
python requests爬蟲
阿新 • • 發佈:2018-10-31
1、介紹
requests是爬蟲的利器,可以設定代理ip,cookies,headers等多種反爬蟲手段,過濾資料笨的辦法可以使用正則,比較可靠穩定的辦法使用xpath,找了一個爬蟲騰訊招聘的code簡要說下
2、程式碼
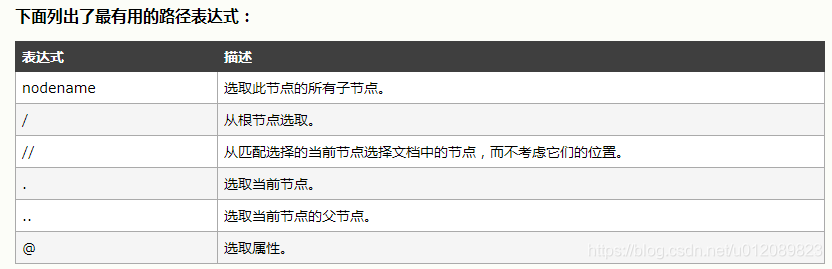
- 設定tr標籤的屬性值:tr[@class='c bottomline']
- td[1] 表示第一個td標籤
- .// : 表示選取當前節點開始匹配,直到匹配到符合條件的
# -*- coding: utf-8 -*- from lxml import etree import requests BASE_DOMAIN="http://hr.tencent.com/" HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' 'AppleWebKit/537.36 (KHTML, like Gecko)' ' Chrome/67.0.3396.99 Safari/537.36' } BASE_URL="https://hr.tencent.com/position.php?keywords=python&lid=0&tid=0&start=0" def parse_detail_page(url): position={} response=requests.get(url,headers=HEADERS) html=etree.HTML(response.text) work_name=html.xpath("//tr[@class='h']/td/text()")[0] work_place=html.xpath("//tr[@class='c bottomline']/td[1]/text()")[0] work_category=html.xpath("//tr[@class='c bottomline']/td[2]/text()")[0] work_lack_number=html.xpath("//tr[@class='c bottomline']/td[3]/text()")[0] more_infos=html.xpath("//ul[@class='squareli']") work_duty=more_infos[0].xpath(".//text()") work_require=more_infos[1].xpath(".//text()") position['work_name']=work_name position['work_place']=work_place position['work_category']=work_category position['work_lack_number']=work_lack_number position['work_duty']=work_duty position['work_require']=work_require return position def get_detail_urls(url): response=requests.get(url=BASE_URL,headers=HEADERS) text=response.text html=etree.HTML(text) links=html.xpath("//tr[@class='even']//a/@href") links=map(lambda url:BASE_DOMAIN+url,links) return links def spider(): base_url="https://hr.tencent.com/position.php?keywords=python&lid=0&tid=0&start={}#a" positions=[] for x in range(0, 4): #43 x*=10 url=base_url.format(x) detail_urls=get_detail_urls(url) for detail_url in detail_urls: position=parse_detail_page(detail_url) positions.append(position) with open('tecentRecruit.txt','a',encoding='utf-8') as f: for (key,value) in position.items(): if(key=='work_duty'): str='work_duty :{}' f.write(str.format(value)) f.write('\n') elif(key=='work_require'): str="work_require :{}" f.write(str.format(value)) f.write('\n') else: f.write(key+":"+value) f.write('\n') f.write('\n'*3) if __name__ == '__main__': spider()