
論文閱讀 SNAPSHOT ENSEMBLES
引入
1. 隨機梯度下降的特點
隨機梯度下降法(Stochastic Gradient Descent)作為深度學習中主流使用的最優化方法, 有以下的優點:
- 躲避和逃離假的鞍點和局部極小點的能力
這篇論文認為, 這些局部極小也包含著一些有用的信息, 能夠幫助提升模型的能力.
2. 局部極小的意義
神經網絡的最優化一般來說, 不會收斂在全局最小上, 而是收斂在某個局部極小上. 這些局部極小有著好和壞的區別. 而對於好壞的區分, 一般認為:
- 局部極小有著平坦的區域
flat basin, 這些點對應模型的泛化性比較好, 是更好的局部極小
3. SGD與局部極小
SGD在最優化過程中, 會避免陡峭的局部極小
- 計算得到的梯度是由mini-batch得到的, 因此是不精確的
- 當學習率
learning rate比較大的時候, 沿著這個不精確的梯度的某一步移動不會到達具有陡峭局部的極小點
這是SGD在最優化過程中的優點, 避免了收斂域陡峭的局部極小.
但當學習率比較小的時候, SGD方法又趨向於收斂到最近的局部極小.
SGD的這兩種截然不同的行為, 會在訓練的不同階段表現出來:
- 初始階段使用大的學習率, 快速移動到靠近平坦局部極小的區域
- 當搜索進行到沒有提升的階段, 降低學習率, 引導搜索收斂到最終的局部極小裏面
4. 模型訓練與局部極小
局部極小的數量, 隨著模型中參數的增多, 呈指數式增加. 因此神經網絡中的局部極小數不勝數. 同一個模型, 因為初始化的不同, 或者訓練樣本batch
往往在實際中, 不同的局部極小產生的最終的總誤差近似, 但是實際上, 不同局部極小對應的不同模型在預測時會產生不同的錯誤. 這種模型之間的差異在進行Ensemble(投票, 平均)會被利用到, 往往對最終的預測結果都有提升, 因此在各種比賽中, 多模型Ensemble被廣泛使用.
5. Ensemble與神經網絡
由於神經網絡訓練的耗時, 導致多模型的Ensemble在深度學習領域應用不如傳統的機器學習方法廣泛. 因為用於Ensemble的每個基模型, 都是單獨訓練的, 往往單個模型的訓練就比較耗時了, 因此這種提升模型表現的方法成本是相當高的.
這篇論文提出了一種方法, 不需要增加額外的訓練消耗, 通過一次訓練, 得到若幹個模型, 並對這些模型進行Ensemble, 得到最終的模型.
原理
1. 概括
首先, 在對神經網絡使用SGD方法進行訓練時, 利用SGD方法能夠收斂和逃離局部極小的特點, 在一次訓練過程中, 使模型\(M\)次收斂於不同的局部極小, 每次收斂, 都代表這一個最終的模型, 我們將此時的模型進行保存. 然後使用一個較大的學習率逃離此時的局部極小.
在論文中, 對學習率的控制使用了一種余弦函數, 這種函數表現為:
- 急劇提升學習率
- 在某次訓練過程中, 學習率迅速下降
這種訓練方式就像在最優化路程中, 截取了幾個快照Snapshot, 因此命名為Snapshot Ensembling. 下圖中的右半部分就是對這種方法的圖像表現.
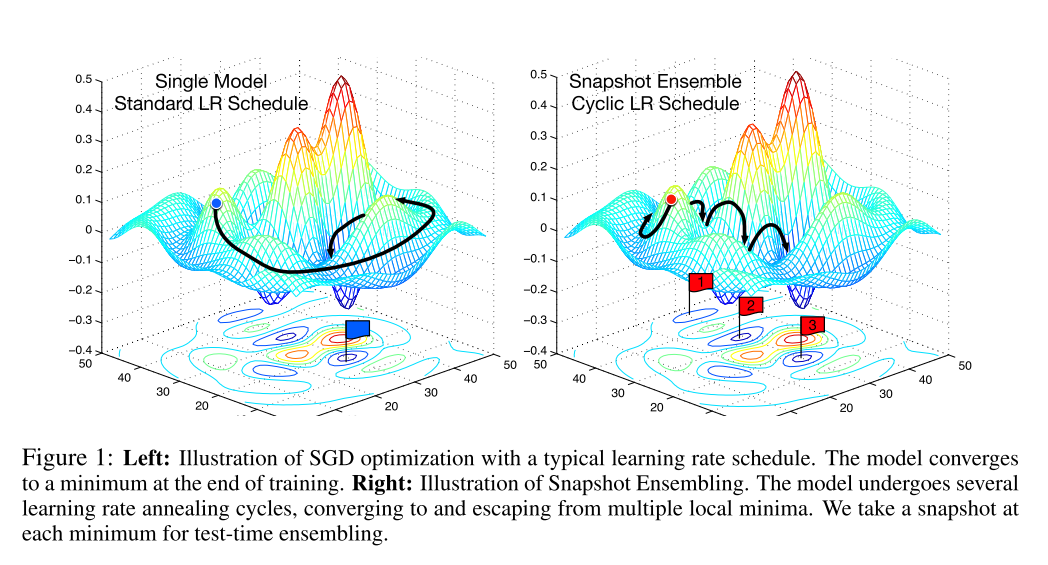
2. 神經網絡的隱式與顯式Ensemble
各種Dropout技術是一種隱式的Ensemble技術, 在訓練的時候, 隨機地將隱藏層中的部分結點, 且在每次訓練過程中隱藏的結點都不相同, 而在訓練時則使用所有結點.
因此, 在使用Dropout技術訓練的過程中, 通過隨機地去除隱藏層的結點, 創建了無數個共享權重的模型. 這些模型在預測的時候, 被隱式地Ensemble在一起.
這篇論文提出的Snapshot Ensemble則是顯式地將多個不共享權值的模型組合在一起, 達到提升的效果.
3. 詳述
總的來說, Snapshot Ensemble就是在一次訓練(最優化)過程中, 在最終收斂之前, 訪問多個局部極小, 在每個局部極小保存快照即作為一個模型, 在預測的使用使用所有保存的模型進行預測, 最後取平均值作為最終結果.
而這些模型保存點(快照點)不是隨意選取的, 我們希望:
- 有盡量小的誤差
- 每個模型誤分類的樣本盡量不要重復, 保證模型的差異性
這就需要在最優化過程中進行一些特別的操作.
觀察標準的最優化路徑, 通常來說, 開發集的誤差只有在學習率下調之後才會急劇下降, 按照正常的學習率下降策略, 上述情況往往會在很多個Epoch之後才會出現.
然而, 很早地降低學習率繼續訓練, 對最後的誤差並不會造成大的影響, 卻極大地提高了訓練的效率, 使得模型在較少的epoch輪數叠代後就達到局部極小成為了可能.
因此, 論文中采用了Cyclic Cosine Annealing方法, 很早地就下調了學習率, 使訓練盡快地到達第一個局部極小, 得到第一個模型. 然後提升學習率, 擾亂模型, 使得模型脫離局部極小, 然後重復上述步驟若幹次, 直到獲取指定數量的模型.
而學習率的變化, 論文中使用如下的函數:
\[\alpha(t)=f(\mod(t-1, \lceil T/M \rceil))\]
其中, \(t\)是叠代輪數, 這裏指的是batch輪數; \(T\)是總的batch數量; \(f\)是單調遞減函數; \(M\)是循環的數量, 也就是最終模型的數量. 換句話說, 我們將整個訓練過程劃分成了\(M\)個循環, 在每個循環的開始階段, 使用較大的學習率, 然後退火到小的學習率. \(\alpha=f(0)\)給予模型足夠的能量脫離局部極小, 而較小的學習率\(\alpha=f(\lceil T/M \rceil)\)又能使模型收斂於一個表現較好的局部極小.
論文中使用如下的shifted cosine function:
\[\alpha(t)=\frac{\alpha_0}{2}(\cos(\frac{\pi\mod(t-1,\lceil T/M \rceil)}{\lceil T/M \rceil})+1)\]
\(\alpha_0\)是初始的學習率, 而\(\alpha=f(\lceil T/M \rceil)\approx0\)這保證了最小的學習率足夠小. 每個batch作為一次循環(而不是每個epoch). 以下是整個學習過程的表現.
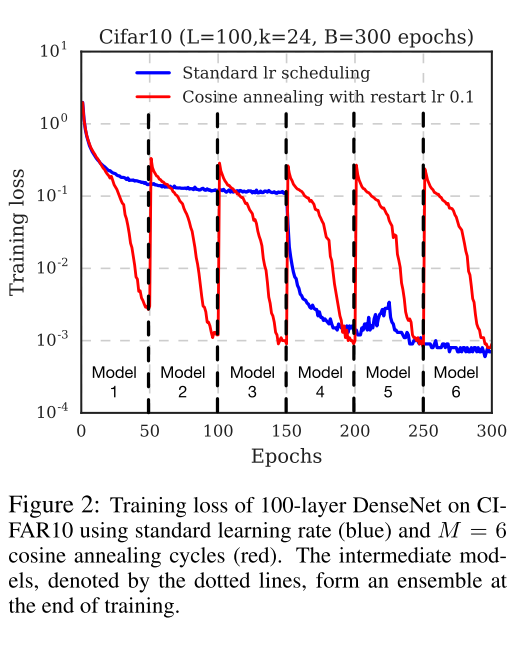
論文閱讀 SNAPSHOT ENSEMBLES