
陣列、連結串列和樹的演進
我們最常用的資料結構就是樹,最基礎的資料結構是陣列,那麼樹在陣列的基礎上解決了什麼問題?為什麼用樹而不用陣列?下面我們來詳細的剖析一下:
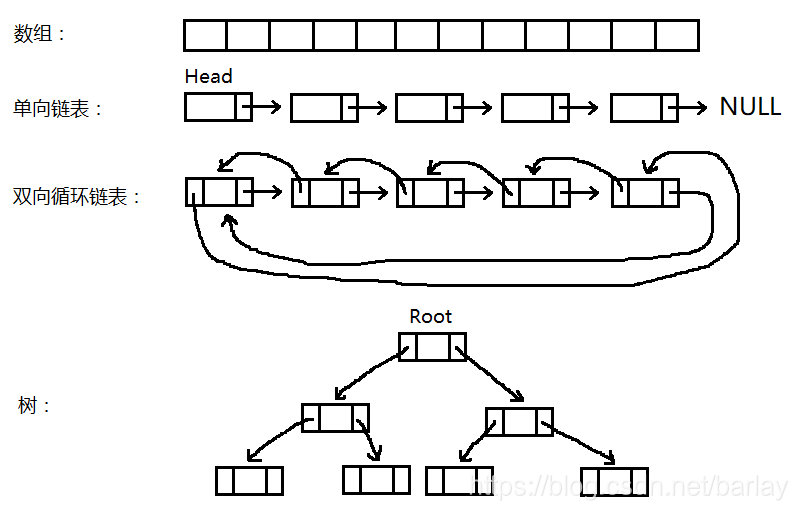
上面的圖是陣列、連結串列和樹的示意圖,可以看到,陣列中的元素沒有指標,單向連結串列有一個指標,雙向連結串列有兩個指標,它們都是表示的順序關係,也就是說,陣列的下一個元素肯定挨著上一個元素,單向連結串列指標指向的肯定是下一個元素,雙向連結串列的右指標指向的是下一個元素,左指標指向的是上一個元素。它們之間除了順序關係之外就沒有其它的關係了。
下面我們在雙向連結串列的基礎上引入大小關係,也就是樹的元素的左指標指向的樹中的所有元素都比當前元素的值要小,樹的元素的右指標指向的樹中的所有元素都比當前元素的值要大,這樣,這棵樹就是一顆二叉搜尋樹,如果左右子樹的高度相差不超過1,那麼這棵樹就叫做平衡二叉樹,也叫AVL樹。
這樣,樹其實是把陣列和連結串列的優點整合起來了。對陣列的操作:排序和二叉搜尋對於AVL樹來說是天生支援的,可以說AVL樹就是為這兩種操作而生的。
可以參考一下部落格:
1分鐘瞭解MyISAM與InnoDB的索引差異
【經典資料結構】B樹與B+樹
PS:很多人理解的陣列就是資料的容器,但是如果但從容器的角度上來理解陣列的話是有一定的侷限性的。容器是用來存資料的,但是針對容器的操作不只是存資料,他還包括資料的增刪改查,其中增和查是重中之重,因為我們新增的話得要保證查詢的高效性,而查詢到對應的資料的話才能修改和刪除,所以容器應該首先滿足查詢的高效性。而HashMap這種資料結構是查詢效率最高的,因為的它的查詢時間複雜度是O(1),沒有比它的查詢效率更高的資料結構了。這也就是為什麼面試經常問到HashMap的底層原理,因為它的使用頻率最高,而它使用頻率高的原因是查詢效率最高。
可以看到,資料結構其實是為演算法實現的,是為了滿足某種演算法的高效性而實現的。資料結構和演算法不是獨立存在的,而是相互依存的。沒有資料結構,談不上演算法,沒有演算法,就不會出現對應的資料結構。可以說是肉體和靈魂的關係。