
storm(二)訊息的可靠處理
storm 通過 trident保證了對訊息提供不同的級別。beast effort,at least once, exactly once。
一個tuple 從spout流出,可能會導致大量的tuple被建立。如下面的單詞統計
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt("split", new SplitSentence(), 10)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 20)
.fieldsGrouping("split", new Fields("word"));storm任務會從資料來源(kestrel queue)讀取一個完整的英文句子,將句子按照空格分解為一個個的單詞,然後再發送之前計算的單詞的數量,從spout中流出的一個tuple會觸發建立許多的tuples;一個tuple對應句子中的一個單詞,一個tuple對應每個單詞的count。這些tuple構成一個樹狀結構,如下圖所示:
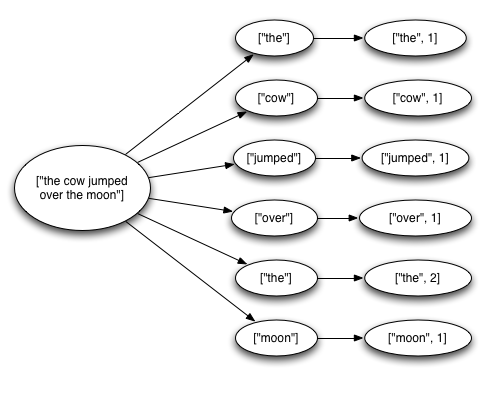
storm怎麼會認為一個從spout中傳送出來的訊息被完全處理呢?
當tuple tree 不在生長
tree中的任何訊息被標記為“已處理”
當一個tuple tree 沒有在特定的時間內完全處理,tuple就會被認為是失敗的 。可以指定在topology上使用Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS來配置這個超時時間,並且預設為30秒。
訊息的生命週期
如果訊息被完整處理或未能完全處理,會發生什麼?我們先看下spout的生命週期
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
首先storm 請求一個spout中的tuple,使用spout裡面的nextTuple方法。 spout使用SpoutOutputCollector提供的open方法,傳送tuple輸出到outputstreams的其中一個。當傳送tuple的時候,spout會提供一個“message id”,用於以後標識tuple。例如,我們從kestrel佇列中讀取訊息,Spout會將kestrel 佇列為這個訊息設定的ID作為此訊息的message ID。 向SpoutOutputCollector中傳送訊息格式如下:
_collector.emit(new Values("field1", "field2", 3) , msgId);
接下來,tuple會背送到消費的bolts中,storm開始監控建立 the tree of message.如果storm檢測到tuple被完全處理,Spout 上根據message id 呼叫 ack 方法.同樣的,如果處理 tuple超時了,Storm會呼叫在 Spout 上呼叫 fail 方法。一個訊息只會由傳送它的那個spout任務來呼叫ack或fail。如果系統中某個spout由多個任務執行,訊息也只會由建立它的spout任務來應答(ack或fail),絕不會由其他的spout的任務來應答。
為了使用Storm提供的可靠處理特性,我們需要做兩件事情:
- 無論何時在tuple tree中建立了一個新的節點,我們需要明確的通知Storm;
- 當處理完一個單獨的訊息時,我們需要告訴Storm 這棵tuple tree的變化狀態。
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
通過指定輸入 tuple 作為emit 的第一個引數,每一個word tuple 就會被 錨定(anchored).由於 word tuple 被 錨定(anchor),如果 word tuple 下游處理失敗,tuple tree 的根節點會重新處理.相比之下,我們看一下 word tuple像下面這樣傳送.
_collector.emit(new Values(word));
這種方式傳送 word tuple 不會被錨定(unanchored). 如果tuple在處理下游的時候失敗,根節點的 tuple不會重新處理.根據你的 topology(拓撲)需要來保證容錯保證,有時候傳送一個 unanchored tuple 也比較適合.
輸出的tuple可以 錨定(anchor) 多個input tuple,當join和聚合的時候,這是比較有用的.一個 multi-anchored 的tuple處理失敗後,多個tuple都會被重新處理.通過指定一系列 tuples,而不是單個tuple來完成 Multi-anchoring.例如:
List<Tuple> anchors = new ArrayList<Tuple>(); anchors.add(tuple1); anchors.add(tuple2); _collector.emit(anchors, new Values(1, 2, 3));
Multi-anchoring 會新增 output tuple 到 multiple tuple trees.這就可能會破壞樹形結構,建立了tuple DAGs,像這樣:
List<Tuple> anchors = new ArrayList<Tuple>(); anchors.add(tuple1); anchors.add(tuple2); _collector.emit(anchors, new Values(1, 2, 3));
Multi-anchoring 會新增 output tuple 到 multiple tuple trees.這就可能會破壞樹形結構,建立了tuple DAGs(有向無環圖),像這樣:
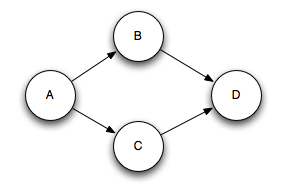
Storm 的實現適用於DAG和樹(pre-release 只適用於trees,稱為“tuple tree”)
錨定表明瞭如何將一個訊息加入到指定的tuple tree中,高可靠處理API的接下來將向您描述當處理完tuple tree中一個單獨的訊息時我們該做些什麼。在OutputCollector上使用ack和fail方法的時候來完成。回顧SplitSentence例子,可以看到所有的Word tuple傳送出去之後,input tuple會背ack。 你可以使用OutputCollector 的
fail 方法,立即設定 tuple tree的根節點spout tuple為失敗狀態.例如,你的應用可能資料庫異常,需要顯式的 fail input tuple。通過顯式的failing,spout tuple 可以比等待tuple超時速度更快.
每個被處理的訊息必須表明成功或失敗(acked 或者failed)。Storm是使用記憶體來跟蹤每個訊息的處理情況的,如果被處理的訊息沒有應答的話,遲早記憶體會被耗盡!
很多bolt遵循特定的處理流程: 讀取一個訊息、傳送它派生出來的子訊息、在execute結尾處應答此訊息。bolts 有過濾或者一些簡單的功能.Storm有一個介面叫做BasicBolt,可以封裝這些模式.SplitSentence示例可以寫成BasicBolt,如下所示:
public class SplitSentence extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
之前的程式碼是
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
該實現比以前的實現更簡單,語義上相同。傳送到
BasicOutputCollector 的 tuple 將自動 錨定(anchor) 到輸入訊息,並且,當execute執行完畢的時候,會自動應答輸入訊息。很多情況下,一個訊息需要延遲應答,例如聚合或者是join。只有根據一組輸入訊息得到一個結果之後,才回應答之前所有的輸入訊息。並且聚合和join大部分時候對輸出訊息都是多重錨定。然而,這些特性不是IBasicBolt所能處理的
高效的實現tuple tree
storm系統中有一組叫做“acker”的特殊的任務,他們負責跟蹤DAG(有向無環圖)中的每個訊息。每當發現一個DAG被完全處理,它就向建立這個跟訊息的spout任務傳送一個資訊。拓撲中acker任務的並行度可以通過配置引數Config.TOPOLOGY_ACKERS來設定。預設的acker任務並行度為1.當系統中有大量的訊息時,應該適當提高acker任務的併發度。
為了理解Storm可靠性處理機制,我們從研究一個訊息的生命週期和tuple tree的管理入手。當一個訊息被建立的時候(無論是在spout還是bolt中),系統都為該訊息分配一個64bit的隨機值作為id。這些隨機的id 是acker用來跟蹤由spout訊息派生出來的tuple tree的。每個訊息都知道它所在的tuple tree對應的根訊息的id。每當bolt新生成一個訊息,對應tuple tree中的根訊息的messageID就拷貝到這個訊息中。當這個訊息被應答的時候,它就把關於tuple tree變化的資訊傳送給跟蹤這棵樹的acker。例如,他會告訴acker;本訊息已經處理完畢,但是我派生出了一些新的訊息幫忙跟蹤一下。
舉個例子,假設訊息D和E是由訊息C派生出來的,這裡演示了訊息C被應答時,tuple tree是如何變化的。Storm 跟蹤 tuple trees 有一些細節.如前面所述,你可以在 topology中定義任意數量的 acker 任務。這導致了以下問題:當一個元組在 topology 中被 acked後,它如何知道是哪個 acker 任務傳送的該訊息?
系統使用一種雜湊演算法來根據spout訊息的messageID來確定由哪個acker跟蹤此訊息派生出來的tuple tree。因為每個訊息都知道與之對應的根訊息的messageID,因此它知道應該與哪個acker通訊。當spout傳送一個訊息的時候,它就通知對應的acker一個新的根訊息就產生了,這時acker就會建立一個新的tuple tree。當acker發現這顆樹被完全處理之後,它就會通知對應的spout任務。
tuple是如何倍跟蹤的? 系統中有成千上萬的訊息,如果為每個spout傳送的訊息都構建一棵樹的話,很快記憶體就會被耗盡。所以,必須採用不同的策略來跟蹤每個訊息。由於使用了新的跟蹤演算法,storm只需要固定的記憶體(大約20位元組)就可以跟蹤一棵樹。這個演算法是storm正確執行的核心。
acker任務儲存了spout訊息id到一對值的對映。第一個值就是spout的任務id,通過這個id,acker就知道訊息處理完成時該通知那個spout任務。第二個值是一個64bit的數字,我們稱之為ack val,它是樹中所有訊息的隨機id的異或結果。ack val 表示了整棵樹的狀態,無論這棵樹多大,只需要這個固定大小的水準就可以跟蹤整棵樹
假設你每秒鐘傳送一萬個訊息,從概率上說,至少需要50,000,000年才會有機會發生一次錯誤。即使如 此,也只有在這個訊息確實處理失敗的情況下才會有資料的丟失!
選擇合適的級別
acker任務是輕量級的,所以在拓撲中並不需要太多的acker存在,可以通過storm UI來觀察acker任務的吞吐量,如果看上去吞吐量不夠的話,說明需要新增一些額外的acker。
如果你並不要求每個訊息必須被處理(允許在處理過程中丟失一些訊息),那麼可以關閉訊息的可靠處理機制,從而可以獲取較好的效能。關閉訊息的可靠 處理機制意味著系統中的訊息數會減半(每個訊息不需要應答了)。另外,關閉訊息的可靠處理可以減少訊息的大小(不需要每個tuple記錄它的根id了), 從而節省頻寬。
有三種方法可以關閉訊息的可靠處理機制:
- 將引數Config.TOPOLOGY_ACKERS設定為0,通過此方法,當spout傳送一個訊息的時候,它的ack方法將立刻被呼叫。
- spout傳送一個訊息時,不指定此訊息的messageID。當需要關閉特定訊息可靠性的時候,可以使用此方法
- 如果不在意某個訊息派生出來的 子孫訊息的可靠性,則此訊息派生出來的子訊息在傳送時不要做錨定,即在emit方法中不指定輸入訊息。因為這些子孫訊息沒有被錨定在任何tuple tree中,因此他們的失敗不會引起任何spout重新發送訊息。
叢集的各級容錯
1. 任務級失敗
因為bolt任務crash引起的訊息未被應答。此時,acker中所有與此bolt任務關聯的訊息都會因為超時而失敗,對應spout的fail方法將被呼叫。
- acker任務失敗。如果acker任務本身失敗了,它在失敗之前持有的所有訊息都將會因為超時而失敗。Spout的fail方法將被呼叫。
- Spout任務失敗。這種情況下,Spout任務對接的外部裝置(如MQ)負責訊息的完整性。例如當客戶端異常的情況下,kestrel佇列會將處於pending狀態的所有的訊息重新放回到佇列中。
2. 任務槽(slot)故障
- worker失敗。每個worker中包含數個bolt(或spout)任務。supervisor負責監控這些任務,當我讓客人失敗後,supervisor負責監控這些任務,當worker失敗後,supervisor會嘗試在本機重啟它。
- supervisor失敗。supervisor是無狀態的,因此supervisor的失敗不會影響當前正在執行的任務,只要及時的將它重新啟動即可。supervisor不是自舉的,需要外部監控來及時重啟。
- nimbus失敗。nimbus是無狀態的,因此nimbus的失敗不會影響當前正在執行的任務(nimbus失敗時,無法提交新的任務),只要及時的將它重新啟動即可。nimbus不是自舉的,需要外部監控來及時重啟。
3. 叢集節點(機器)故障
- storm叢集中的節點故障。此時nimbus會將此機器上機器上所有正在執行的任務轉移到其他可用的機器上執行
- zookeeper叢集中的節點故障。zookeeper保證少於半數的機器宕機仍可正常執行,及時修復機器故障即可。
藉助tuple tree,storm可以通過資料的應答機制來保證資料不丟失。
storm叢集中除nimbus外,沒有單點存在,人和街店都可以出故障而保證資料不會丟失。nimbus被設計為無狀態的,只要可以及時重啟,就不會影響正在執行的任務