
基於PaddlePaddle的新能源充電樁智能運維
隨著大數據、人工智能、雲計算技術的日漸成熟和飛速發展,傳統的運維技術和解決方案已經不能滿足需求,智能運維已成為運維的熱點領域。同時,為了滿足大流量、用戶高質量體驗和用戶分布地域廣的互聯網應用場景,大型分布式系統的部署方式也成為了高效運維的必然之選。如何提升運維的能力和效率,是保障業務高可用所面臨的最大挑戰。本篇文章以百度基於PaddlePaddle的新能源充電樁為切入點,深入介紹智能運維在電力行業的實際應用。
以下為演講實錄。
電力行業運維過程中的痛點與機遇
眾所周知,典型電力行業包括發電、輸電、配電、用電等多個階段,而電力作為關系國計民生的重要資源,在各個階段無論針對電網或是終端設備的運行維護都是保障電網安全穩定運行的重要手段。此外,目前中國已經建成全球範圍內信息化程度最高的電網,而電網的工程師們仍在持續學習和引入新技術,大數據和深度學習是他們重點關註的方向。我們發現,針對電力運維,有三個典型的場景比較適合大數據與深度學習技術,包括:
2.規劃電網調度:通過對氣象數據、用戶行為數據等分析建模,實現用電管理,優化電網調度提升效率;
3.用電異常識別:通過對終端設備,如智能電表的數據分析,實現用電異常識別,降低用電損失提升效率。
基於電力行業四大特點,充電樁智能運維需要新的技術方案

圖一:電力行業四大特點
電力行業有四大特點:
1.市場規模大:發改委在2015年頒布的《充電樁建設指南》指出,計劃到2020年全國建成超過480萬個充電樁,圖中為根據指南及目前市場情況的測算,到2020年整個市場規模將達900億。而2017年全國保有量為21.3萬個,僅北京地區已超3萬個,一方面鮮有保有量已經不小,此外從今年開始將是充電樁建設的高速爆發期;
3.運維成本高:現場故障多,環境復雜,造成現場運維人力成本高;
4.行業痛點強:目前針對充電樁運維已經有技術方案,但傳統廠商一般基於傳統數據庫搭建方案,一旦出現增量上網,很難應對大數據和擴容的挑戰。此外由於缺乏數據挖掘的工具和知識,數據利用率不高。基於以上四個特點,充電樁智能運維需要新的技術方案。

圖2:充電樁智能運維新方案
在此背景下,我們和博電電氣聯合提出了充電樁智能運維新方案。博電電氣是行業領先的電力測試設備供應商,主要服務國家電網、南方電網和海外電網運營商。在這套新的方案中,我們通過一攬子技術方案包括底層的物聯網設備接入、邊緣計算,到中層的雲計算平臺,上層的大數據平臺,解決設備管理復雜、擴容難等問題。同時,基於百度AI能力,我們搭建了多種運維模型,包括設備監測,到故障診斷,到預測性維保。以充電樁故障診斷為例,基於傳統數據分析工具如matlab、labview和本地計算資源,已經達到95%的故障識別率。但我們通過PaddlePaddle的深度學習和分布式計算,比較容易的就將準確度再提升了4個點,並給客戶帶來了經濟價值。
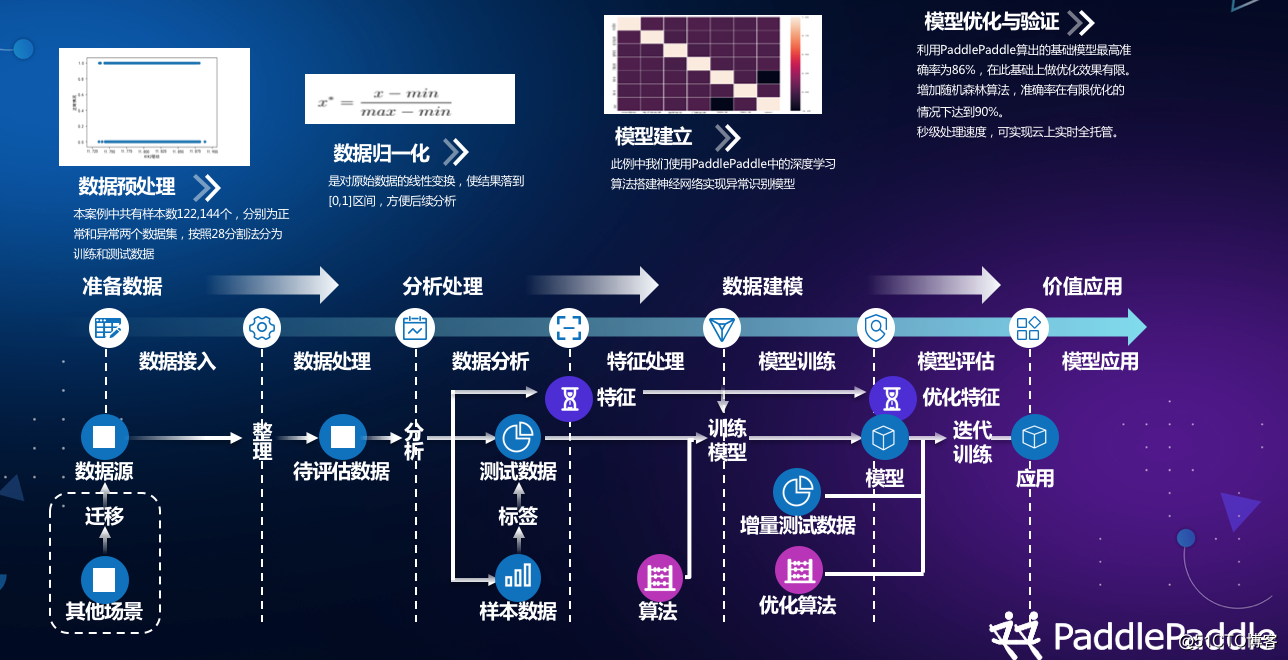
圖三:基於PaddlePaddle的充電樁異常診斷建模
提問環節
提問:充電樁如何聯網?
趙喬:本身充電樁是離線的,我們采取的是在充電樁上出一個加了硬件的槍頭,這個硬件裏面跑的是模型和功能等等,除模型外,上面還加了3G的模塊,這個模塊就是支持IOT標準的工業企業,這樣就能聯網了。
提問:數據如何上傳到雲端到服務器?
趙喬:數據會直接傳上去。算法分別跑在本地和雲端,其中會有一部分跑內部端,在算法要求高實時反饋的情況下,如閉環的反饋是在毫秒級,那算法就要跑在前端,這是不能特別復雜的模型。
提問:通信技術很復雜嗎?
趙喬:不復雜,是一個標準的通信技術,跟4G一樣的業界標準,且本身底層算法不需要開發。
提問:我們現在的算法要上傳到服務器,是在雲區,有沒有什麽解決方法。
趙喬:我們之前的算法在海上信號不好,但是有專用的工業wifi,可能距離是15米,但軟件會比較麻煩。比如先緩存,等聯網了再斷,這樣很麻煩。我覺得這個沒有辦法繞開,如果你的應用要求聯網必須一直聯,可能通過軟件很難做,你只能通過考慮硬件,我們之前想專門用工業WIFI,功率很強。
提問:我在做LT的預算,利用RFID傳感器,采集相當大的wifi信號數據,現在遇到的幾個問題,第一個問題是調用的人工智能的算法,對硬件的算力要求比較高,想問老師是怎麽看這個問題?
趙喬:跟你跑的模型有關系,需要運行的是引擎,比如百度的ERE,需要知道部署地方的環境,會占資源,百度的占十兆資源,還有的不用考慮,編譯好的直接下去。
提問:一部分是在本地,另一部分在雲上?
趙喬:雲上很少,雲上的算力比較大,相當於是不斷訓練模型,但是在端上用,我們的部分是跑在AIM上,其實端不一定是嵌入式,也可以是牽扯硬件,如筆記本。
提問:百度雲平臺對IOT開放嗎?
趙喬:可以,你可以在上面搜百度雲天工。
提問:我想問規劃處理,你們有非數值類型的數據嗎?是一串字符串。
嘉賓女:我們處理這個,只涉及到數值類的,非數值的就是詞項量,你算一些方法嘗試一下。
提問:非數值類型的怎麽處理?
嘉賓女:變成向量。
提問:如果這個字符串不是固定的,有可能是千變萬化的。
嘉賓女:你規劃的目的是什麽?
提問:不會像詞向量那樣,詞可能是約定好的一萬個,可能有很多種,無法做到詞向量。
嘉賓女:還是要回歸到解決問題是什麽,你的目標是想看一下訓練數據的多樣性,你就可以用數據統計的方法設計一些。
提問:我的場景是日誌分析,有很多信息,如用戶名、用戶名的操作方法,這樣會產生很長的字符串,也有很短,那這部分數據怎麽處理。
嘉賓女:給大家分享我們在公司內做項目或者做To B的項目遇到這些問題的思考路徑,上述問題是兩個方向,一個方向是怎樣使得數據更幹凈,讓我確定這個數據對我是否有價值;另外一個問題,這些數據拿到了怎樣去應用。第一個問題,百度的已有數據用的是統一的格式,所以做一些標準和定義。第二個問題,這些數據怎麽用,要想好你要解決的目的是什麽,目標是什麽,用我們掌握的技術和經驗去變通找到方法。
提問:比如說95%提升到99%,提升了4%,提升的那4%具體體現的是什麽?
趙喬:我們和客戶合作是通過大量已有的功能仿生出來,在模型裏跑。4%怎麽算出來的,傳統的是95%,我們拿著這4%,實際上就是0%。無法檢測的數據拿過來,在這上面我們最後做到86%,所以綜合下就是提升4%。
提問:診斷之後,故障的維護也是我們這邊直接去完成?
趙喬:不是,我們做預警或者提前一天或者提前半天預警,但維護還是要人力做的。
提問:那我們現在這個診斷系統,同時可以處理多少個設備的診斷?
趙喬:目前因為我們在合作的客戶實際上是負責了國家電網超過一半的充電樁,所以如果是說後續要增加的話,需要買更多的資源擴容,之所以是分布式系統,這是比傳統系統的優勢。
提問:我們現在存在多個設備需要診斷的話,診斷也是並發性的了?
趙喬:沒錯,剛才所說的這些模型很多是跑在端上的,對於雲上的資源的依賴度沒有那麽大,只不過是把處理出來的數據在雲上做監測,理論上來講所有東西都跑在這裏,所以對這一部分的壓力不算很大。我們做一款硬件,實際上有類似於設備標簽,如果用過MPD的話就專門針對這種標簽進行設計的。
提問:這個產品已經在實際用了是嗎?
趙喬:我們2月份在做,今年7月份在百度開發者大會上公布出來,因為這是個典型的To B的產品,不是To C的產品,不是天貓上可以賣,所以有To B的流程。我們給國家電網報了3萬份的報備量,但是這裏面還有一些沒有解決的問題。之前提到的模型,我們現在只做了其中一部分,真實使用還有很多東西需要去做。
提問:在建模過程中,建模和深度學習的關系,是串聯還是並聯。
趙喬:我們當時做了兩個算法比較,想看深度學習PaddlePaddle的結果,最終比較驗證,這是並聯關系,不是串聯。
實錄結束
趙喬,百度大數據部高級產品經理,負責百度工業大數據產品規劃及項目落地。曾在華為、美國國家儀器從事產品、技術、銷售工作,服務新能源、國防軍工、汽車等典型制造業企業。
基於PaddlePaddle的新能源充電樁智能運維