
一文學會目前最火熱的大數據技術
本文由michelmu發表於雲+社區專欄
Elasticsearch是當前主流的分布式大數據存儲和搜索引擎,可以為用戶提供強大的全文本檢索能力,廣泛應用於日誌檢索,全站搜索等領域。Logstash作為Elasicsearch常用的實時數據采集引擎,可以采集來自不同數據源的數據,並對數據進行處理後輸出到多種輸出源,是Elastic Stack 的重要組成部分。本文從Logstash的工作原理,使用示例,部署方式及性能調優等方面入手,為大家提供一個快速入門Logstash的方式。文章最後也給出了一些深入了解Logstash的的鏈接,以方便大家根據需要詳細了解。
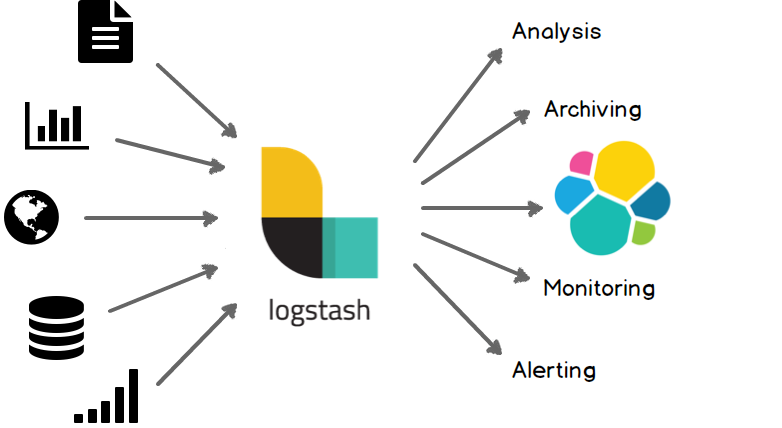 Logstash簡介
Logstash簡介
1 Logstash工作原理
1.1 處理過程
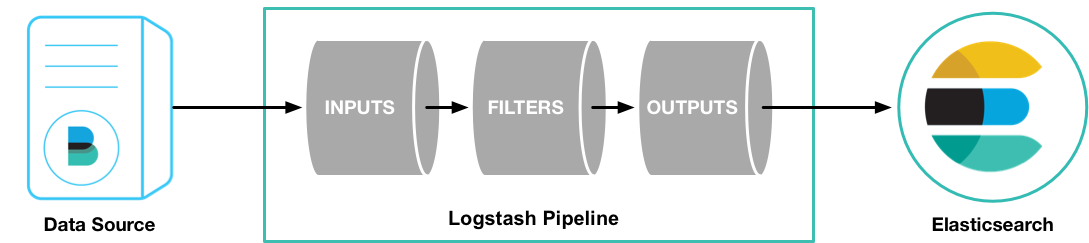 Logstash處理過程
Logstash處理過程
如上圖,Logstash的數據處理過程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs對數據格式進行處理。這四個部分均以插件形式存在,用戶通過定義pipeline配置文件,設置需要使用的input,filter,output, codec插件,以實現特定的數據采集,數據處理,數據輸出等功能
- (1)Inputs:用於從數據源獲取數據,常見的插件如file, syslog, redis, beats 等[詳細參考]
- (2)Filters:用於處理數據如格式轉換,數據派生等,常見的插件如grok, mutate, drop, clone, geoip等[詳細參考]
- (3)Outputs:用於數據輸出,常見的插件如elastcisearch,file, graphite, statsd等[詳細參考]
- (4)Codecs:Codecs不是一個單獨的流程,而是在輸入和輸出等插件中用於數據轉換的模塊,用於對數據進行編碼處理,常見的插件如json,multiline[詳細參考]
可以點擊每個模塊後面的詳細參考鏈接了解該模塊的插件列表及對應功能
1.2 執行模型:
- (1)每個Input啟動一個線程,從對應數據源獲取數據
- (2)Input會將數據寫入一個隊列:默認為內存中的有界隊列(意外停止會導致數據丟失)。為了防止數丟失Logstash提供了兩個特性: Persistent Queues:通過磁盤上的queue來防止數據丟失 Dead Letter Queues:保存無法處理的event(僅支持Elasticsearch作為輸出源)
- (3)Logstash會有多個pipeline worker, 每一個pipeline worker會從隊列中取一批數據,然後執行filter和output(worker數目及每次處理的數據量均由配置確定)
2 Logstash使用示例
2.1 Logstash Hello world
第一個示例Logstash將采用標準輸入和標準輸出作為input和output,並且不指定filter
- (1)下載Logstash並解壓(需要預先安裝JDK8)
- (2)cd到Logstash的根目錄,並執行啟動命令如下:
cd logstash-6.4.0
bin/logstash -e ‘input { stdin { } } output { stdout {} }‘- (3)此時Logstash已經啟動成功,-e表示在啟動時直接指定pipeline配置,當然也可以將該配置寫入一個配置文件中,然後通過指定配置文件來啟動
- (4)在控制臺輸入:hello world,可以看到如下輸出:
{
"@version" => "1",
"host" => "localhost",
"@timestamp" => 2018-09-18T12:39:38.514Z,
"message" => "hello world"
} Logstash會自動為數據添加@version, host, @timestamp等字段
在這個示例中Logstash從標準輸入中獲得數據,僅在數據中添加一些簡單字段後將其輸出到標準輸出。
2.2 日誌采集
這個示例將采用Filebeat input插件(Elastic Stack中的輕量級數據采集程序)采集本地日誌,然後將結果輸出到標準輸出
- (1)下載示例使用的日誌文件[地址],解壓並將日誌放在一個確定位置
- (2)安裝filebeat,配置並啟動[參考]
filebeat.yml配置如下(paths改為日誌實際位置,不同版本beats配置可能略有變化,請根據情況調整)
filebeat.prospectors:
- input\_type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: "localhost:5044"啟動命令:
./filebeat -e -c filebeat.yml -d "publish"- (3)配置logstash並啟動
1)創建first-pipeline.conf文件內容如下(該文件為pipeline配置文件,用於指定input,filter, output等):
input {
beats {
port => "5044"
}
}
#filter {
#}
output {
stdout { codec => rubydebug }
}codec => rubydebug用於美化輸出[參考]
2)驗證配置(註意指定配置文件的路徑):
./bin/logstash -f first-pipeline.conf --config.test_and_exit3)啟動命令:
./bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic選項啟用動態重載配置功能
4)預期結果:
可以在Logstash的終端顯示中看到,日誌文件被讀取並處理為如下格式的多條數據
{
"@timestamp" => 2018-10-09T12:22:39.742Z,
"offset" => 24464,
"@version" => "1",
"input_type" => "log",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}相對於示例2.1,該示例使用了filebeat input插件從日誌中獲取一行記錄,這也是Elastic stack獲取日誌數據最常見的一種方式。另外該示例還采用了rubydebug codec 對輸出的數據進行顯示美化。
2.3 日誌格式處理
可以看到雖然示例2.2使用filebeat從日誌中讀取數據,並將數據輸出到標準輸出,但是日誌內容作為一個整體被存放在message字段中,這樣對後續存儲及查詢都極為不便。可以為該pipeline指定一個grok filter來對日誌格式進行處理
- (1)在first-pipeline.conf中增加filter配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}- (2)到filebeat的根目錄下刪除之前上報的數據歷史(以便重新上報數據),並重啟filebeat
sudo rm data/registry
sudo ./filebeat -e -c filebeat.yml -d "publish"- (3)由於之前啟動Logstash設置了自動更新配置,因此Logstash不需要重新啟動,這個時候可以獲取到的日誌數據如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:24:21.276Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到message中的數據被詳細解析出來了
2.4 數據派生和增強
Logstash中的一些filter可以根據現有數據生成一些新的數據,如geoip可以根據ip生成經緯度信息
- (1)在first-pipeline.conf中增加geoip配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}- (2)如2.3一樣清空filebeat歷史數據,並重啟
- (3)當然Logstash仍然不需要重啟,可以看到輸出變為如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"geoip" => {
"timezone" => "Europe/London",
"ip" => "86.1.76.62",
"latitude" => 51.5333,
"continent_code" => "EU",
"city_name" => "Willesden",
"country_name" => "United Kingdom",
"country_code2" => "GB",
"country_code3" => "GB",
"region_name" => "Brent",
"location" => {
"lon" => -0.2333,
"lat" => 51.5333
},
"postal_code" => "NW10",
"region_code" => "BEN",
"longitude" => -0.2333
},
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:37:46.686Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到根據ip派生出了許多地理位置信息數據
2.5 將數據導入Elasticsearch
Logstash作為Elastic stack的重要組成部分,其最常用的功能是將數據導入到Elasticssearch中。將Logstash中的數據導入到Elasticsearch中操作也非常的方便,只需要在pipeline配置文件中增加Elasticsearch的output即可。
- (1)首先要有一個已經部署好的Logstash,當然可以使用騰訊雲快速創建一個Elasticsearch創建地址
- (2)在first-pipeline.conf中增加Elasticsearch的配置,如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}- (3)清理filebeat歷史數據,並重啟
- (4)查詢Elasticsearch確認數據是否正常上傳(註意替換查詢語句中的日期)
curl -XGET ‘http://172.16.16.17:9200/logstash-2018.10.09/_search?pretty&q=response=200‘- (5)如果Elasticsearch關聯了Kibana也可以使用kibana查看數據是否正常上報
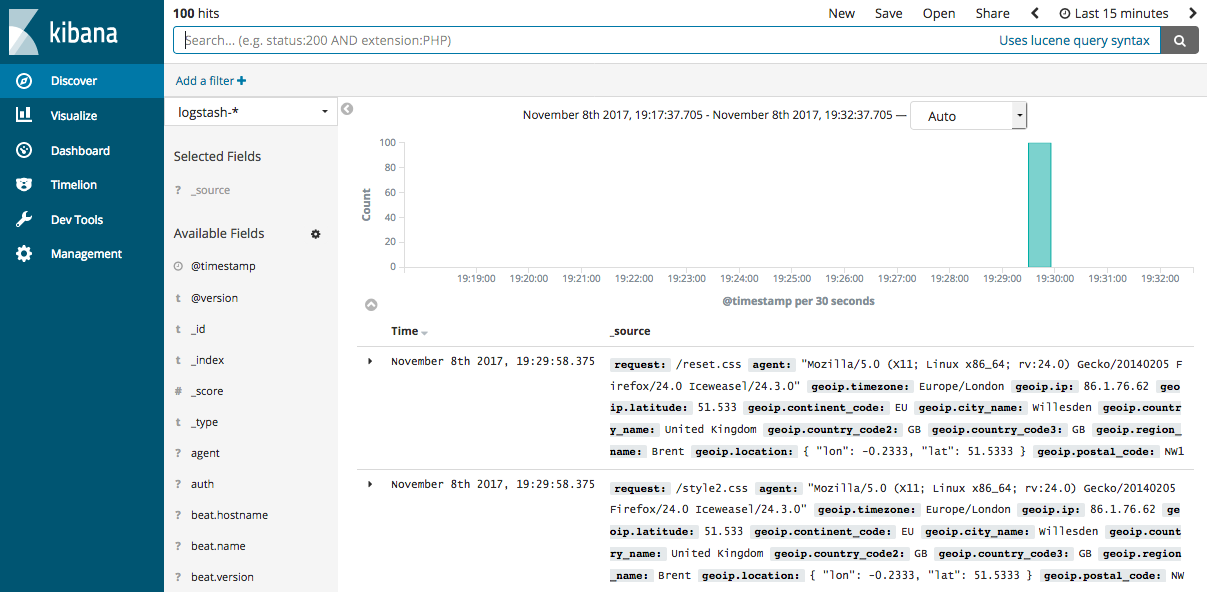 kibana圖示
kibana圖示
Logstash提供了大量的Input, filter, output, codec的插件,用戶可以根據自己的需要,使用一個或多個組件實現自己的功能,當然用戶也可以自定義插件以實現更為定制化的功能。自定義插件可以參考[logstash input插件開發]
3 部署Logstash
演示過如何快速使用Logstash後,現在詳細講述一下Logstash的部署方式。
3.1 安裝
- 安裝JDK:Logstash采用JRuby編寫,運行需要JDK環境,因此安裝Logstash前需要先安裝JDK。(當前6.4僅支持JDK8)
- 安裝Logstash:可以采用直接下載壓縮包方式安裝,也通過APT或YUM安裝,另外Logstash支持安裝到Docker中。[Logstash安裝參考]
- 安裝X-PACK:在6.3及之後版本X-PACK會隨Logstash安裝,在此之前需要手動安裝[參考鏈接]
3.2 目錄結構
logstash的目錄主要包括:根目錄、bin目錄、配置目錄、日誌目錄、插件目錄、數據目錄
不同安裝方式各目錄的默認位置參考[此處]
3.3 配置文件
- Pipeline配置文件,名稱可以自定義,在啟動Logstash時顯式指定,編寫方式可以參考前面示例,對於具體插件的配置方式參見具體插件的說明(使用Logstash時必須配置): 用於定義一個pipeline,數據處理方式和輸出源
- Settings配置文件(可以使用默認配置): 在使用Logstash時可以不用設置,用於性能調優,日誌記錄等 - logstash.yml:用於控制logstash的執行過程[參考鏈接] - pipelines.yml: 如果有多個pipeline時使用該配置來配置多pipeline執行[參考鏈接] - jvm.options:jvm的配置 - log4j2.properties:log4j 2的配置,用於記錄logstash運行日誌[參考鏈接] - startup.options: 僅適用於Lniux系統,用於設置系統啟動項目!
- 為了保證敏感配置的安全性,logstash提供了配置加密功能[參考鏈接]
3.4 啟動關閉方式
3.4.1 啟動
- 命令行啟動
- 在debian和rpm上以服務形式啟動
- 在docker中啟動3.4.2 關閉
- 關閉Logstash
- Logstash的關閉時會先關閉input停止輸入,然後處理完所有進行中的事件,然後才完全停止,以防止數據丟失,但這也導致停止過程出現延遲或失敗的情況。
3.5 擴展Logstash
當單個Logstash無法滿足性能需求時,可以采用橫向擴展的方式來提高Logstash的處理能力。橫向擴展的多個Logstash相互獨立,采用相同的pipeline配置,另外可以在這多個Logstash前增加一個LoadBalance,以實現多個Logstash的負載均衡。
4 性能調優
[詳細調優參考]
-
(1)Inputs和Outputs的性能:當輸入輸出源的性能已經達到上限,那麽性能瓶頸不在Logstash,應優先對輸入輸出源的性能進行調優。
-
(2)
系統性能指標
:
- CPU:確定CPU使用率是否過高,如果CPU過高則先查看JVM堆空間使用率部分,確認是否為GC頻繁導致,如果GC正常,則可以通過調節Logstash worker相關配置來解決。
- 內存:由於Logstash運行在JVM上,因此註意調整JVM堆空間上限,以便其有足夠的運行空間。另外註意Logstash所在機器上是否有其他應用占用了大量內存,導致Logstash內存磁盤交換頻繁。
- I/O使用率: 1)磁盤IO: 磁盤IO飽和可能是因為使用了會導致磁盤IO飽和的創建(如file output),另外Logstash中出現錯誤產生大量錯誤日誌時也會導致磁盤IO飽和。Linux下可以通過iostat, dstat等查看磁盤IO情況 2)網絡IO: 網絡IO飽和一般發生在使用有大量網絡操作的插件時。linux下可以使用dstat或iftop等查看網絡IO情況
-
(3)
JVM堆檢查
:
- 如果JVM堆大小設置過小會導致GC頻繁,從而導致CPU使用率過高
- 快速驗證這個問題的方法是double堆大小,看性能是否有提升。註意要給系統至少預留1GB的空間。
- 為了精確查找問題可以使用jmap或VisualVM。[參考]
- 設置Xms和Xmx為相同值,防止堆大小在運行時調整,這個過程非常消耗性能。
- (4)Logstash worker設置: worker相關配置在logstash.yml中,主要包括如下三個: - pipeline.workers: 該參數用以指定Logstash中執行filter和output的線程數,當如果發現CPU使用率尚未達到上限,可以通過調整該參數,為Logstash提供更高的性能。建議將Worker數設置適當超過CPU核數可以減少IO等待時間對處理過程的影響。實際調優中可以先通過-w指定該參數,當確定好數值後再寫入配置文件中。 - pipeline.batch.size: 該指標用於指定單個worker線程一次性執行flilter和output的event批量數。增大該值可以減少IO次數,提高處理速度,但是也以為這增加內存等資源的消耗。當與Elasticsearch聯用時,該值可以用於指定Elasticsearch一次bluck操作的大小。 - pipeline.batch.delay: 該指標用於指定worker等待時間的超時時間,如果worker在該時間內沒有等到pipeline.batch.size個事件,那麽將直接開始執行filter和output而不再等待。
結束語
Logstash作為Elastic Stack的重要組成部分,在Elasticsearch數據采集和處理過程中扮演著重要的角色。本文通過簡單示例的演示和Logstash基礎知識的鋪陳,希望可以幫助初次接觸Logstash的用戶對Logstash有一個整體認識,並能較為快速上手。對於Logstash的高階使用,仍需要用戶在使用過程中結合實際情況查閱相關資源深入研究。當然也歡迎大家積極交流,並對文中的錯誤提出寶貴意見。
MORE:
- Logstash數據處理常見示例
- Logstash日誌相關配置參考
- Kibana管理Logstash pipeline配置
- LogstashModule
- 監控Logstash
相關閱讀
大數據基礎系列之spark的監控體系介紹
Neutron lbaas代理https實踐
【每日課程推薦】機器學習實戰!快速入門在線廣告業務及CTR相應知識
此文已由作者授權騰訊雲+社區發布,更多原文請點擊
搜索關註公眾號「雲加社區」,第一時間獲取技術幹貨,關註後回復1024 送你一份技術課程大禮包!
海量技術實踐經驗,盡在雲加社區!
一文學會目前最火熱的大數據技術