
【NMS】Non Maximum Suppression非極大值抑制
非極大值抑制(Non-Maximum Suppression,NMS)
概述
非極大值抑制(Non-Maximum Suppression,NMS),顧名思義就是抑制不是極大值的元素,可以理解為區域性最大搜索。這個區域性代表的是一個鄰域,鄰域有兩個引數可變,一是鄰域的維數,二是鄰域的大小。這裡不討論通用的NMS演算法(參考論文《
Efficient Non-Maximum Suppression》對1維和2維資料的NMS實現),而是用於目標檢測中提取分數最高的視窗的。例如在行人檢測中,滑動視窗經提取特徵,經分類器分類識別後,每個視窗都會得到一個分數。但是滑動視窗會導致很多視窗與其他視窗存在包含或者大部分交叉的情況。這時就需要用到NMS來選取那些鄰域裡分數最高(是行人的概率最大),並且抑制那些分數低的視窗。
NMS在計算機視覺領域有著非常重要的應用,如視訊目標跟蹤、資料探勘、3D重建、目標識別以及紋理分析等。
NMS 在目標檢測中的應用
人臉檢測框重疊例子

face box
我們的目的就是要去除冗餘的檢測框,保留最好的一個.
有多種方式可以解決這個問題,Triggs et al. 建議使用Mean-Shift 演算法,利用bbox的座標和當前圖片尺度的對數來檢測bbox的多種模式.但效果可能並不如使用強分類器結合NMS的效果好.
目標檢測 pipline
產生proposal後使用分類網路給出每個框的每類置信度,使用迴歸網路修正位置,最終應用NMS.
NMS 原理
對於Bounding Box的列表B及其對應的置信度S,採用下面的計算方式.選擇具有最大score的檢測框M,將其從B集合中移除並加入到最終的檢測結果D中.通常將B中剩餘檢測框中與M的IoU大於閾值Nt的框從B中移除.重複這個過程,直到B為空.
重疊率(重疊區域面積比例IOU)閾值
常用的閾值是 0.3 ~ 0.5.
其中用到排序,可以按照右下角的座標排序或者面積排序,也可以是通過SVM等分類器得到的得分或概率,R-CNN中就是按得分進行的排序.

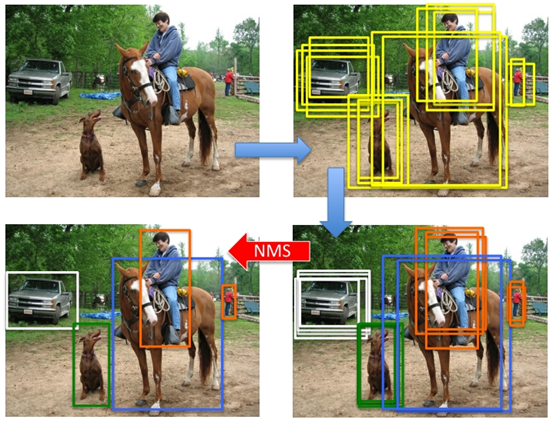
就像上面的圖片一樣,定位一個車輛,最後演算法就找出了一堆的方框,我們需要判別哪些矩形框是沒用的。非極大值抑制的方法是:先假設有6個矩形框,根據分類器的類別分類概率做排序,假設從小到大屬於車輛的概率 分別為A、B、C、D、E、F。
(1)從最大概率矩形框F開始,分別判斷A~E與F的重疊度IOU是否大於某個設定的閾值;
(2)假設B、D與F的重疊度超過閾值,那麼就扔掉B、D;並標記第一個矩形框F,是我們保留下來的。
(3)從剩下的矩形框A、C、E中,選擇概率最大的E,然後判斷E與A、C的重疊度,重疊度大於一定的閾值,那麼就扔掉;並標記E是我們保留下來的第二個矩形框。
就這樣一直重複,找到所有被保留下來的矩形框。
程式碼示例
在R-CNN中使用了NMS來確定最終的bbox,其對每個候選框送入分類器,根據分類器的類別分類概率做排序(論文中稱為greedy-NMS).但其實也可以在分類之前運用簡單版本的NMS來去除一些框.
python實現的單類別nms:py_cpu_nms.py.
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
#x1、y1、x2、y2、以及score賦值
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
#每一個檢測框的面積
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#按照score置信度降序排序
order = scores.argsort()[::-1]
keep = [] #保留的結果框集合
while order.size > 0:
i = order[0]
keep.append(i) #保留該類剩餘box中得分最高的一個
#得到相交區域,左上及右下
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#計算相交的面積,不重疊時面積為0
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#計算IoU:重疊面積 /(面積1+面積2-重疊面積)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#保留IoU小於閾值的box
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1] #因為ovr陣列的長度比order陣列少一個,所以這裡要將所有下標後移一位
return keepFaster R-CNN的MATLAB實現與python版實現一致,程式碼在這裡:nms.m.另外,nms_multiclass.m是多類別nms,加了一層for迴圈對每類進行nms而已.
NMS loss
值的注意的是對多類別檢測任務,如果對每類分別進行NMS,那麼當檢測結果中包含兩個被分到不同類別的目標且其IoU較大時,會得到不可接受的結果。如下圖所示:

一種改進方式便是在損失函式中加入一部分NMS損失。NMS損失可以定義為與分類損失相同:Lnms=Lcls(p,u)=−log⁡pu” role=”presentation” style=”position: relative;”>Lnms=Lcls(p,u)=−logpuLnms=Lcls(p,u)=−logpu,即真實列別u對應的log損失,p是C個類別的預測概率。實際相當於增加分類誤差。
參考論文《Rotated Region Based CNN for Ship Detection》(IEEE2017會議論文)的Multi-task for NMS部分。
Soft-NMS
上述NMS演算法的一個主要問題是當兩個ground truth的目標的確重疊度很高時,NMS會將具有較低置信度的框去掉(置信度改成0),參見下圖所示.

論文:《Improving Object Detection With One Line of Code》
改進之處:

改進方法在於將置信度改為IoU的函式:f(IoU),具有較低的值而不至於從排序列表中刪去.
線性函式
si={