
深度學習介紹及簡單應用
引言
深度學習背後的主要原理是從大腦中汲取靈感。,這種觀點產生了“神經網路”術語,大腦包含數十億個神經元,它們之間有數萬個連線。 在許多情況下,深度學習演算法類似於大腦,因為大腦和深度學習模型都涉及大量的計算單元(神經元),這些單元在未啟用時並不是活躍的,它們彼此互動時會變得智慧化。
神經元
神經網路的基本構建模組是人工神經元--模仿人類大腦神經元。 這些是強大的計算單元,具有加權輸入訊號並使用啟用功能產生輸出訊號。 這些神經元分佈在神經網路的幾個層中。

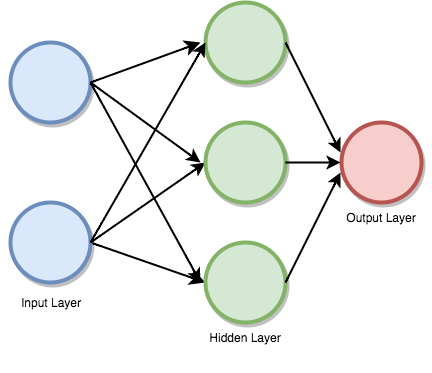
什麼網路是如何工作的?
深度學習由人工神經網路組成,這些網路以人腦中存在的類似網路為模型。 當資料通過這個人工網格時,每個層處理資料的一個方面,過濾異常值,找到合適的實體,併產生最終輸出。

- 輸入層(Input Layer):該層由神經元組成,它們不接收輸入並將其傳遞給其他層。 輸入層中的元素應等於資料集中的屬性(即變數個數)。
- 輸出圖層(Output Layer):輸出圖層是預測的特徵,它主要取決於模型的型別。
- 隱藏層(Hidden Layer):在輸入和輸出層之間,將存在基於模型型別的隱藏層。 隱藏層包含大量神經元。 隱藏層中的神經元將變換應用於輸入。 隨著網路的訓練,權重得到更新,更具預測性。
神經元的權重
權重是指兩個神經元之間連線的強度或幅度,如果您熟悉線性迴歸,則可以比較輸入的權重,例如我們在迴歸方程中使用的係數。權重通常被初始化為較小的隨機值,例如 在0到1之間。
前饋深度網路
前饋監督神經網路是第一個也是最成功的學習演算法。 它們也被稱為深度網路,多層感知器(MLP)或簡單的神經網路,並且顯示出了具有單個隱藏層的連線體系結構。
網路處理輸入變數,並向後傳遞,啟用神經元,最終產生輸出值。這被稱為網路上的前向傳遞。
啟用函式
啟用函式是加權輸入與神經元輸出的加和的對映。 它被稱為啟用或者傳遞函式,因為它控制啟用神經元的初始值和輸出訊號的強度。
表示式:
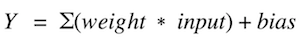
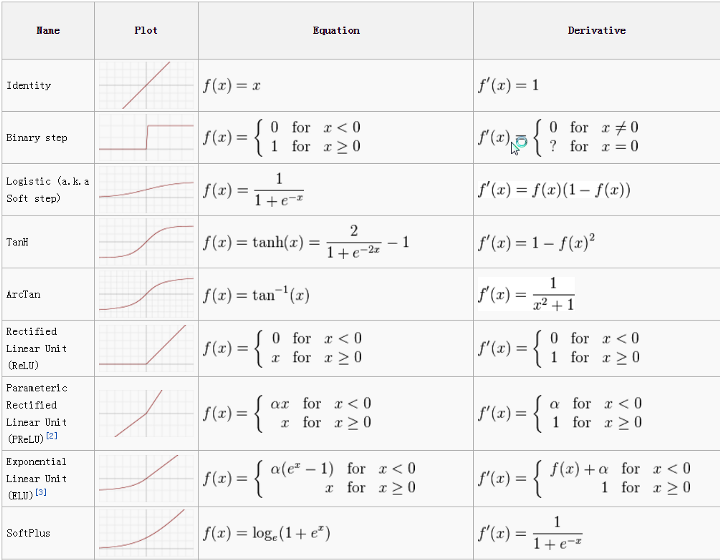
常用的有:
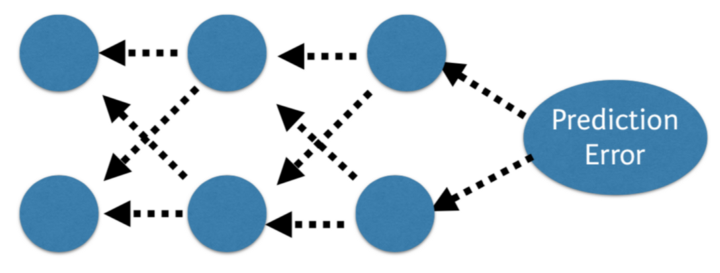
反向傳播 將網路的預測值與預期輸出進行比較,並使用函式計算誤差, 然後,該錯誤在整個網路內傳播回來,一次一層,並根據它們對錯誤的貢獻值更新權重。 這個聰明的數學運算稱為反向傳播演算法。 對訓練資料中的所有示例重複該過程。 為整個訓練資料集更新網路的一輪稱為紀元。 可以訓練網路數十,數百或數千個時期。
成本函式和梯度下降 成本函式是神經網路對其給定的訓練輸入和預期輸出所做的“有多好”的度量。 它還可能取決於權重和偏差等屬性。
成本函式是單值的,而不是向量,因為它評估神經網路作為一個整體執行得有多好。 使用梯度下降優化演算法,在每個時期之後遞增地更新權重。
成本函式:
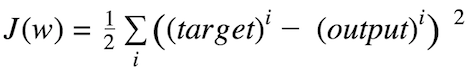
通過在成本梯度的相反方向上採取步驟來計算權重更新的大小和方向。

其中Δw是包含每個權重係數w的權重更新的向量,其計算如下:
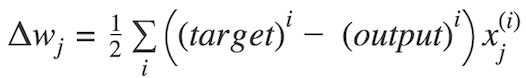
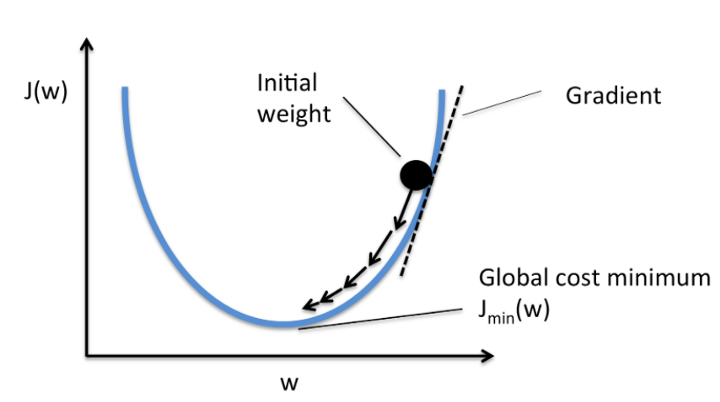
我們計算梯度下降直到導數達到最小誤差,並且每個步驟由斜率(梯度)的陡度確定。
多層感知器(前向傳播) 這類網路由多層神經元組成,通常以前饋方式互連(向前移動)。一層中的每個神經元具有與後續層的神經元的直接連線。在許多應用中,這些網路的單元應用sigmoid或ReLU作為啟用功能。
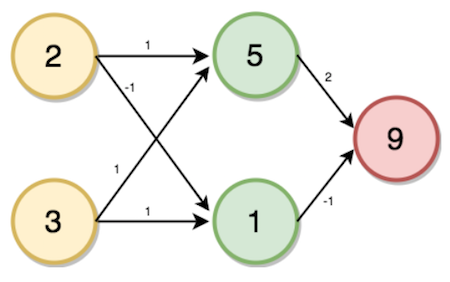
現在考慮一個問題,找出交易數量,給定帳戶和家庭成員作為輸入。
首先要解決這個問題,我們需要從建立前向傳播神經網路開始。我們的輸入圖層將是家庭成員和帳戶的數量,隱藏圖層的數量是一個,輸出圖層將是交易數量。
給定權重,如圖所示,從輸入層到隱藏層,其中家庭成員2的數量和賬戶數量3作為輸入。
現在,將通過以下步驟使用前向傳播來計算隱藏層(i,j)和輸出層(k)的值。
處理過程
- 乘法 - 新增過程。
- 點積(輸入*權重)。
- 一次一個資料點的前向傳播。
- 輸出是該資料點的預測。
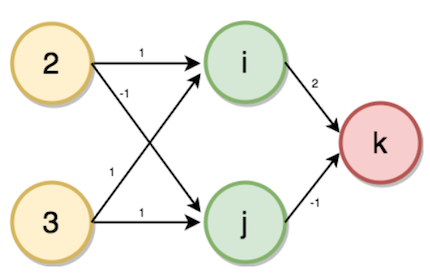
$i$的值將根據輸入值和與所連線的神經元相對應的權重來計算。
$i = (2 * 1) + (3 * 1)$
→ i = 5
類似的,
$j = (2 * -1) + (3 * 1)$
→ j = 1
$K = (5 * 2) + (1 * -1)$
→ k = 9
python 實現
為了使神經網路達到最大預測能力,我們需要為隱藏層應用啟用函式。它用於捕獲非線性。 我們將它們應用於輸入層,隱藏層以及值上的某些方程式。
這裡我們使用ReLU啟用函式。
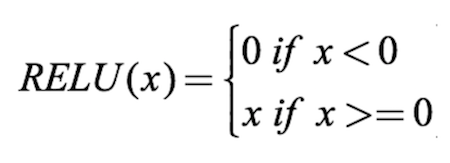
import numpy as np def relu(input): # Rectified Linear Activation output = max(input, 0) return(output) print("Enter the two values for input layers") a = int(input()) b = int(input()) input_data = np.array([a, b]) weights = { 'node_0': np.array([1, 1]), 'node_1': np.array([-1, 1]), 'output_node': np.array([2, -1]) } node_0_input = (input_data * weights['node_0']).sum() node_0_output = relu(node_0_input) node_1_input = (input_data * weights['node_1']).sum() node_1_output = relu(node_1_input) hidden_layer_outputs = np.array([node_0_output, node_1_output]) model_output = (hidden_layer_outputs * weights['output_node']).sum() print(model_output)
輸出:
Enter the two values for input layers 2 3 9