
深度學習研究理解6:OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks
本文是紐約大學Yann LeCun團隊中Pierre Sermanet ,David Eigen和張翔等在13年撰寫的一篇論文,本文改進了Alex-net,並用影象縮放和滑窗方法在test資料集上測試網路;提出了一種影象定位的方法;最後通過一個卷積網路來同時進行分類,定位和檢測三個計算機視覺任務,並在ILSVRC2013中獲得了很好的結果。
一,介紹
卷積網路的主要優勢是提供end-to-end解決方案;劣勢就是對於標籤資料集很貪婪。所以在大的資料集上面取得了很大的突破,但是在小的資料集上面突破不是很大。
ImageNet資料集上的分類圖片,物體大致分佈在圖片中心,但是感興趣的物體常常在尺寸和位置(以滑窗的方式)上有變化;解決這個問題的第一個想法想法就是在不同位置和不同縮放比例上應用卷積網路。但是種滑窗的可視視窗可能只包涵物體的一個部分,而不是整個物體;對於分類任務是可以接受的,但是對於定位和檢測有些不適合。第二個想法就是訓練一個卷積網路不僅產生類別分佈,還產生一個物體位置的預測和bounding box的尺寸;第三個想法就是積累在每個位置和尺寸對應類別的置信度。
在多縮放尺度下以滑窗的方式利用卷積網路用了偵測和定位很早就有人提出了,一些學者直接訓練卷積網路進行預測物體的相對於滑窗的位置或者物體的姿勢。還有一些學者通過基於卷積網路的影象分割來定位物體。
二,視覺任務
分類:是啥 預測top-5分類
定位:在哪是啥 預測top-5分類+每個類別的bounding box(50%以上的覆蓋率認為是正確的)
檢測:在哪都有啥
定位是介於分類和檢測的中間任務,分類和定位使用相同的資料集,檢測的資料集有額外的資料集(物體比較小)。
三,分類
3.1 引數設定
提取221*221的圖片,batch大小,權值初始值,權值懲罰項,初始學習率和Alex-net一樣。不同地方時就動量項權重從0.9變為0.6;在30, 50, 60, 70, 80次迭代後,學習率每次縮減0.5倍。
3.2模型設計
作者提出了兩種模型,fast模型和accurate模型。
Fast模型:
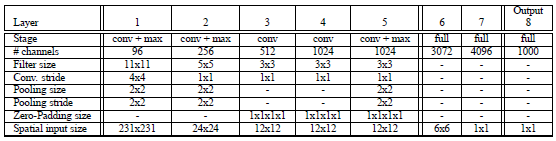
Input(231,231,3)→96F(11,11,3,s=4)→max-p(2,2,s=2)→256F(5,5,96,1) →max-p(2,2,2) →512F(3,3,512,1) →1024F(3,3,1024,1) →1024F(3,3,1024) →max-p(2,2,2) →3072fc→4096fc→1000softmax
Fast模型改進:
1,不使用LRN;
2,不使用over-pooling使用普通pooling;
3,第3,4,5卷基層特徵數變大,從Alex-net的384→384→256;變為512→1024→1024.
4,fc-6層神經元個數減少,從4096變為3072
5,卷積的方式從valid卷積變為維度不變的卷積方式,所以輸入變為231*231
Accurate模型改進:
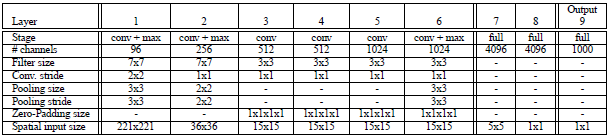
Input(231,231,3)→96F(7,7,3,s=2)→max-p(3,3,3)→256F(7,7,96,1)→max-p(2,2,2) →512F(3,3,512,1) →512F(3,3,512,1) →1024F(3,3,1024,1) →1024F(3,3,1024,1) →max-p(3,3,3) →4096fc→4096fc→1000softmax
1,不使用LRN;
2,不使用over-pooling使用普通pooling,更大的pooling間隔S=2或3
3第一個卷基層的間隔從4變為2(accurate 模型),卷積大小從11*11變為7*7;第二個卷基層filter從5*5升為7*7
4增加了一個第三層,是的卷積層變為6層;從Alex-net的384→384→256;變為512→512→1024→1024.
感覺這個調整和上一篇ZF-net的結構調整很像,畢竟他們都是紐約大學裡面一個團隊的;fast模型使用更小的pooling局域2*2,,增加3,4,5層特徵情況下,減少fc-6層的神經元,保持網路複雜度較小的變化;accurate模型感覺有些暴力,縮小間隔,增加網路深度,增加特徵數;通過提升計算複雜度,來提取更多的資訊,從而提升效果,感覺這個多少有些任性。
兩個模型引數和連線數目對比:
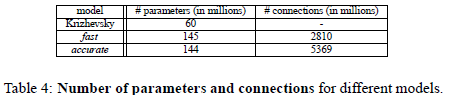
Fast模型比accurate模型的引數還多,這個讓我比較意外;感覺fast模型和Alex-net引數應該差不多,而應該和accurate差很多。但是計算結果讓我有些意外:
每層引數個數:=特徵數M*每個filter大小(filter_x*filter_y*連線特徵數(由於本文是全連線,所以連線特徵數就等於前一層特徵個數))沒有把bias計算在內。
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
Fast |
3.5萬 |
61 |
118 |
0 |
472 |
944 |
11324 |
1678 |
409 |
|
Accurate |
1.4萬 |
120 |
118 |
236 |
472 |
944 |
10485 |
1678 |
409 |
通過計算髮現,連線方式,特徵數目,filter尺寸是影響引數個數的因素;
1連線方式是關鍵因素,例如主要引數都分佈在全連線層;
2最後一個卷基層特徵圖的大小也是影響引數個數的關鍵,例如第七層fast模型的特徵圖為6*6; accurate模型的輸入特徵為5*5,所以儘管accurate比fast多了1024個全連線神經元,但是由於輸入特徵圖相對較小,多所以本層兩個模型的引數差的不多。所以最後一個卷基層特徵圖大小對引數影響較大。
3.2 多尺寸分類測試
Alex-net中,使用multi-view的方式來投票分類測試;然而這種方式可能忽略影象的一些區域,在重疊的view區域會有重複計算;而且還只在單一的圖片縮放比例上測試圖片,這個單一比例可能不是反饋最優的置信區域。
作者在多個縮放比例,不同位置上,對整個圖片密集地進行卷積計算;這種滑窗的方式對於一些模型可能由於計算複雜而被禁止,但是在卷積網路上進行滑窗計算不僅保留了滑窗的魯棒性,而且還很高效。每一個卷積網路的都輸出一個m*n-C維的空間向量,C是分類的類別數;不同的縮放比例對應不同的m和n。
整個網路的子取樣比例=2*3*2*3=36,即當應用網路計算時,輸入影象的每個維度上,每36個畫素才能產生一個輸出;在影象上密集地應用卷積網路,對比10-views的測試分類方法,此時粗糙的輸出分佈會降低準確率(沒想明白,怎麼就粗糙了);因為物體和view可能沒有很好的匹配分佈(物體和view越好的匹配,網路輸出的置信度越高)。為了繞開這個問題,我們採取在最後一個max-pooling層換成offset max-pooling,平移pooling;這種平移max-pooling是一種資料增益技術。
offset max-pooling:
平移量△:x,y連個維度平移量都為0,1,2(由於pooling區域為3*3)
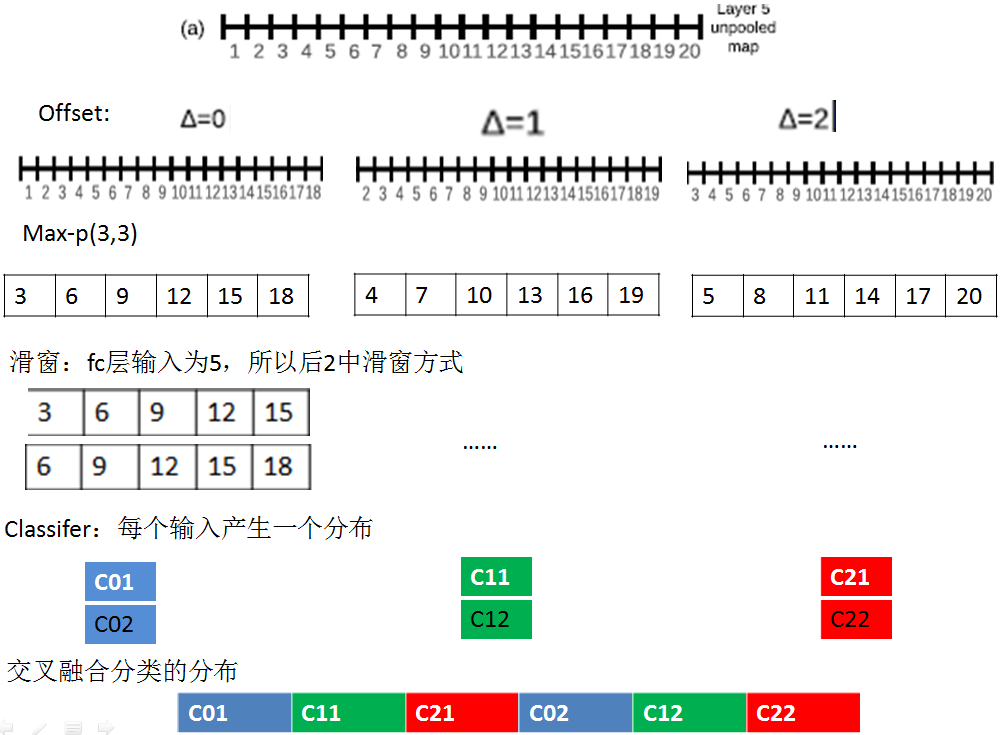
Step1計算特徵圖:計算layer-5未pooling的特徵圖unpooling-FM
Step2平移特徵圖:按照平移量產生不同的平移特徵圖;本文是x,y連個維度,每個維度平移量為0,1,2.所以每個unpooling-FM,產生9種平移特徵圖offset-pooling FM(一維的是3種)。
Step3 max-pooling:在每個平移offset-pooling FM圖上,進行普通的max-pooling操作產生pooled FM。
Step4滑窗提取輸入:由於全連線層fc的輸入維數和pooled FM特徵維數不同,一般pooled FM較大,例如上圖中一維的例子,pooled FM維數為6,而fc的輸入維數為5,所以可以採用滑窗的方式來提取不同的輸入向量。
Step5 輸入分類器:產生分類向量
Step6 交叉融合。
通過上面的這種方式,可以減少子取樣比例,從36變為12;因為通過offset,每個維度產生了3個pooled輸出。此外,由於每個輸入視窗對應不同的原始影象位置,所以通過這種密集滑窗的方式可以找到物體和視窗很好的匹配,從而增加置信度;但是感覺好複雜啊。
實驗結果:
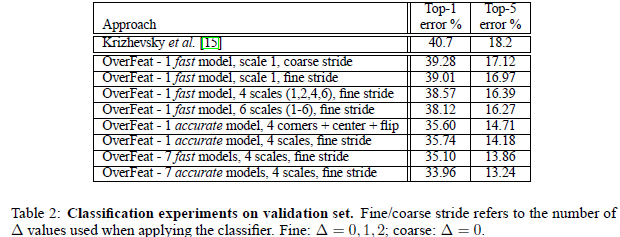
1,fast模型,比Alex-net結果提升了近1%,但是fast模型修改了很多地方,具體哪一個地方的修改其作用,這個不清楚。本文Alex-net模型結果為18.2%比他們自己測試的高2%左右
2,accurate模型單個模型提升了近4%,說明增大網路可以提高分類效果。
3,採用offset max-pooling感覺提升效果很小,感覺是因為卷積特徵啟用值具有很高的聚集性,每個offset特徵圖很相似,max-pooling後也會很相似。
4,多個縮放比例測試分類對於結果提升比較重要,通過多個比例可以把相對較小的物體放大,以便於特徵捕捉。
3.5 卷積網路和滑窗效率
對比很多sliding-windows方法每次都需要計算整個網路,卷積網路非常高效,因為卷積網路在重疊區域共享計算。
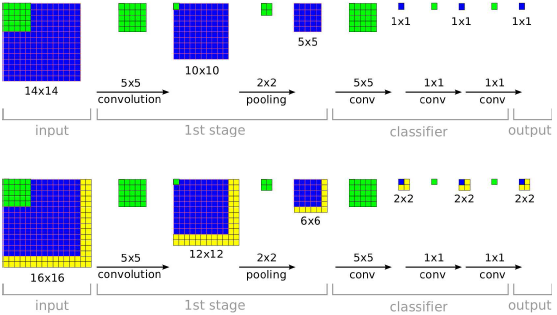
例如訓練階段在小的view(如圖,14*14)下,訓練網路;測試階段在多個較大的圖片上測試,由於每個14*14的view區域產生一個分類預測分佈,上圖在16*16的圖片上測試,有4個不同的14*14的view,所以最後產生一個4個分類預測分佈;組成一個具有C個特徵圖的2*2分類結果圖,然後按照1*1卷積方式計算全連線部分;這樣整個系統類似可以看做一個完整的卷積系統。
四 定位
基於訓練的分類網路,用一個迴歸網路替換分類器網路;並在各種縮放比例和view下訓練迴歸網路來預測boundingbox;然後融合預測的各個bounding box。
4.1 生成預測
同時在各個view和縮放比例下計算分類和迴歸網路,分類器對類別c的輸出作為類別c在對應比例和view出現的置信分數;
4.2 迴歸訓練
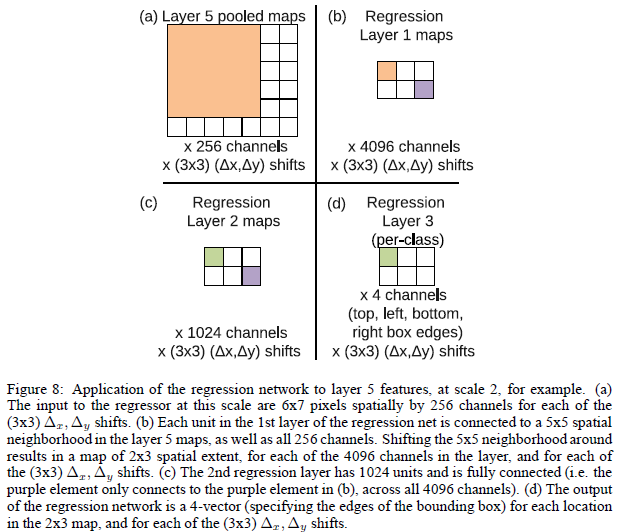
如上圖所示,每個迴歸網路,以最後一個卷積層作為輸入,迴歸層也有兩個全連線層,隱層單元為4096,1024(為什麼作者沒有說,估計也是交叉實驗驗證的),最後的輸出層有4個單元,分別是預測bounding box的四個邊的座標。和分類使用offset-pooling一樣,迴歸預測也是用這種方式,來產生不同的預測結果。
使用預測邊界和真實邊界之間的L2範數作為代價函式,來訓練迴歸網路。最終的迴歸層是一個類別指定的層,有1000個不同的版本。訓練迴歸網路在多個縮放比例下對於不同縮放比例融合非常重要。在一個比例上訓練網路在原比例上表現很好,在其他比例上也會表現的很好;但是多個縮放比例訓練讓預測在多個比例上匹配更準確,而且還會指數級別的增加預測類別的置信度。

上圖展示了在單個比例上預測的在各個offset和sliding window下 pooling後,預測的多個bounding box;從圖中可以看出本文通過迴歸預測bounding box的方法可以很好的定位出物體的位置,而且bounding box都趨向於收斂到一個固定的位置,而且還可以定位多個物體和同一個物體的不同姿勢。但是感覺offset和sliding window方式,通過融合雖然增加了了準確度,但是感覺好複雜;而且很多的邊框都很相似,感覺不需要這麼多的預測值。就可以滿足超過覆蓋50%的測試要求。
4.3結合預測
a)在6個縮放比例上執行分類網路,在每個比例上選取top-k個類別,就是給每個圖片進行類別標定Cs
b)在每個比例上執行預測boundingbox網路,產生每個類別對應的bounding box集合Bs
c)各個比例的Bs到放到一個大集合B
d)融合bounding box。具體過程應該是選取兩個bounding box b1,b2;計算b1和b2的匹配分式,如果匹配分數大於一個閾值,就結束,如果小於閾值就在B中刪除b1,b2,然後把b1和b2的融合放入B中,在進行迴圈計算。
最終的結果通過融合具有最高置信度的bounding box給出。
具體融合過程見下圖:
1,不同的縮放比例上,預測結果不同,例如在原始影象上預測結果只有熊,在放大比例後(第三,第四個圖),預測分類中不僅有熊,還有鯨魚等其他物體

2通過offset和sliding window的方式可以有更多的類別預測

3在每個比例上預測bounding box,放大比例越大的圖片,預測的bounding box越多
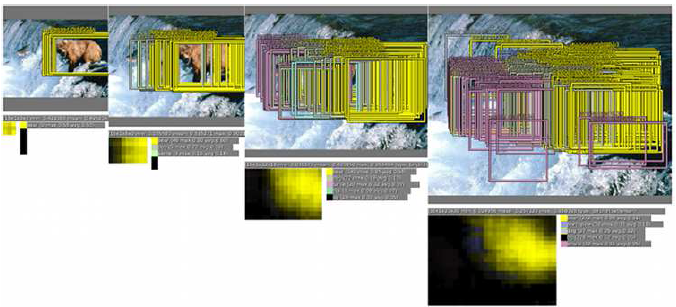
4,融合bouding box

在最終的分類中,鯨魚預測和其他的物體消失不僅使因為更低的置信度,還有就是他們的bounding box集合Bs不像熊一樣連續,具有一致性,從而沒有持續的置信度積累。通過這種方式正確的物體持續增加置信度,而錯誤的物體識別由於缺少bounding box的一致性和置信度,最終消失。這種方法對於錯誤的物體具有魯棒性(但是圖片中確實有一些魚,雖然不是鯨魚;但是系統並沒有識別出來;也可能是類別中有鯨魚,但是沒有此種魚的類別)。
4.4實驗
本文多個multi-scale和multi-view的方式非常關鍵,multi-view降低了4%,multi-scale降低了6%。令人驚訝的是本文PCR的結果並沒有SCR好,原因是PCR的有1000個模型,每個模型都是用自己類別的資料來進行訓練,訓練資料不足可能導致欠擬合。而SCR通過權值共享,得到了充分的訓練。
五,檢測
檢測和分類訓練階段相似,但是是以空間的方式進行;一張圖片中的多個位置可能會同時訓練。和定位不通過的是,圖片內沒有物體的時候,需要預測背景。
這個地方由於作者敘述的有些簡略,沒怎麼看懂;本文的方法在ILSVRC中獲得了19%,在賽後改進到24.3%;賽後主要是使用更長的訓練時間和利用“周圍環境”(每一個scale也同時使用低畫素scale作為輸入;介個有點不明白)。
六,總結
1,multi-scale sliding window方式,用來分類,定位,檢測
2,在一個卷積網路框架中,同時進行3個任務
本文還可以進一步改進,
1,在定位實驗總,沒有整個網路進行反向傳播訓練
2,用評價標準的IOU作為損失函式,來替換L2
3,交換bounding box的引數,幫助去掉結果的相關性(這個有點不明白)。
後來工作2被牛津大學作者做了出來。
一些困惑和理解
感覺卷積網路真的好強大,幹啥都行,而且還能相互間共享特徵;雖然分類,定位,和檢測的難度是遞增的,但是感覺分類是最基礎的,分類結果的好壞決定了後面兩個任務的好壞,因為圖片中物體分類準確了,才能進行定位和檢測;在分類階段調整網路部分並沒有過多的敘述原因,只是給出了最後的網路結構,通過暴力式的增加複雜度,提取更多資訊。
本文multi-scale測試的處理方式和SPP-net(下一篇博文)的方式有些不同,本文是通過multi-view的方式採用滑窗的方式產生多個數據結果,而Spp-net通過改變子取樣比例,來得到固定的特徵層輸出。感覺本文的滑窗方式更適合預測bounding box和detection;因為這種方式可以是物體和view很好的匹配,從而得到很好置信得分,但是還是感覺有些複雜,例如offset是否可以使用兩個,sliding window感覺可以像Alex-net那樣採用5-view的方式,在特徵圖中選取上下左右和中間5個view進行預測就可以了,因為pooling的特徵具有聚集性,感覺每個view會有很大的相似性。
圖中對熊的定位例項中,卷積網路在不同的scale上面會得到不同的分類結果,在聯合上一篇博文中兩位作者對平移,縮放和翻轉不變形的探討;卷積網路的優勢就是對於平移具有不變形,但是感覺對於平移和縮放的識別能力是有限的,對於大的物體能夠很好的識別,對於小的物體感覺網路有些乏力,這可能也就是為什作者在multi-scale時,從來都是放大而不是縮小;還有就是感覺和每個高層對應底層的感受野有關,例如才本文中一個layer-5的特徵啟用值,對應輸入層影象36*36的一個小區域,如果物體比36*36區域小,或者稍微大一些;感覺網路就會識別困難。感覺後面GoogLeNet,裡面的Inception模型,就和這個有關係,不同的filter和pooling可以對應不同的初始感受野(個人觀點)。
相關推薦
深度學習研究理解6:OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks
本文是紐約大學Yann LeCun團隊中Pierre Sermanet ,David Eigen和張翔等在13年撰寫的一篇論文,本文改進了Alex-net,並用影象縮放和滑窗方法在test資料集上測試網路;提出了一種影象定位的方法;最後通過一個卷積網路來同時進行分類,定位和
深度學習論文翻譯解析(十一):OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
論文標題:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 標題翻譯:OverFeat:使用卷積神經網路整合識別,定位和檢測 論文作者:Pierre Sermanet&nb
OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
從layer-5 pre-pool到layer-5 post-pool:這一步的實現是通過池化大小為(3,3)進行池化,然後△x=0、1、2,△y=0、1、2,這樣我們可以得到對於每一張特徵圖,我們都可以得到9幅池化結果圖。以上面表格中的sacle1為例,layer-5 pre-pool大小是17*17,經過
【OverFeat】《OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks》
ICLR-2014 全稱為「International Conference on Learning Representations」(國際學習表徵會議),由位列深度學習三大巨頭之二的 Yoshua Bengio 和 Yann LeCun 牽頭創辦。詳細介紹可
深度學習研究理解10:Very Deep Convolutional Networks for Large-Scale Image Recognition
本文是牛津大學 visual geometry group(VGG)Karen Simonyan 和Andrew Zisserman 於14年撰寫的論文,主要探討了深度對於網路的重要性;並建立了一個19層的深度網路獲得了很好的結果;在ILSVRC上定位第一,分類第二。 一:
深度學習論文筆記(六)--- FCN-2015年(Fully Convolutional Networks for Semantic Segmentation)
深度學習論文筆記(六)--- FCN 全連線網路 FullyConvolutional Networks for Semantic Segmentation Author:J Long , E Shelhamer, T Darrell Year: 2015 1、 導
深度學習論文翻譯解析(十五):Densely Connected Convolutional Networks
論文標題:Densely Connected Convolutional Networks 論文作者:Gao Huang Zhuang Liu Laurens van der Maaten Kilian Q. Weinberger 論文地址:https://arxiv.org/pdf/1608.0
吳恩達-深度學習-課程筆記-6: 深度學習的實用層面( Week 1 )
data 絕對值 initial 均值化 http 梯度下降法 ati lod 表示 1 訓練/驗證/測試集( Train/Dev/test sets ) 構建神經網絡的時候有些參數需要選擇,比如層數,單元數,學習率,激活函數。這些參數可以通過在驗證集上的表現好壞來進行選擇
深度學習深刻理解和應用--必看知識
3.1 講解 target 社區 github flow deep 卷積 work 1.深層學習為何要“Deep” 1.1 神經網絡:從數學和物理兩視角解釋,見:https://zhuanlan.zhihu.com/p/22888385 1.2 網絡加深
吳恩達第一門-神經網路和深度學習第二週6-10學習筆記
神經網路和深度學習第二週6-10學習筆記 6.更多導數的例子 在本節中,為上一節的導數學習提供更多的例子。在上一節中,我們複習了線性函式的求導方法,其導數值在各點中是相等的。本節以y=a^2這一二次函式為例,介紹了導數值在各點處發生變化時的求導方法。求導大家都會,y=x ^3的導數是
【電腦科學】【2017.11】【含原始碼】用於超光譜影象畫素分類的深度學習研究
本文為荷蘭代爾夫特理工大學(作者:I.A.F. Snuverink)的碩士論文,共128頁。 在超光譜(HS)成像中,每一個畫素都要捕獲波長光譜,這些光譜代表材料性質,即光譜特徵。因此,HS影象的分類是基於材料屬性的。本文介紹了一種在不同環境條件下的固定場景中進行HS影象畫素分類的
《TensorFlow:實戰Google深度學習框架》——6.3 卷積神經網路常用結構
1、卷積層 圖6-8顯示了卷積層神經網路結構中重要的部分:濾波器(filter)或者核心(kernel)。 過濾器可以將當前層神經網路上的一個子節點矩陣轉化為下一層神經網路上的一個單位節點矩陣 。 單位節點矩陣指的是一個長和寬都為1,但深度不限的節點矩陣 。 在一個卷積層巾,過濾器
《TensorFlow:實戰Google深度學習框架》——6.2 卷積神經網路簡介(卷積神經網路的基本網路結構及其與全連線神經網路的差異)
下圖為全連線神經網路與卷積神經網路的結構對比圖: 由上圖來分析兩者的差異: 全連線神經網路與卷積網路相同點 &nb
《TensorFlow:實戰Google深度學習框架》——6.1 影象識別中經典資料集介紹
1、CIFAR資料集 CIFAR是一個影響力很大的影象分類資料集,CIFAR資料集中的圖片為32*32的彩色圖片,由Alex Krizhevsky教授、Vinod Nair博士和Geoffrey Hinton教授整理的。 CIFAR是影象詞典專案(Visual Dictionar
《TensorFlow:實戰Google深度學習框架》——6.3 卷積神經網路常用結構(池化層)
池化層在兩個卷積層之間,可以有效的縮小矩陣的尺寸(也可以減小矩陣深度,但實踐中一般不會這樣使用),co。池從而減少最後全連線層中的引數。 池化層既可以加快計算速度也可以防止過度擬合問題的作用。 池化層也是通過一個類似過濾器結構完成的,計算方式有兩種: 最大池化層:採用最
深度學習——dropout理解
1.dropout解決的問題 深度神經網路的訓練是一件非常困難的事,涉及到很多因素,比如損失函式的非凸性導致的區域性最優值、計算過程中的數值穩定性、訓練過程中的過擬合等。其中,過擬合是很容易發生的現象,也是在訓練DNN中必須要解決的問題。 過擬合 我們先來講一下什麼
翻譯:開始閱讀深度學習研究論文:為什麼和如何做
Getting started with reading Deep Learning Research papers: The Why and the How 當你讀完那本書或者完成了關於深度學習的線上課程後,你如何繼續學習呢?你如何變得“自給自足”,這樣你就不需要依靠別人來打破這個領
深度學習理論基礎6-多層感知機
廢話不多說,人生甜短,讓我們立即開始多層感知機的學習吧。為了迴圈漸進的理解多層感知機,我們有必要再把閘電路拿出來把玩一番。 這些是閘電路的符號表示,我們馬上就用。你隨便記3秒鐘就好。 吼吼,你是不是在想,難道這就是異或門?沒錯哦。這就是。不信你可以捋一下。 是不是經過翻過來調
深度學習深理解(八)- 結構化機器學習專案
總結一下今天的學習過程 昨天由於裝雙系統,耽誤了一天,打斷這周暫時學習結束吳恩達老師的前三部分的課程(因為後期兩部分沒有開課) 幸運的是,今天學習比較努力 哈哈哈,將計劃兩天的課程今天一天學習完了 機器學習的策略: 收集更多的資料增加訓練集的多樣性增加使用梯度下降法的訓練
深度學習之理解神經網路的四個公式
在這篇文章裡面,我們探討了:可以使用偏導值利用梯度下降來求權重w和b,但是我們並沒有提,如何求代價函式的偏導,或者說如何對代價函式使用梯度下降。這時候就需要我們的backpropagation出馬了。 backpropagaton的歷史我就不詳談了(主要是懶)