機器學習系列之交叉驗證、網格搜尋
第一部分:交叉驗證
機器學習建立和驗證模型,常用的方法之一就是交叉驗證。在機器學習過程中,往往資料集是有限的,而且可能具有一定的侷限性。如何最大化的利用資料集去訓練、驗證、測試模型,常用的方法就是交叉驗證。交叉驗證,就是重複的使用資料,對樣本資料進行劃分為多組不同的訓練集和測試集(訓練集訓練模型,測試集評估模型)。
交叉驗證一般使用在資料不是很充足情況。一般問題,如果資料樣本量小於一萬條,就會採用交叉驗證優化模型。資料樣本量大於一萬條,就隨機把資料分成三份(訓練集、驗證集、測試集)(來自博主劉建平)
交叉驗證主要分為以下幾種:
第一種是簡單資料劃分(train_test_split)
from sklearn.model_selection import train_test_split第二種是簡單交叉驗證(Standard Cross Validation、S-Folder Cross Validation)。針對上述問題,所以提出了多次train_test_split劃分。每次劃分時,在不同的資料集上進行訓練、測試評估,從而得出一個評價結果;如果是5折交叉驗證,意思就是在原始資料集上,進行5次劃分,每次劃分進行一次訓練、評估,最後得到5次劃分後的評估結果,一般在這幾次評估結果上取平均得到最後的 評分。k-fold cross-validation ,其中,k一般取5或10。
from sklearn.model_selection import cross_val_score
logreg = LogisticRegression()
scores = cross_val_score(logreg,cancer.data, cancer.target,CV=5)
第三種是分層交叉驗證(Stratified k-fold cross validation)。分層的意思是說在每一折中都保持著原始資料中各個類別的比例關係,比如說:原始資料有3類,比例為1:2:1,採用3折分層交叉驗證,那麼劃分的3折中,每一折中的資料類別保持著1:2:1的比例,這樣的驗證結果更加可信。可以把KFold引數代入CV中。
from sklearn.model_selection import StratifiedKFold,cross_val_score
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
strKFold = StratifiedKFold(n_splits=3,shuffle=False,random_state=0)
scores = cross_val_score(logreg,iris.data,iris.target,cv=strKFold)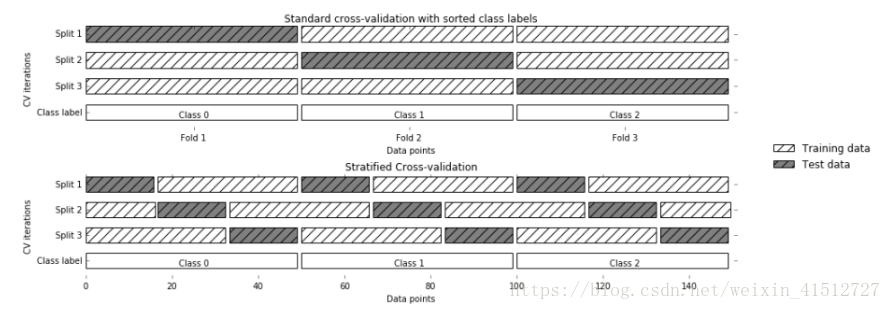
第四種是留一法(Leave-one-out Cross-validation)。如果樣本容量為n,則k=n,進行n折交叉驗證,每次留下一個樣本進行驗證。主要針對小樣本資料。
from sklearn.model_selection import LeaveOneOut,cross_val_score
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
loout = LeaveOneOut()
scores = cross_val_score(logreg,iris.data,iris.target,cv=loout)Shuffle-split cross-validation。可以控制劃分迭代次數、每次劃分時測試集和訓練集的比例(可以存在既不在訓練集也不再測試集的情況)

參考:https://www.cnblogs.com/ysugyl/p/8707887.html
http://www.cnblogs.com/pinard/p/5992719.html劉博主,很贊!
第二部分:網格搜尋
Grid Search 是一種窮舉的調參方法。通過迴圈遍歷的方式,把每一種候選的引數組合,全部除錯一遍。最後表現效果最好的引數就是最終的結果。

巢狀迴圈方式實現:(每次調參時,資料集要保持一致性)。為了避免test data既用於檢驗模型引數,又用於測試模型好壞,會提高模型結果的評分。可以將資料集分成三部分:train/val/test,分別對應訓練、驗證、測試。

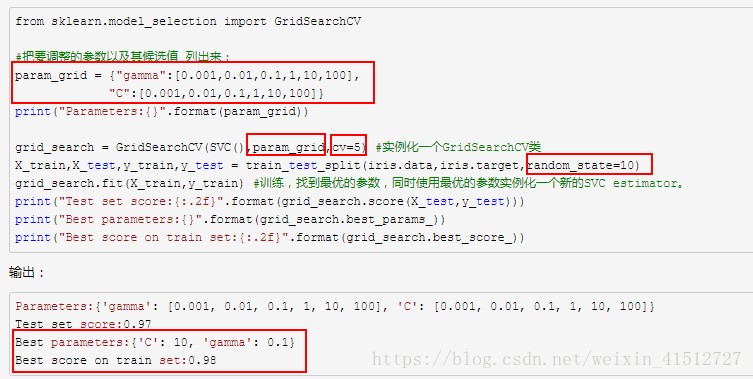
第三部分:交叉驗證與網格搜尋結合應用
交叉驗證經常和網格搜尋結合應用(grid search with cross validation)。sklearn中有個類GridSearchCV, 實現了fit/predict/score等方法。