
從陣列、連結串列到雜湊
為什麼我們需要各種各樣的資料結構?
對我們而言,通常對於資料的操作無外乎以下幾種方式:增、刪、改、查。其中除增加外,其他幾種操作均要求對集合進行搜尋。而結構化的資料模型可以通過陣列、連結串列或者樹形結構等建立,不同的建模方式對於資料處理中的各種操作有不同的效能表現。一般來講,資料結構將直接影響對其處理的演算法的選擇,在本文中的雜湊函式演算法又會反過來影響散列表這種結構之於資料的存貯效率,可以說,資料結構與演算法的關係就好比是一卵雙生。
陣列、連結串列儲存資料的方式
下面通過一張圖讓我們看清陣列和連結串列是如何儲存集合中的資料的:
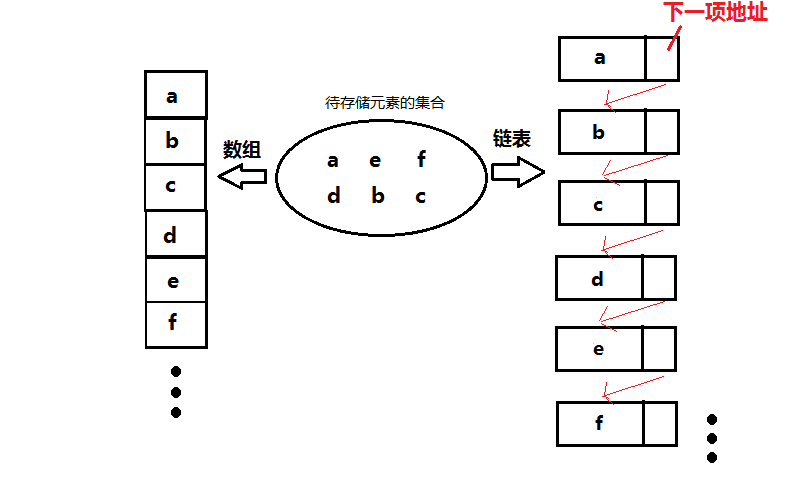
通過上圖我們可以得到以下發現:
用陣列儲存資料,我們利用了陣列單元在物理位置上的鄰接關係來表示表中元素之間的邏輯關係。由於這個原因,用陣列有如下的優缺點。
優點是:
無須為表示表中元素之間的邏輯關係增加額外的儲存空間;
可以方便地隨機訪問表中任一位置的元素。
缺點是:
插入和刪除運算不方便,除表尾的位置外,在表的其他位置上進行插入或刪除操作都必須移動大量元素,其效率較低;
由於陣列要求佔用連續的儲存空間,儲存分配只能預先進行靜態分配。因此,當表長變化較大時,難以確定陣列的合適的大小。確定大了將造成浪費。
用單向連結串列儲存資料,一個單向連結串列的節點被分成兩個部分。第一個部分儲存或者顯示關於節點的資訊,第二個部分儲存下一個節點的地址,而最後一個節點則指向一個空值。。單向連結串列只可向一個方向遍歷。一般查詢一個節點的時候需要從第一個節點開始每次訪問下一個節點,一直訪問到需要的位置。由於這個原因,用連結串列有如下的優缺點。
優點是:
向連結串列中插入或者從連結串列中刪除一項的操作不需要移動很多項,而只涉及常數個節點的鏈的改變。
缺點是:
在刪除最後一項比較複雜,因為必須找出指向最後節點的項,把它的next鏈改為null,然後再更新持有最後節點的鏈。
其無法提供隨機訪問能力,單向連結串列只可向一個方向遍歷。
- 最後我們知道這兩種結構對儲存空間的利用率都很高,誰說這不是一個優點呢,至少對於雜湊來說是的。
- 而雜湊是一種用於以常數平均時間執行插入、刪除和查詢的技術。但是那些需要元素間任何排序資訊的操作將不會得到有效支援。
什麼是雜湊
在解釋雜湊的含義之前,我們先來深入的觀察一下普通陣列這種資料結構,由上圖所示,將集合{a,b,c,d,e,f}儲存在陣列中時佔據了索引為0~5的6個儲存空間,我們可以形式化的表示為有序對(An ordered pair)的集合,即{(a,0),(b,1),(c,2),(d,3),(e,4),(f,5)}。但其實這個集合中任意一個有序對的元素之間的關係是未定義的(undefined),因此這樣的有序對集合可以有6!個。然而我們是否可以構造一個關係,使得待儲存的集合{a,b,c,d,e,f}中的任意一個元素通過這個關係都能找到一個指定的索引值,由下圖更形象的表示:
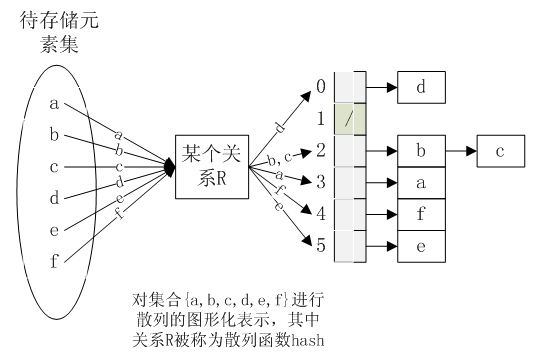
根據上圖我們知道原有集合中的元素被雜湊之後所得到的有序對的集合為{(d,0),(b,2),(c,2),(a,3),(f,4),(e,5)}。其中,散列表中的1號槽為空,表示經過雜湊函式作用之後,原集合中沒有任何元素被雜湊至該位置,而2號槽中則存在兩個元素,將兩個不同元素雜湊至相同位置的情形我們稱為碰撞(Collision)。如上圖所示,我們通過使用連結串列將不同元素連結起來解決碰撞,在後文中還將介紹另外一種稱為開放定址(Open addressing)的解決方法。這裡更具體的說明一下連結法的連結形式:因為雜湊至同一個槽的元素並無順序上的先後要求,因此為效率計,我們將總是採用在連結串列頭插入碰撞元素的做法,最終導致的結果是,在一個連結串列中,越靠近表頭的節點,在原陣列中被雜湊的次序越靠後。綜上所述,可以對雜湊函式hash進行如下形式化定義:
設在大小為N的集合中存在元素elem,儲存原集合中元素的散列表共有m個槽位,則有
hash: elem→γ∈{0,1,2,…,m-1}
這就是雜湊的基本想法。剩下的問題就是要選擇一個函式,決定當兩個關鍵字雜湊到同一個值的時候(碰撞)應該做什麼以及如何確定散列表的大小。
雜湊函式
這個雜湊函式涉及關鍵字中的所有字元,並且一般可以分佈得很好。這個雜湊函式利用到事實:允許溢位。這可能會引進負數,因此在末尾有附加的測試。
這個雜湊函式就表的分佈而言未必是最好的,但確實具有極其簡單的優點而且速度也很快。如果關鍵字特別長,那麼該雜湊函式計算起來將會花費過多的時間。在這種情況下通常的經驗是不適用所有的字元。
public static int hash(String key,int tableSize){
int hashVal = 0;
for(int i = 0; i <key.length(); i++)
hashVal = 37*hashVal + key.charAt(i);
hashVal %= tableSize;
if(hashVal < 0)
hashVal += tableSize
return hashVal;
}剩下的主要問題就是如果解決衝突的消除問題。如果當一個元素被插入時域一個已經插入的元素雜湊到相同的值,那麼就會產生一個衝突,這個衝突需要消除。解決這種衝突的方法有幾種,我們將討論其中最簡單的兩種:分裂連結法和開放定址法。
分離連結法
解決衝突的第一種方法叫做分離連結法(separate chaining),其做法是將雜湊到用一個值的所有元素儲存到一個表中。
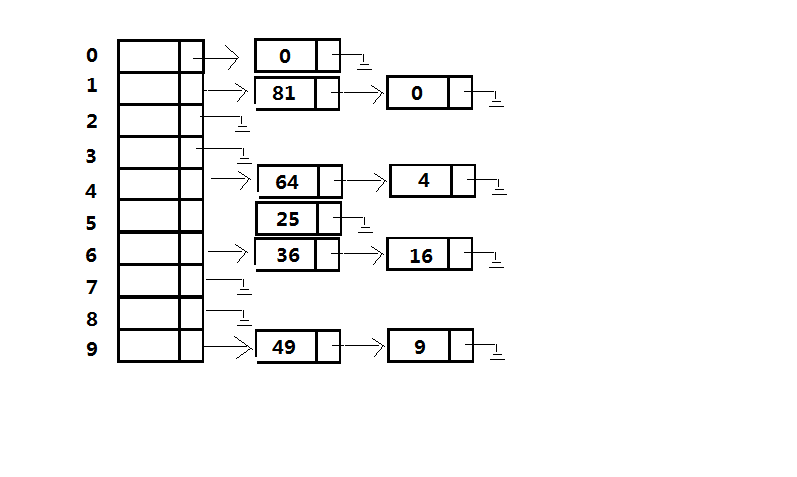
為執行一次查詢,我們使用雜湊函式來確定究竟遍歷哪一個連結串列。然後我們再在確定的連結串列中執行一次查詢。為了執行insert,我們檢查相應的連結串列看看該元素是否已經處在合適的位置(如果允許插入重複元,那麼通常需要留出一個格外的域,這個域當出現匹配事件時增1)。如果這個元素是個新元素,那麼它將被插入到連結串列的前端,這不僅因為方便,還因為常常發生這樣的事實:新近插入的元素最有可能不久又被訪問。
緊接著我們需要考慮:散列表的大小為多少較好?
設所有元素之間均相互獨立,且每個元素被雜湊至每個槽的概率均相等 ————> 假設①
並設原集合的尺寸為n,散列表的大小為m,裝載因子α=n/m ————–>假設②
最重要的是,我們並不考慮雜湊函式所消耗的計算開銷 —————->假設③
由假設①,元素被雜湊至每個槽的概率相等,再根據假設②中散列表的大小為m,有P{elem→γ∈{0,1,2,…,m-1}}=1/m
設待查詢的關鍵字為k,因此存在兩種情況:Ⅰ、待查詢關鍵字k不存在; Ⅱ、關鍵字k存在
然而其實情況Ⅰ的搜尋開銷即為情況Ⅱ的最壞情況執行時間,因為關鍵字k不存在時將查詢整個連結串列
以下是更詳細的分析:
——>Ⅰ、由假設①,並且根據假設②有裝載因子α=n/m,所以α表示每個槽的結點數。因為當待查詢的關鍵字k不存在時,我們必將搜尋到該槽中的最後一個結點處,因此在這種情況下的搜尋開銷為O(α)。
——>Ⅱ、對於關鍵字k存在的情況,其實不做詳細分析我們就已經知道,這種情況下的執行時間必然不超過O(α),然而單單分析本身就是一件很有趣的事情,為何不做得徹底一些?更重要的是,下面所用到的這種方法,其體現的思想對於分析隨機過程將具有極大的益處。

綜上可知,如果我們將散列表設定為與原集合大小相同時,裝載因子α=1,此時的搜尋時間為O(1),但其實設定為原集合尺寸的1/2或是2倍並沒有多大區別。需要注意的是雖然散列表越大導致搜尋時間減少,但其所佔記憶體空間將會增大。
開放定址法
分離連結雜湊演算法的缺點是使用一些連結串列。由於給新單元分配地址需要時間(特別是其他語言中),因此這就導致演算法的速度有一些減慢,同時演算法實際上還要求對第二種資料結構的實現。同連結法一樣,開放定址是一種用於解決碰撞的策略。不同之處在於,在連結法中,每個關鍵字只能對應一個固定的槽,而在開放定址中,每個關鍵字可以對應算列表中中的多個槽,因為有可能在首次定址過程中,該槽已被先前的關鍵字所佔據,因而接下來我們根據事先所制定的某個規則繼續試探下一個槽是否可用,直至找到一個可用的槽並將關鍵字儲存在其中為止。一般來說,因為所有的資料都要放置如表內,所以這方法需要的表的大小要比分離連結雜湊的表大,而且其裝填因子應該低於α=0.5。我們把這樣的表叫做探測散列表。
線性探測法
設 hash(key, i)=(hash’(key)+i) mod m,其中 i=0,1,…,m-1,hash’為輔助雜湊函式
線上性試探中,首次探查位置取決於hash’(key)的值,若發生碰撞,則接下來所探查的位置為(hash’(key)+1) mod m,從而所形成的探查序列為
平方探測法
設 hash(key,i)=(hash’(key)+c1i+c2i2) mod m,如上所述,i=0,1,…,m-1,hash’為輔助雜湊函式,c1,c2為輔助引數
可以發現,線性試探法實際是二次試探的特殊情況,若取引數c1=1,c2=0,那麼二次試探將“退化”為線性試探。同樣的,整個探查序列也是由hash’(key)所決定的,因為雖然探查序列中各元素之間的增量[c1i+c2i2]不再以線性的方式進行,但對於每個元素來說,引導因子i總是以步長1的方式遞增,這就導致所有元素的探查序列的增加方式是相同的,因此整個散列表同樣提供m種不同的探查序列。但隨著散列表中元素的增加,這種跳躍式的增量方式使得插入/搜尋操作的執行時間受到的影響較小。
雖然平方探測排除了一次聚集,但是雜湊到同一個位置上的那些元素將探測相同的備選單元,這叫做二次聚集。二次聚集是理論上的一個小缺憾。對於每次查詢,它一般要引起另外的少於一半的探測。下面的技術將會排除這個缺憾,不過這要付出計算一個附加的雜湊函式的代價。
雙雜湊
設 hash(key,i)=(hash’(key)+i×hash”(key)) mod m,其中i=0,1,…,m-1,hash’,hash”均為輔助雜湊函式
雙重試探法的首個探查位置為hash’(key),當產生碰撞之後,接下來的探查位置為(hash’(key)+hash”(key)) mod m,因此我們發現在雙重試探法中,不僅初始探查位置依賴於關鍵字key,探查序列中的增量hash”(key)同樣依賴於關鍵字key,因而整個散列表提供了m2種不同的探查序列,較之於前兩種開放定址具備了更多的靈活性。這裡還要注意的是應保證hash”(key)與m互質,因為根據固定的偏移量所定址的所有槽將形成一個群,若最大公約數p=gcd(m, hash”(key))>1,那麼所能定址的槽的個數為m/p
再雜湊
對於使用平方探測的開放定址雜湊法,如果散列表被填的太滿,那麼操作的執行時間將開始消耗過長,且插入操作可能失敗。這可能發生在有太多的移動和插入混合的場景。此時,一種解決方法是建立一個大約兩倍大的表(並且使用一個相關的新雜湊函式),掃描整個原始散列表,計算每個(未刪除的)元素的新雜湊值並將其插入到新表中。
整個操作就叫做再雜湊(rehashing)。顯然這時一種開銷非常大的操作,其執行時間為O(N) ,因為有N個元素要再雜湊而表的大小約為2N,不過,由於不是經常發生。因此實際效果根本沒有那麼差。特別是在最後的再雜湊之前必然已經存在N/2次insert,因此新增到每個插入上的發費基本上是一個常數開銷。如果這種資料結構是程式的一部分,那麼其影響是不明顯的。
再雜湊可以用平方探測以多種方法實現。一種做法是隻要表滿到一半就再雜湊。另一種極端的方法是隻有當插入失敗時才再雜湊。第三種方法即途中策略:當散列表到達某一個裝填因子時進行再雜湊。由於隨著裝填因子的增長散列表的效能確實下降,所以第三種方式可能是理想的策略。