端的分布式CheckPoint和恢復,支持大規模Embedding。
大規模稀疏數據分布式模型訓練
在互聯網場景中,億級的用戶每天產生著百億級的用戶數據,百度的搜索和推薦系統是大規模稀疏數據分布式模型訓練的主要應用場景。
如何利用這些數據訓練出更好的模型來給用戶提供服務,對機器學習框架提出了很高的要求。主要包括:
? 樣本數量大,單周20T+。
? 特征維度多達千億甚至萬億。
? T級別,參數大。
? 小時級更新,時效要求高。
註:文中所提架構基於PaddlePaddle 0.14版本,未來,會發出更為穩定的新版本,歡迎大家關註
提問環節
提問:在分布式訓練的時候,有同步和異步兩種,什麽時候適合用同步,什麽時候適合用異步?
潘欣:目前沒有機械化的方法確定這個問題,但是有一些經驗可以跟大家分享。如在圖像這個領域用同步更穩定,還有最近的翻譯模型,也是通過同步的方法訓練。當然,並不是說同步一定比異步好。根據過去在公司的經驗,中國的主流其實是異步,異步的好處是訓練更加可擴展,對於很多傳統NLP任務,異步比同步要好。所以要驗證這個問題需要在實驗中比較。
實錄結束
潘欣,百度深度學習框架PaddlePaddle的架構設計以及核心模塊開發負責人,百度深度學習技術平臺部TC主席。在計算機視覺CVPR和雲計算SoCC等國際會議發表多篇論文。
深度學習高速路上,PaddlePaddle正在彎道超車