
006-深度學習與NLP簡單應用
Auto-Encoder

如果原始圖片輸入後經過神經網路壓縮成中間狀態(編碼過程Encoder),再由中間狀態解碼出的圖片與原始輸入差別很小(D解碼過程ecoder),那麼這個中間狀態的東西,就可以用來表示原始的輸入。

原先打算用AE來做神經網路中的W,但是發現效果不好,然後神經網路使用batch 的方法來平滑損失函式曲線,然後使用神經網路的“跳層”方法優化神經網路。
所以AE用處最多的就是降維。
有一個問題,農場主假設,如果一群雞每天10點餵食,那麼雞中比較聰明的雞就會認為每天10點鐘有食物是一種自然規律,這個雞認為的這種自然規律在機器學習中叫做區域性最優解,也就是過擬合。
同理,人類在認知世界的過程中,無法開啟上帝之眼,無法跳出三維而完全的認識三維世界。

AE實現過程:
from keras.layers import Input, Dense
from keras.models import Model
from sklearn.cluster import KMeans
class ASCIIAutoencoder():
"""基於字元的Autoencoder."""
def __init__(self, sen_len = 512, encoding_dim = 32, epoch = 50, val_ratio = 0.3):
"""
Init.
:param sen_len: 把sentences pad成相同的⻓長度
:param encoding_dim: 壓縮後的維度dim
:param epoch: 要跑多少epoch
:param kmeanmodel: 簡單的KNN clustering模型
"""
self.sen_len = sen_len
self.encoding_dim = encoding_dim
self.autoencoder = None
self.encoder = None
self.kmeanmodel = KMeans(n_clusters = 2)
self.epoch = epoch
def fit(self, x):
"""
模型構建。
:param x: input text
"""
# 把所有的trainset都搞成同⼀一個size,並把每⼀一個字元都換成ascii碼
x_train = self.preprocess(x, length = self.sen_len)
# 然後給input預留留好位置
input_text = Input(shape = (self.sen_len,))
# "encoded" 每⼀一經過⼀一層,都被重新整理成⼩小⼀一點的“壓縮後表示式”
encoded = Dense(1024, activation = 'tanh')(input_text)
encoded = Dense(512, activation = 'tanh')(encoded)
encoded = Dense(128, activation = 'tanh')(encoded)
encoded = Dense(self.encoding_dim, activation = 'tanh')(encoded)
# "decoded" 就是把剛剛壓縮完的東⻄西,給反過來還原成input_text
decoded = Dense(128, activation = 'tanh')(encoded)
decoded = Dense(512, activation = 'tanh')(decoded)
decoded = Dense(1024, activation = 'tanh')(decoded)
decoded = Dense(self.sen_len, activation = 'sigmoid')(decoded)
# 整個從⼤大到⼩小再到⼤大的model,叫 autoencoder
self.autoencoder = Model(input = input_text, output = decoded)
# 那麼 只從⼤大到⼩小(也就是⼀一半的model)就叫 encoder
self.encoder = Model(input = input_text, output = encoded)
# 同理理,我們接下來搞⼀一個decoder出來,也就是從⼩小到⼤大的model
# 來,首先encoded的input size給預留留好
encoded_input = Input(shape = (1024,))
# autoencoder的最後⼀一層,就應該是decoder的第⼀一層
decoder_layer = self.autoencoder.layers[-1]
# 然後我們從頭到尾連起來,就是⼀一個decoder了了!
decoder = Model(input = encoded_input, output = decoder_layer(encoded_input))
# compile
self.autoencoder.compile(optimizer = 'adam', loss = 'mse')
# 跑起來
self.autoencoder.fit(x_train, x_train,
nb_epoch = self.epoch,
batch_size = 1000,
shuffle = True,
)
# 這⼀一部分是⾃自⼰己拿⾃自⼰己train⼀一下KNN,⼀一件簡單的基於距離的分類器器
x_train = self.encoder.predict(x_train)
self.kmeanmodel.fit(x_train)
def predict(self, x):
"""
做預測。
:param x: input text
:return: predictions
"""
# 同理理,第⼀一步 把來的 都給搞成ASCII化,並且⻓長度相同
x_test = self.preprocess(x, length = self.sen_len)
# 然後⽤用encoder把test集給壓縮
x_test = self.encoder.predict(x_test)
# KNN給分類出來
preds = self.kmeanmodel.predict(x_test)
return preds
def preprocess(self, s_list, length = 256):
...
CNN4Text
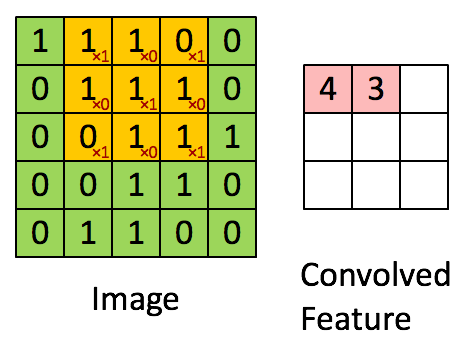

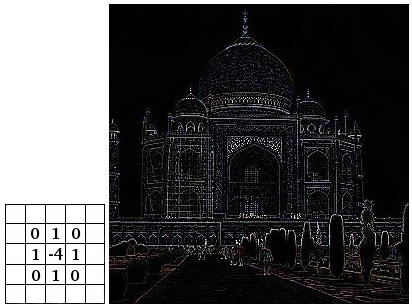
如何遷移到文書處理理?
1. 把文字表示成圖片

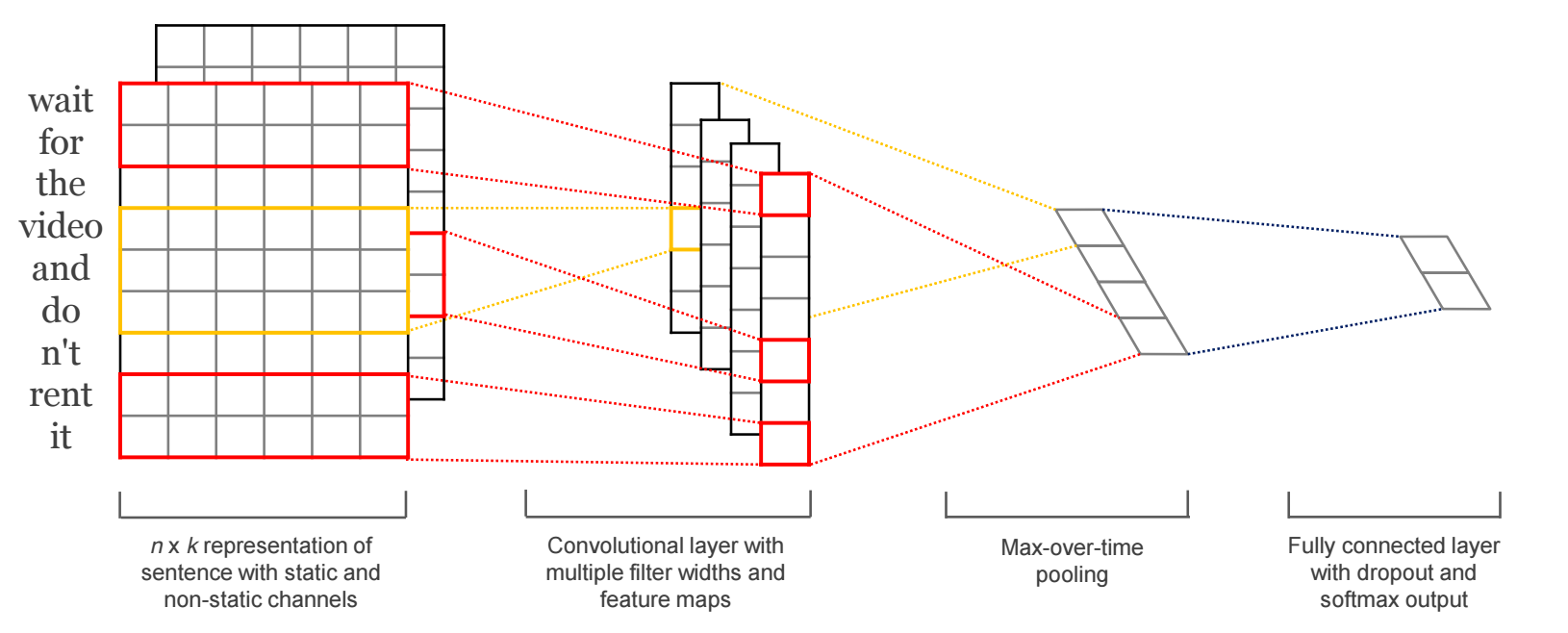
也可以把句子做成一維的:

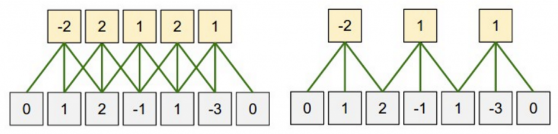
CNN假設:

RNN假設:

邊界處理理:
Narrow vs Wide
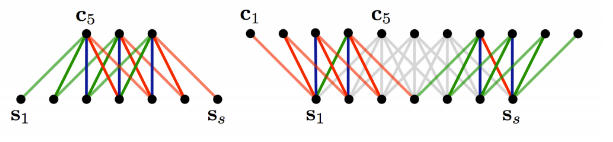
Stride size:
步伐大小
# 有兩種⽅方法可以做CNN for text
# 每種⽅方法⾥裡里⾯面,也有各種不不同的玩法思路路
# 效果其實基本都差不不多,
# 我這⾥裡里講2種最普遍的:
# 1. ⼀一維的vector [...] + ⼀一維的filter [...]
# 這種⽅方法有⼀一定的資訊損失(因為你average了了向量量),但是速度快,效果也沒太差。
# 2. 通過w2v或其他⽅方法,做成⼆二維matrix,當做圖⽚片來做。
# 這是⽐比較“講道理理”的解決⽅方案,但是就是慢。。。放AWS上太燒錢了了。。。
# 1. 1D CNN for Text
# ⼀一個IMDB電影評論的例例⼦子
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Embedding
from keras.layers import Convolution1D, MaxPooling1D
from keras.datasets import imdb
# set parameters:
max_features = 5000
maxlen = 400
batch_size = 32
embedding_dims = 50
nb_filter = 250
filter_length = 3
hidden_dims = 250
nb_epoch = 2
# ⾃自帶的資料集,load IMDB data
(X_train, y_train), (X_test, y_test) = imdb.load_data(nb_words = max_features)
# 這個資料集是已經搞好了了的BoW,⻓長這樣:
# [123, 2, 0, 45, 32, 1212, 344, 4, ... ]
# 簡單的把他們搞成相同⻓長度,不不夠的補0,太多的砍掉
X_train = sequence.pad_sequences(X_train, maxlen = maxlen)
X_test = sequence.pad_sequences(X_test, maxlen = maxlen)
# 這⾥裡里我們可以換成word2vec的vector,他們就是天然的相同⻓長度了了
# 留留個作業,⼤大家可以試試
# 初始化我們的sequential model (指的是線性排列列的layer)
model = Sequential()
# 亮點來了了,這⾥裡里你需要⼀一個Embedding Layer來把你的input word indexes
# 變成tensor vectors: ⽐比如 如果dim是3, 那麼:
# [[2],[123], ...] --> [[0.1, 0.4, 0.21], [0.2, 0.4, 0.13], ... ]
# 其實很像word2vec的結果,只不不過這個Embedding沒有什什麼太⼤大意義,只是向量量化了了input的int
model.add(Embedding(max_features,
embedding_dims,
input_length = maxlen,
dropout = 0.2))
# 這⼀一步對於直接⽤用BoW(⽐比如這個IMDB的資料集)很⽅方便便,但是對我們⾃自⼰己的word vector,
# 就不不友好了了,可以選擇跳過它
# 現在可以新增⼀一個Conv layer了了
model.add(Convolution1D(nb_filter = nb_filter, filter_length = filter_length, border_mode = 'valid',
activation = 'relu', subsample_length = 1))
# 後⾯面跟⼀一個MaxPooling
model.add(MaxPooling1D(pool_length = model.output_shape[1]))
# Pool出來的結果 就是類似於⼀一堆的⼩小vec
# 把他們粗暴暴的flatten⼀一下(就是橫著 連成⼀一起)
model.add(Flatten())
# 接下來就是簡單的MLP了了
# 在Keras⾥裡里,普通的layer⽤用Dense表示
model.add(Dense(hidden_dims))
model.add(Dropout(0.2))
model.add(Activation('relu'))
# 最終層
model.add(Dense(1))
model.add(Activation('sigmoid'))
# 如果⾯面對的是時間序列列的話,
# 這⾥裡里也是可以把layers都換成LSTM
# compile
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
# 跑起來
model.fit(X_train, y_train,
batch_size = batch_size,
nb_epoch = nb_epoch,
validation_data = (X_test, y_test))
# 這⾥裡里有個fault啊,不不可以拿testset做validation的
# 這只是簡單的做個示例例,為了了跑起來⽅方便便
# 2. 2D CNN
# 我們的input 應該是⼀一個list of M*N matrixs
# 但是注意⼀一下,我們需要稍微reshape⼀一下,把每個matrix⽤用⼀一個⼀一維的[]包起來
# 這就等於 我們把input變成 list of lists, 每個list包含⼀一個M*N Matrix
x_train = X_train.reshape(X_train.shape[0], 1,
X_train.shape[1], X_train.shape[2])
# cast⼀一下type,以防Numpy衝突
x_train = x_train.astype('float32')
# 接著,還是⼀一樣:
model = Sequential()
# n_filter, ⼀一共⼏幾個filter
# n_conv,每個filter的size
model.add(Convolution2D(n_filter, n_conv, n_conv,
border_mode = border_mode,
input_shape = (1, x_axis,
y_axis)))
model.add(Activation('relu'))
model.add(Convolution2D(n_filter, n_conv, n_conv))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size = (n_pool, n_pool)))
model.add(Dropout(0.25))
model.add(Flatten())
案例
從每日新聞中預測金融市場變化
資料獲取
/r/worldnews
DJIA(道瓊斯指數)

RedditNews(經濟新聞)

Combine
Date, Text, Label

W2V模型的Pretrain:
1.GoogleNews.bin (https://code.google.com/archive/p/word2vec/)
2.RedditComments (https://www.reddit.com/r/datasets/comments/3mg812/full_reddit_submission_corpus_now_available_2006/)
3. 用我提供的dataset里的新聞文字直接當場train
4. 我預先訓練好的 reddit w2v model
ML
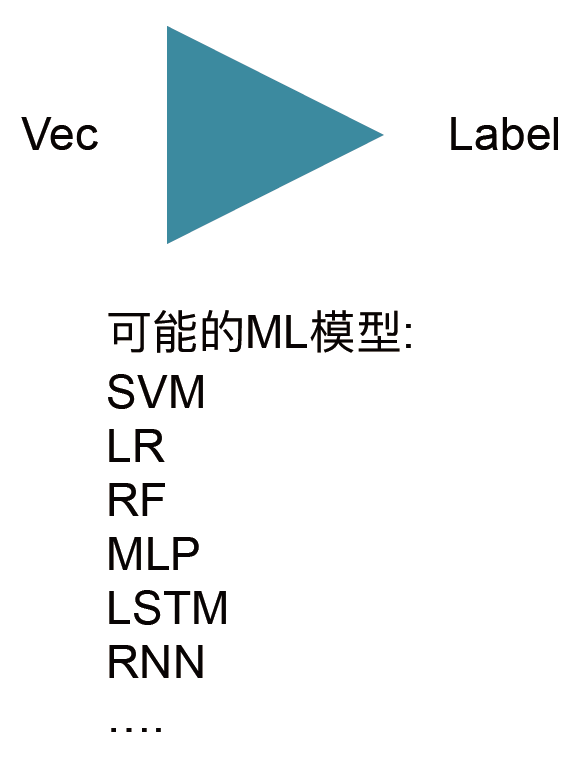
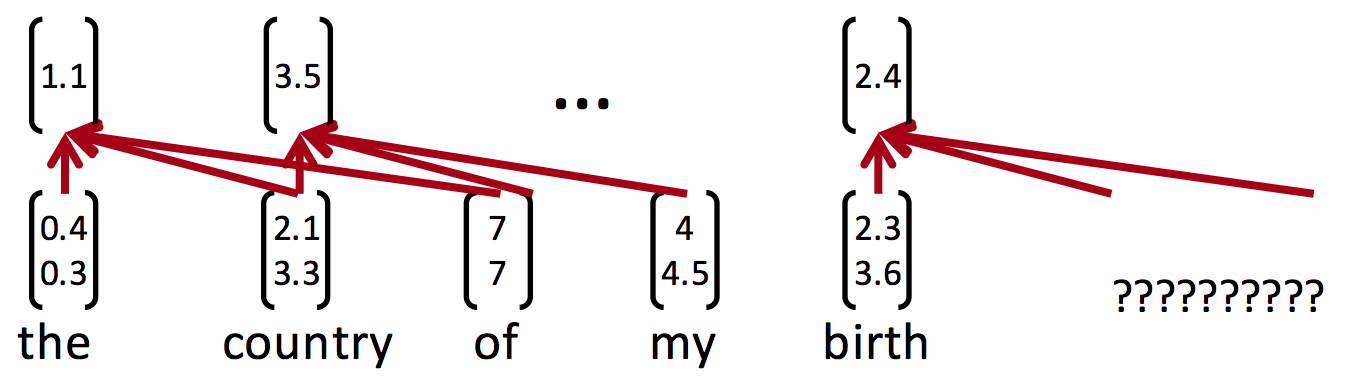
普通神經網路:
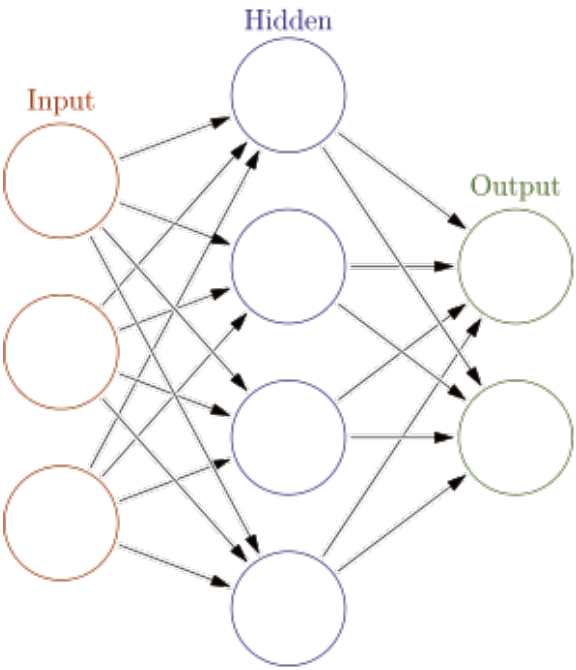
RNN:
RNN的目的是讓有sequential關係的資訊得到考慮。
什麼是sequential關係?
就是資訊在時間上的前後關係。
相比於普通神經網路:
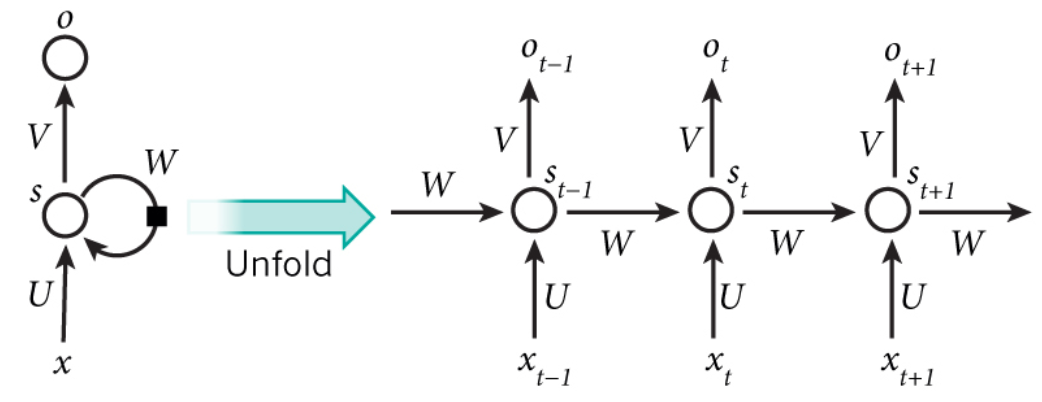
每個時間點中的S計算
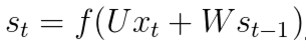
這個神經元最終的輸出,
基於最後一個S
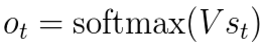
簡單來說,對於t=5來說,其實就相當於把一個神經元拉伸成五個
換句句話說,S就是我們所說的記憶(因為把t從1-5的資訊都記錄下來了)
由前文可見,RNN可以帶上記憶。
假設,一個『生成下一個單詞』的例子:
『這頓飯真好』——>『吃』
很明顯,我們只要前5個字就能猜到下一個字是啥了了
However,
如果我問你,『穿山甲說了什麼?』
你能回答嘛?
(credit to 暴走漫畫)
LSTM
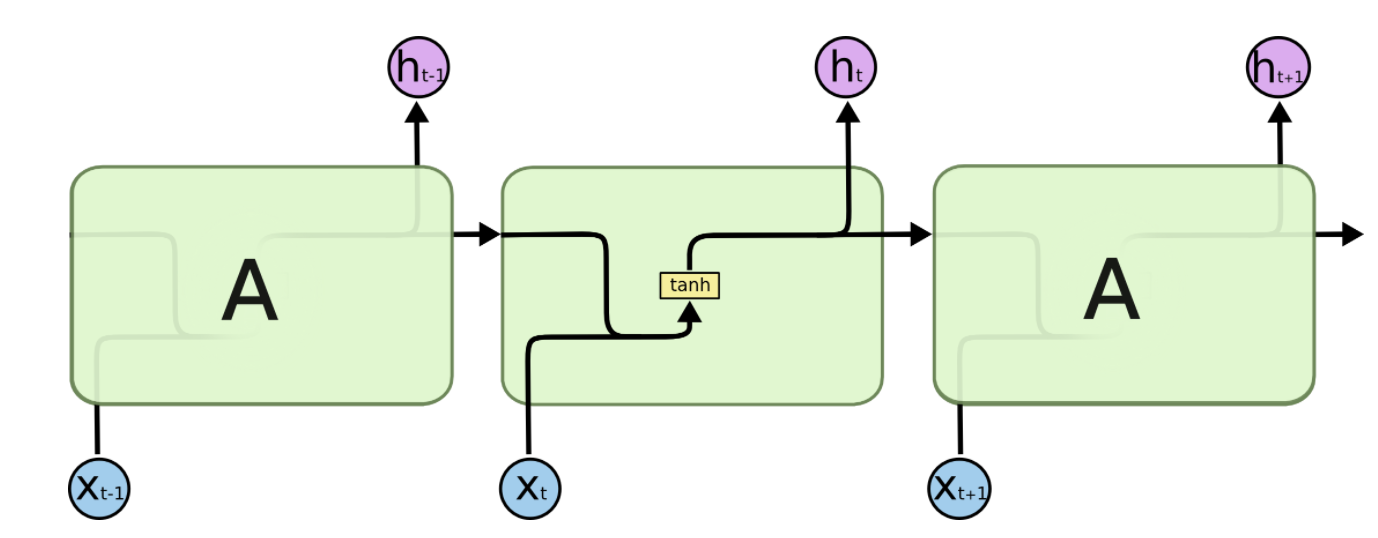
RNN
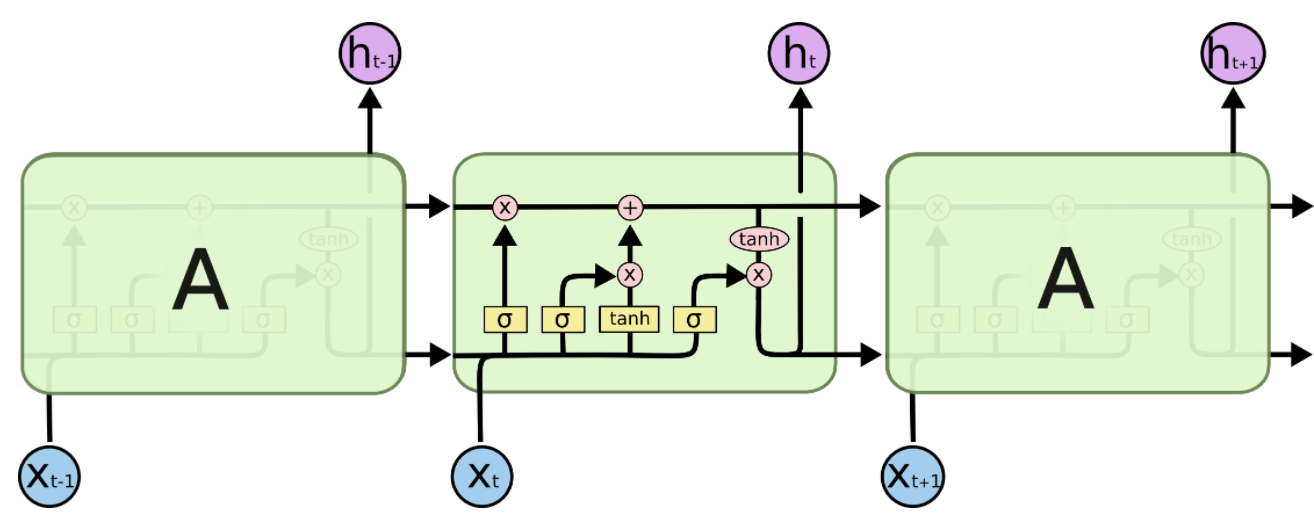
LSTM
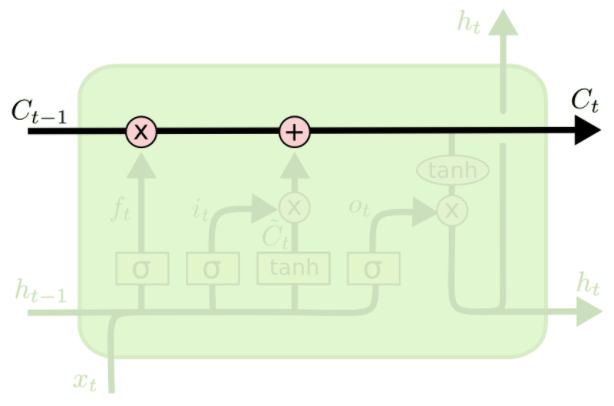
LSTM中最重要的就是這個Cell State,它一路向下,貫穿這個時間線,代表了記憶的紐帶。它會被XOR和AND運算子搞一搞,來更更新記憶
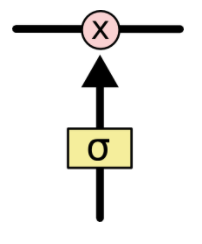
而控制資訊的增加和減少的,就是靠這些閥門:Gate
閥門嘛,就是輸出一個1於0之間的值:
1 代表,把這一趟的資訊都記著
0 代表,這一趟的資訊可以忘記了
下面我們來模擬一遍資訊在LSTM里跑跑~
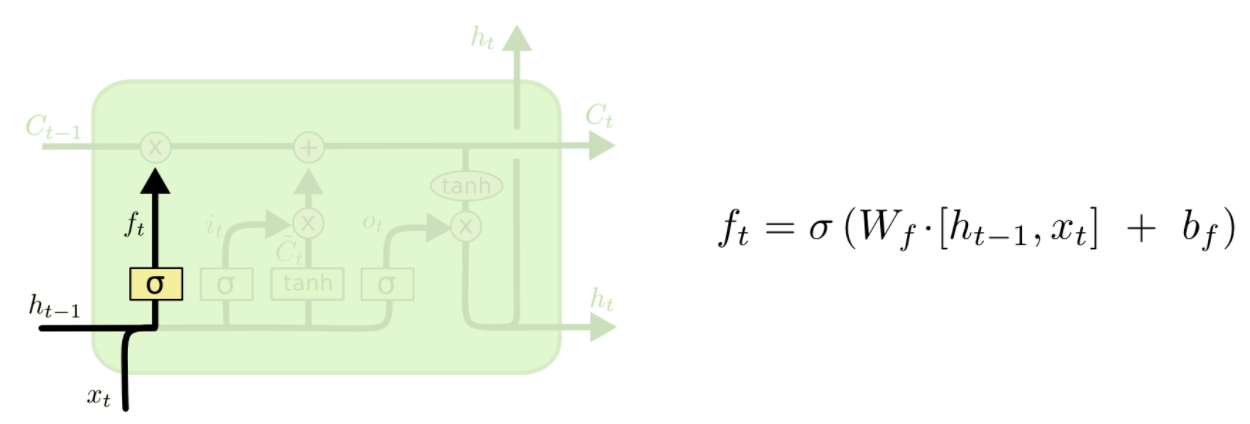
第一步:忘記門
來決定我們該忘記什麼資訊
它把上一次的狀態ht-1和這一次的輸入xt相比較
通過gate輸出一個0到1的值(就像是個activation function一樣),
1 代表:給我記著!
0 代表:快快忘記!
第二步:記憶門
哪些該記住
這個門比較複雜,分兩步:
第一步,用sigmoid決定什什麼資訊需要被我們更新(忘記舊的)
第二部,用Tanh造一個新的Cell State(更更新後的cell state)
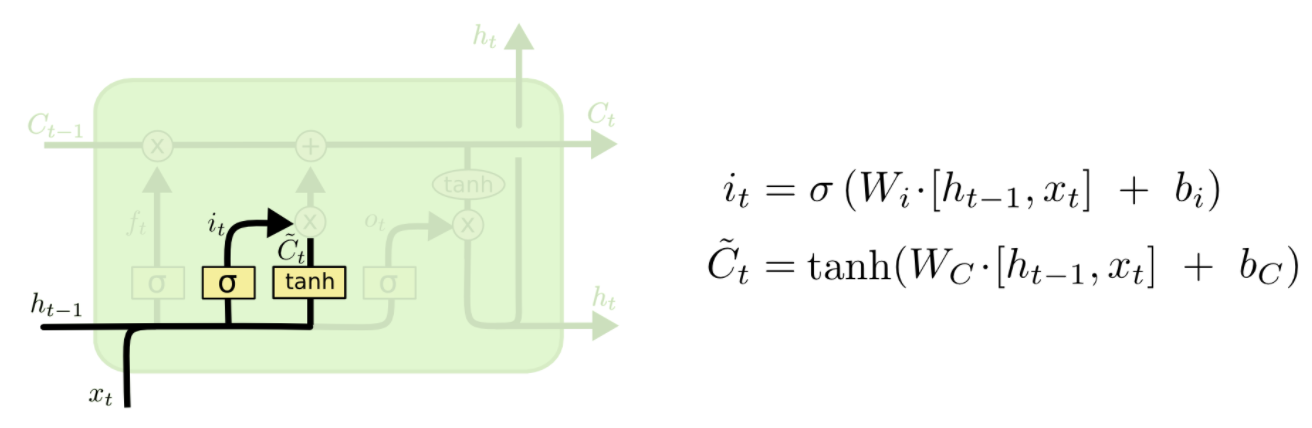
第三步:更新門
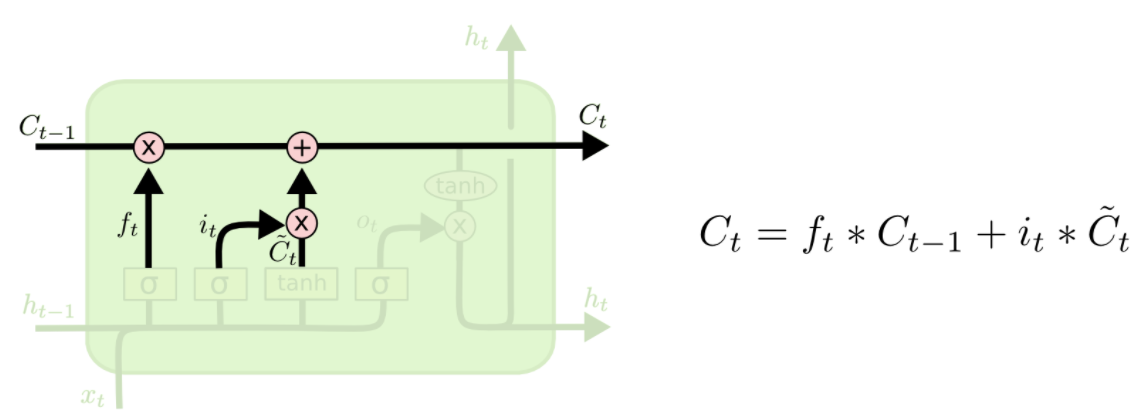
把老cell state更新為新cell state
用XOR和AND這樣的門來更新我們的cell state:
第四步:輸出門
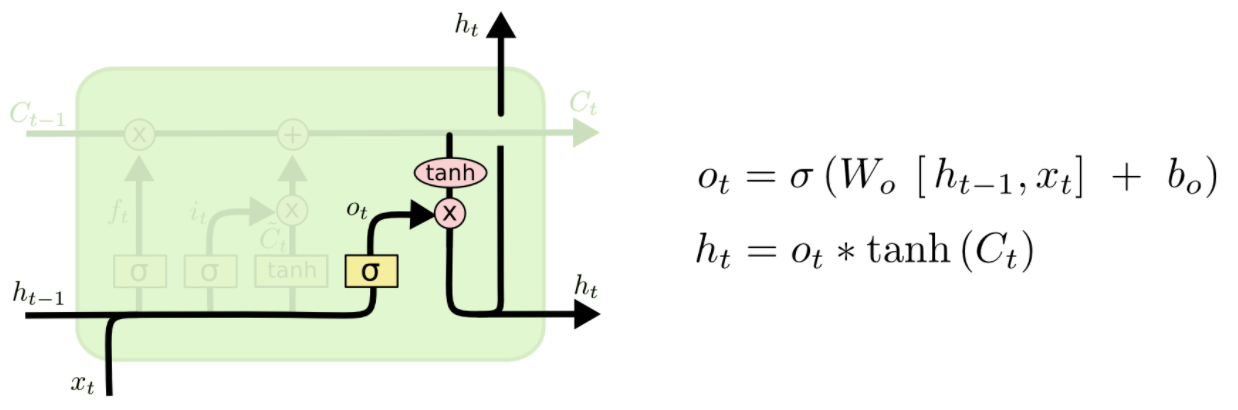
由記憶來決定輸出什什麼值
我們的Cell State已經被更更新,
於是我們通過這個記憶紐帶,來決定我們的輸出:
(這里的Ot類似於我們剛剛RNN裡里直接一步跑出來的output)
案例
題目原型:What’s Next?
可以用在不不同的維度上:
維度1:下一個字母是什麼?
維度2:下一個單詞是什麼?
維度3:下一個句子是什麼?
維度N:下一個圖片/音符/….是什麼?
用RNN做文字生成
舉個小小的例子,來看看LSTM是怎麼玩的
我們這裡用溫斯頓丘吉爾的人物傳記作為我們的學習語料。
第一步,一樣,先匯入各種庫
import numpy from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import LSTM from keras.callbacks import ModelCheckpoint from keras.utils import np_utils
Using Theano backend. Using gpu device 0: Tesla K80 (CNMeM is disabled, cuDNN 5105) /usr/local/lib/python3.5/dist-packages/theano/sandbox/cuda/__init__.py:600: UserWarning: Your cuDNN version is more recent than the one Theano officially supports. If you see any problems, try updating Theano or downgrading cuDNN to version 5. warnings.warn(warn)
接下來,我們把文字讀入
raw_text = open('../input/Winston_Churchil.txt').read()
raw_text = raw_text.lower()
既然我們是以每個字母為層級,字母總共才26個,所以我們可以很方便的用One-Hot來編碼出所有的字母(當然,可能還有些標點符號和其他noise)
chars = sorted(list(set(raw_text))) char_to_int = dict((c, i) for i, c in enumerate(chars)) int_to_char = dict((i, c) for i, c in enumerate(chars))
我們看到,全部的chars:
chars
['\n',
' ',
'!',
'#',
'$',
'%',
'(',
')',
'*',
',',
'-',
'.',
'/',
'0',
'1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
':',
';',
'?',
'@',
'[',
']',
'_',
'a',
'b',
'c',
'd',
'e',
'f',
'g',
'h',
'i',
'j',
'k',
'l',
'm',
'n',
'o',
'p',
'q',
'r',
's',
't',
'u',
'v',
'w',
'x',
'y',
'z',
'‘',
'’',
'“',
'”',
'\ufeff']
一共有:
len(chars)
61
同時,我們的原文字一共有:
len(raw_text)
276830
我們這裡簡單的文字預測就是,給了前置的字母以後,下一個字母是誰?
比如,Winsto, 給出 n Britai 給出 n
構造訓練測試集
我們需要把我們的raw text變成可以用來訓練的x,y:
x 是前置字母們 y 是後一個字母
seq_length = 100
x = []
y = []
for i in range(0, len(raw_text) - seq_length):
given = raw_text[i:i + seq_length]
predict = raw_text[i + seq_length]
x.append([char_to_int[char] for char in given])
y.append(char_to_int[predict])
我們可以看看我們做好的資料集的長相:
print(x[:3]) print(y[:3])
[[60, 45, 47, 44, 39, 34, 32, 49, 1, 36, 50, 49, 34, 43, 31, 34, 47, 36, 57, 48, 1, 47, 34, 30, 41, 1, 48, 44, 41, 33, 38, 34, 47, 48, 1, 44, 35, 1, 35, 44, 47, 49, 50, 43, 34, 9, 1, 31, 54, 1, 47, 38, 32, 37, 30, 47, 33, 1, 37, 30, 47, 33, 38, 43, 36, 1, 33, 30, 51, 38, 48, 0, 0, 49, 37, 38, 48, 1, 34, 31, 44, 44, 40, 1, 38, 48, 1, 35, 44, 47, 1, 49, 37, 34, 1, 50, 48, 34, 1, 44], [45, 47, 44, 39, 34, 32, 49, 1, 36, 50, 49, 34, 43, 31, 34, 47, 36, 57, 48, 1, 47, 34, 30, 41, 1, 48, 44, 41, 33, 38, 34, 47, 48, 1, 44, 35, 1, 35, 44, 47, 49, 50, 43, 34, 9, 1, 31, 54, 1, 47, 38, 32, 37, 30, 47, 33, 1, 37, 30, 47, 33, 38, 43, 36, 1, 33, 30, 51, 38, 48, 0, 0, 49, 37, 38, 48, 1, 34, 31, 44, 44, 40, 1, 38, 48, 1, 35, 44, 47, 1, 49, 37, 34, 1, 50, 48, 34, 1, 44, 35], [47, 44, 39, 34, 32, 49, 1, 36, 50, 49, 34, 43, 31, 34, 47, 36, 57, 48, 1, 47, 34, 30, 41, 1, 48, 44, 41, 33, 38, 34, 47, 48, 1, 44, 35, 1, 35, 44, 47, 49, 50, 43, 34, 9, 1, 31, 54, 1, 47, 38, 32, 37, 30, 47, 33, 1, 37, 30, 47, 33, 38, 43, 36, 1, 33, 30, 51, 38, 48, 0, 0, 49, 37, 38, 48, 1, 34, 31, 44, 44, 40, 1, 38, 48, 1, 35, 44, 47, 1, 49, 37, 34, 1, 50, 48, 34, 1, 44, 35, 1]] [35, 1, 30]
此刻,樓上這些表達方式,類似就是一個詞袋,或者說 index。
接下來我們做兩件事:
-
我們已經有了一個input的數字表達(index),我們要把它變成LSTM需要的陣列格式: [樣本數,時間步伐,特徵]
-
第二,對於output,我們在Word2Vec裡學過,用one-hot做output的預測可以給我們更好的效果,相對於直接預測一個準確的y數值的話。
n_patterns = len(x) n_vocab = len(chars) # 把x變成LSTM需要的樣子 x = numpy.reshape(x, (n_patterns, seq_length, 1)) # 簡單normal到0-1之間 x = x / float(n_vocab) # output變成one-hot y = np_utils.to_categorical(y) print(x[11]) print(y[11])
[[ 0.80327869] [ 0.55737705] [ 0.70491803] [ 0.50819672] [ 0.55737705] [ 0.7704918 ] [ 0.59016393] [ 0.93442623] [ 0.78688525] [ 0.01639344] [ 0.7704918 ] [ 0.55737705] [ 0.49180328] [ 0.67213115] [ 0.01639344] [ 0.78688525] [ 0.72131148] [ 0.67213115] [ 0.54098361] [ 0.62295082] [ 0.55737705] [ 0.7704918 ] [ 0.78688525] [ 0.01639344] [ 0.72131148] [ 0.57377049] [ 0.01639344] [ 0.57377049] [ 0.72131148] [ 0.7704918 ] [ 0.80327869] [ 0.81967213] [ 0.70491803] [ 0.55737705] [ 0.14754098] [ 0.01639344] [ 0.50819672] [ 0.8852459 ] [ 0.01639344] [ 0.7704918 ] [ 0.62295082] [ 0.52459016] [ 0.60655738] [ 0.49180328] [ 0.7704918 ] [ 0.54098361] [ 0.01639344] [ 0.60655738] [ 0.49180328] [ 0.7704918 ] [ 0.54098361] [ 0.62295082] [ 0.70491803] [ 0.59016393] [ 0.01639344] [ 0.54098361] [ 0.49180328] [ 0.83606557] [ 0.62295082] [ 0.78688525] [ 0. ] [ 0. ] [ 0.80327869] [ 0.60655738] [ 0.62295082] [ 0.78688525] [ 0.01639344] [ 0.55737705] [ 0.50819672] [ 0.72131148] [ 0.72131148] [ 0.6557377 ] [ 0.01639344] [ 0.62295082] [ 0.78688525] [ 0.01639344] [ 0.57377049] [ 0.72131148] [ 0.7704918 ] [ 0.01639344] [ 0.80327869] [ 0.60655738] [ 0.55737705] [ 0.01639344] [ 0.81967213] [ 0.78688525] [ 0.55737705] [ 0.01639344] [ 0.72131148] [ 0.57377049] [ 0.01639344] [ 0.49180328] [ 0.70491803] [ 0.8852459 ] [ 0.72131148] [ 0.70491803] [ 0.55737705] [ 0.01639344] [ 0.49180328] [ 0.70491803]] [ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
模型建造
LSTM模型構建
model = Sequential() model.add(LSTM(256, input_shape=(x.shape[1], x.shape[2]))) model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam')
跑模型
model.fit(x, y, nb_epoch=50, batch_size=4096)
Epoch 1/50 276730/276730 [==============================] - 197s - loss: 3.1120 Epoch 2/50 276730/276730 [==============================] - 197s - loss: 3.0227 Epoch 3/50 276730/276730 [==============================] - 197s - loss: 2.9910 Epoch 4/50 276730/276730 [==============================] - 197s - loss: 2.9337 Epoch 5/50 276730/276730 [==============================] - 197s - loss: 2.8971 Epoch 6/50 276730/276730 [==============================] - 197s - loss: 2.8784 Epoch 7/50 276730/276730 [==============================] - 197s - loss: 2.8640 Epoch 8/50 276730/276730 [==============================] - 197s - loss: 2.8516 Epoch 9/50 276730/276730 [==============================] - 197s - loss: 2.8384 Epoch 10/50 276730/276730 [==============================] - 197s - loss: 2.8254 Epoch 11/50 276730/276730 [==============================] - 197s - loss: 2.8133 Epoch 12/50 276730/276730 [==============================] - 197s - loss: 2.8032 Epoch 13/50 276730/276730 [==============================] - 197s - loss: 2.7913 Epoch 14/50 276730/276730 [==============================] - 197s - loss: 2.7831 Epoch 15/50 276730/276730 [==============================] - 197s - loss: 2.7744 Epoch 16/50 276730/276730 [==============================] - 197s - loss: 2.7672 Epoch 17/50 276730/276730 [==============================] - 197s - loss: 2.7601 Epoch 18/50 276730/276730 [==============================] - 197s - loss: 2.7540 Epoch 19/50 276730/276730 [==============================] - 197s - loss: 2.7477 Epoch 20/50 276730/276730 [==============================] - 197s - loss: 2.7418 Epoch 21/50 276730/276730 [==============================] - 197s - loss: 2.7360 Epoch 22/50 276730/276730 [==============================] - 197s - loss: 2.7296 Epoch 23/50 276730/276730 [==============================] - 197s - loss: 2.7238 Epoch 24/50 276730/276730 [==============================] - 197s - loss: 2.7180 Epoch 25/50 276730/276730 [==============================] - 197s - loss: 2.7113 Epoch 26/50 276730/276730 [==============================] - 197s - loss: 2.7055 Epoch 27/50 276730/276730 [==============================] - 197s - loss: 2.7000 Epoch 28/50 276730/276730 [==============================] - 197s - loss: 2.6934 Epoch 29/50 276730/276730 [==============================] - 197s - loss: 2.6859 Epoch 30/50 276730/276730 [==============================] - 197s - loss: 2.6800 Epoch 31/50 276730/276730 [==============================] - 197s - loss: 2.6741 Epoch 32/50 276730/276730 [==============================] - 197s - loss: 2.6669 Epoch 33/50 276730/276730 [==============================] - 197s - loss: 2.6593 Epoch 34/50 276730/276730 [==============================] - 197s - loss: 2.6529 Epoch 35/50 276730/276730 [==============================] - 197s - loss: 2.6461 Epoch 36/50 276730/276730 [==============================] - 197s - loss: 2.6385 Epoch 37/50 276730/276730 [==============================] - 197s - loss: 2.6320 Epoch 38/50 276730/276730 [==============================] - 197s - loss: 2.6249 Epoch 39/50 276730/276730 [==============================] - 197s - loss: 2.6187 Epoch 40/50 276730/276730 [==============================] - 197s - loss: 2.6110 Epoch 41/50 276730/276730 [==============================] - 192s - loss: 2.6039 Epoch 42/50 276730/276730 [==============================] - 141s - loss: 2.5969 Epoch 43/50 276730/276730 [==============================] - 140s - loss: 2.5909 Epoch 44/50 276730/276730 [==============================] - 140s - loss: 2.5843 Epoch 45/50 276730/276730 [==============================] - 140s - loss: 2.5763 Epoch 46/50 276730/276730 [==============================] - 140s - loss: 2.5697 Epoch 47/50 276730/276730 [==============================] - 141s - loss: 2.5635 Epoch 48/50 276730/276730 [==============================] - 140s - loss: 2.5575 Epoch 49/50 276730/276730 [==============================] - 140s - loss: 2.5496 Epoch 50/50 276730/276730 [==============================] - 140s - loss: 2.5451Out[11]:
<keras.callbacks.History at 0x7fb6121b6e48>
我們來寫個程式,看看我們訓練出來的LSTM的效果:
def predict_next(input_array):
x = numpy.reshape(input_array, (1, seq_length, 1))
x = x / float(n_vocab)
y = model.predict(x)
return y
def string_to_index(raw_input):
res = []
for c in raw_input[(len(raw_input)-seq_length):]:
res.append(char_to_int[c])
return res
def y_to_char(y):
largest_index = y.argmax()
c = int_to_char[largest_index]
return c
好,寫成一個大程式:
def generate_article(init, rounds=200):
in_string = init.lower()
for i in range(rounds):
n = y_to_char(predict_next(string_to_index(in_string)))
in_string += n
return in_string
init = 'His object in coming to New York was to engage officers for that service. He came at an opportune moment' article = generate_article(init) print(article)
his object in coming to new york was to engage officers for that service. he came at an opportune moment th the toote of the carie and the soote of the carie and the soote of the carie and the soote of the carie and the soote of the carie and the soote of the carie and the soote of the carie and the soo
用RNN做文字生成
舉個小小的例子,來看看LSTM是怎麼玩的
我們這裡不再用char級別,我們用word級別來做。
第一步,一樣,先匯入各種庫
import os import numpy as np import nltk from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import LSTM from keras.callbacks import ModelCheckpoint from keras.utils import np_utils from gensim.models.word2vec import Word2Vec
接下來,我們把文字讀入
raw_text = ''
for file in os.listdir("../input/"):
if file.endswith(".txt"):
raw_text += open("../input/"+file, errors='ignore').read() + '\n\n'
# raw_text = open('../input/Winston_Churchil.txt').read()
raw_text = raw_text.lower()
sentensor = nltk.data.load('tokenizers/punkt/english.pickle')
sents = sentensor.tokenize(raw_text)
corpus = []
for sen in sents:
corpus.append(nltk.word_tokenize(sen))
print(len(corpus))
print(corpus[:3])
91007 [['\ufeffthe', 'project', 'gutenberg', 'ebook', 'of', 'great', 'expectations', ',', 'by', 'charles', 'dickens', 'this', 'ebook', 'is', 'for', 'the', 'use', 'of', 'anyone', 'anywhere', 'at', 'no', 'cost', 'and', 'with', 'almost', 'no', 'restrictions', 'whatsoever', '.'], ['you', 'may', 'copy', 'it', ',', 'give', 'it', 'away', 'or', 're-use', 'it', 'under', 'the', 'terms', 'of', 'the', 'project', 'gutenberg', 'license', 'included', 'with', 'this', 'ebook', 'or', 'online', 'at', 'www.gutenberg.org', 'title', ':', 'great', 'expectations', 'author', ':', 'charles', 'dickens', 'posting', 'date', ':', 'august', '20', ',', '2008', '[', 'ebook', '#', '1400', ']', 'release', 'date', ':', 'july', ',', '1998', 'last', 'updated', ':', 'september', '25', ',', '2016', 'language', ':', 'english', 'character', 'set', 'encoding', ':', 'utf-8', '***', 'start', 'of', 'this', 'project', 'gutenberg', 'ebook', 'great', 'expectations', '***', 'produced', 'by', 'an', 'anonymous', 'volunteer', 'great', 'expectations', '[', '1867', 'edition', ']', 'by', 'charles', 'dickens', '[', 'project', 'gutenberg', 'editor’s', 'note', ':', 'there', 'is', 'also', 'another', 'version', 'of', 'this', 'work', 'etext98/grexp10.txt', 'scanned', 'from', 'a', 'different', 'edition', ']', 'chapter', 'i', 'my', 'father’s', 'family', 'name', 'being', 'pirrip', ',', 'and', 'my', 'christian', 'name', 'philip', ',', 'my', 'infant', 'tongue', 'could', 'make', 'of', 'both', 'names', 'nothing', 'longer', 'or', 'more', 'explicit', 'than', 'pip', '.'], ['so', ',', 'i', 'called', 'myself', 'pip', ',', 'and', 'came', 'to', 'be', 'called', 'pip', '.']]
好,w2v亂燉:
w2v_model = Word2Vec(corpus, size=128, window=5, min_count=5, workers=4)
可以了
w2v_model['office']
array([-0.01398709, 0.15975526, 0.03589381, -0.4449192 , 0.365403 ,
0.13376504, 0.78731823, 0.01640314, -0.29723561, -0.21117583,
0.13451998, -0.65348488, 0.06038611, -0.02000343, 0.05698346,
0.68013376, 0.19010596, 0.56921762, 0.66904438, -0.08069923,
-0.30662233, 0.26082459, -0.74816126, -0.41383636, -0.56303871,
-0.10834043, -0.10635001, -0.7193433 , 0.29722607, -0.83104628,
1.11914253, -0.34119046, -0.39490014, -0.34709939, -0.00583572,
0.17824887, 0.43295503, 0.11827419, -0.28707108, -0.02838829,
0.02565269, 0.10328653, -0.19100265, -0.24102989, 0.23023468,
0.51493132, 0.34759828, 0.05510307, 0.20583512, -0.17160387,
-0.10351282, 0.19884749, -0.03935663, -0.04055062, 0.38888735,
-0.02003323, -0.16577065, -0.15858875, 0.45083243, -0.09268586,
-0.91098118, 0.16775337, 0.3432925 , 0.2103184 , -0.42439541,
0.26097715, -0.10714807, 0.2415273 , 0.2352251 , -0.21662289,
-0.13343927, 0.11787982, -0.31010333, 0.21146733, -0.11726214,
-0.65574747, 0.04007725, -0.12032496, -0.03468512, 0.11063002,
0.33530036, -0.64098376, 0.34013858, -0.08341357, -0.54826909,
0.0723564 , -0.05169795, -0.19633259, 0.08620321, 0.05993884,
-0.14693044, -0.40531522, -0.07695422, 0.2279872 , -0.12342903,
-0.1919964 , -0.09589464, 0.4433476 , 0.38304719, 1.0319351 ,
0.82628119, 0.3677327 , 0.07600326, 0.08538571, -0.44261214,
-0.10997667, -0.03823839, 0.40593523, 0.32665277, -0.67680383,
0.32504487, 0.4009226 , 0.23463745, -0.21442334, 0.42727917,
0.19593567, -0.10731711, -0.01080817, -0.14738144, 0.15710345,
-0.01099576, 0.35833639, 0.16394758, -0.10431164, -0.28202233,
0.24488974, 0.69327635, -0.29230621], dtype=float32)
接下來,其實我們還是以之前的方式來處理我們的training data,把源資料變成一個長長的x,好讓LSTM學會predict下一個單詞:
raw_input = [item for sublist in corpus for item in sublist] len(raw_input)
2115170
raw_input[12]
'ebook'
text_stream = []
vocab = w2v_model.vocab
for word in raw_input:
if word in vocab:
text_stream.append(word)
len(text_stream)
2058753
我們這裡的文字預測就是,給了前面的單詞以後,下一個單詞是誰?
比如,hello from the other, 給出 side
構造訓練測試集
我們需要把我們的raw text變成可以用來訓練的x,y:
x 是前置字母們 y 是後一個字母
seq_length = 10
x = []
y = []
for i in range(0, len(text_stream) - seq_length):
given = text_stream[i:i + seq_length]
predict = text_stream[i + seq_length]
x.append(np.array([w2v_model[word] for word in given]))
y.append(w2v_model[predict])
我們可以看看我們做好的資料集的長相:
print(x[10]) print(y[10])
[[-0.02218935 0.04861801 -0.03001036 ..., 0.07096259 0.16345282 -0.18007144] [ 0.1663752 0.67981642 0.36581406 ..., 1.03355932 0.94110376 -1.02763569] [-0.12611888 0.75773817 0.00454156 ..., 0.80544478 2.77890372 -1.00110698] ..., [ 0.34167829 -0.28152692 -0.12020591 ..., 0.19967555 1.65415502 -1.97690392] [-0.66742641 0.82389861 -1.22558379 ..., 0.12269551 0.30856156 0.29964617] [-0.17075984 0.0066567 -0.3894183 ..., 0.23729582 0.41993639 -0.12582727]] [ 0.18125793 -1.72401989 -0.13503326 -0.42429626 1.40763748 -2.16775346 2.26685596 -2.03301549 0.42729807 -0.84830129 0.56945151 0.87243706 3.01571465 -0.38155749 -0.99618471 1.1960727 1.93537641 0.81187075 -0.83017075 -3.18952608 0.48388934 -0.03766865 -1.68608069 -1.84907544 -0.95259917 0.49039507 -0.40943271 0.12804921 1.35876858 0.72395176 1.43591952 -0.41952157 0.38778016 -0.75301784 -2.5016799 -0.85931653 -1.39363682 0.42932403 1.77297652 0.41443667 -1.30974782 -0.08950856 -0.15183811 -1.59824061 -1.58920395 1.03765178 2.07559252 2.79692245 1.11855054 -0.25542653 -1.04980111 -0.86929852 -1.26279402 -1.14124119 -1.04608357 1.97869778 -2.23650813 -2.18115139 -0.26534671 0.39432198 -0.06398458 -1.02308178 1.43372631 -0.02581184 -0.96472031 -3.08931994 -0.67289352 1.06766248 -1.95796657 1.40857184 0.61604798 -0.50270212 -2.33530831 0.45953822 0.37867084 -0.56957626 -1.90680516 -0.57678169 0.50550407 -0.30320352 0.19682285 1.88185465 -1.40448165 -0.43952951 1.95433044 2.07346153 0.22390689 -0.95107335 -0.24579825 -0.21493609 0.66570002 -0.59126669 -1.4761591 0.86431485 0.36701021 0.12569368 1.65063572 2.048352 1.81440067 -1.36734581 2.41072559 1.30975604 -0.36556485 -0.89859813 1.28804696 -2.75488496 1.5667206 -1.75327337 0.60426879 1.77851915 -0.32698369 0.55594021 2.01069188 -0.52870172 -0.39022744 -1.1704396 1.28902853 -0.89315164 1.41299319 0.43392688 -2.52578211 -1.13480854 -1.05396986 -0.85470092 0.6618616 1.23047733 -0.28597715 -2.35096407]
print(len(x)) print(len(y)) print(len(x[12])) print(len(x[12][0])) print(len(y[12]))
2058743 2058743 10 128 128
x = np.reshape(x, (-1, seq_length, 128)) y = np.reshape(y, (-1,128))
接下來我們做兩件事:
-
我們已經有了一個input的數字表達(w2v),我們要把它變成LSTM需要的陣列格式: [樣本數,時間步伐,特徵]
-
第二,對於output,我們直接用128維的輸出
模型建造
LSTM模型構建
model = Sequential() model.add(LSTM(256, dropout_W=0.2, dropout_U=0.2, input_shape=(seq_length, 128))) model.add(Dropout(0.2)) model.add(Dense(128, activation='sigmoid')) model.compile(loss='mse', optimizer='adam')
跑模型
model.fit(x, y, nb_epoch=50, batch_size=4096)
Epoch 1/50 2058743/2058743 [==============================] - 150s - loss: 0.6839 Epoch 2/50 2058743/2058743 [==============================] - 150s - loss: 0.6670 Epoch 3/50 2058743/2058743 [==============================] - 150s - loss: 0.6625 Epoch 4/50 2058743/2058743 [==============================] - 150s - loss: 0.6598 Epoch 5/50 2058743/2058743 [==============================] - 150s - loss: 0.6577 Epoch 6/50 2058743/2058743 [==============================] - 150s - loss: 0.6562 Epoch 7/50 2058743/2058743 [==============================] - 150s - loss: 0.6549 Epoch 8/50 2058743/2058743 [==============================] - 150s - loss: 0.6537 Epoch 9/50 2058743/2058743 [==============================] - 150s - loss: 0.6527 Epoch 10/50 2058743/2058743 [==============================] - 150s - loss: 0.6519 Epoch 11/50 2058743/2058743 [==============================] - 150s - loss: 0.6512 Epoch 12/50 2058743/2058743 [==============================] - 150s - loss: 0.6506 Epoch 13/50 2058743/2058743 [==============================] - 150s - loss: 0.6500 Epoch 14/50 2058743/2058743 [==============================] - 150s - loss: 0.6496 Epoch 15/50 2058743/2058743 [==============================] - 150s - loss: 0.6492 Epoch 16/50 2058743/2058743 [==============================] - 150s - loss: 0.6488 Epoch 17/50 2058743/2058743 [==============================] - 151s - loss: 0.6485 Epoch 18/50 2058743/2058743 [==============================] - 150s - loss: 0.6482 Epoch 19/50 2058743/2058743 [==============================] - 150s - loss: 0.6480 Epoch 20/50 2058743/2058743 [==============================] - 150s - loss: 0.6477 Epoch 21/50 2058743/2058743 [==============================] - 150s - loss: 0.6475 Epoch 22/50 2058743/2058743 [==============================] - 150s - loss: 0.6473 Epoch 23/50 2058743/2058743 [==============================] - 150s - loss: 0.6471 Epoch 24/50 2058743/2058743 [==============================] - 150s - loss: 0.6470 Epoch 25/50 2058743/2058743 [==============================] - 150s - loss: 0.6468 Epoch 26/50 2058743/2058743 [==============================] - 150s - loss: 0.6466 Epoch 27/50 2058743/2058743 [==============================] - 150s - loss: 0.6464 Epoch 28/50 2058743/2058743 [==============================] - 150s - loss: 0.6463 Epoch 29/50 2058743/2058743 [==============================] - 150s - loss: 0.6462 Epoch 30/50 2058743/2058743 [==============================] - 150s - loss: 0.6461 Epoch 31/50 2058743/2058743 [==============================] - 150s - loss: 0.6460 Epoch 32/50 2058743/2058743 [==============================] - 150s - loss: 0.6458 Epoch 33/50 2058743/2058743 [==============================] - 150s - loss: 0.6458 Epoch 34/50 2058743/2058743 [==============================] - 150s - loss: 0.6456 Epoch 35/50 2058743/2058743 [==============================] - 150s - loss: 0.6456 Epoch 36/50 2058743/2058743 [==============================] - 150s - loss: 0.6455 Epoch 37/50 2058743/2058743 [==============================] - 150s - loss: 0.6454 Epoch 38/50 2058743/2058743 [==============================] - 150s - loss: 0.6453 Epoch 39/50 2058743/2058743 [==============================] - 150s - loss: 0.6452 Epoch 40/50 2058743/2058743 [==============================] - 150s - loss: 0.6452 Epoch 41/50 2058743/2058743 [==============================] - 150s - loss: 0.6451 Epoch 42/50 2058743/2058743 [==============================] - 150s - loss: 0.6450 Epoch 43/50 2058743/2058743 [==============================] - 150s - loss: 0.6450 Epoch 44/50 2058743/2058743 [==============================] - 150s - loss: 0.6449 Epoch 45/50 2058743/2058743 [==============================] - 150s - loss: 0.6448 Epoch 46/50 2058743/2058743 [==============================] - 150s - loss: 0.6447 Epoch 47/50 2058743/2058743 [==============================] - 150s - loss: 0.6447 Epoch 48/50 2058743/2058743 [==============================] - 150s - loss: 0.6446 Epoch 49/50 2058743/2058743 [==============================] - 150s - loss: 0.6446 Epoch 50/50 2058743/2058743 [==============================] - 150s - loss: 0.6445Out[130]:
<keras.callbacks.History at 0x7f6ed8816a58>
我們來寫個程式,看看我們訓練出來的LSTM的效果:
def predict_next(input_array):
x = np.reshape(input_array, (-1,seq_length,128))
y = model.predict(x)
return y
def string_to_index(raw_input):
raw_input = raw_input.lower()
input_stream = nltk.word_tokenize(raw_input)
res = []
for word in input_stream[(len(input_stream)-seq_length):]:
res.append(w2v_model[word])
return res
def y_to_word(y):
word = w2v_model.most_similar(positive=y, topn=1)
return word
好,寫成一個大程式:
def generate_article(init, rounds=30):
in_string = init.lower()
for i in range(rounds):
n = y_to_word(predict_next(string_to_index(in_string)))
in_string += ' ' + n[0][0]
return in_string
init = 'Language Models allow us to measure how likely a sentence is, which is an important for Machine' article = generate_article(init) print(article)
language models allow us to measure how likely a sentence is, which is an important for machine engagement . to-day good-for-nothing fit job job job job job . i feel thing job job job ; thing really done certainly job job ; but i need not say