
機器學習在工業應用中的新思考
人工智慧在學術界默默發展了很多很多年,從最早的神經網路,到10年前風靡的SVM、bagging and boosting,如今的深度學習。日新月異,各領風騷數幾年。
工業界的發展從最早應用於純粹的網際網路企業,近幾年開始應用到更多更廣泛的場景,而且發展速度越來越快,陳雨強一直在機器學習的最前沿應用,下面是他最新的思考,非常非常乾貨。是一篇值得多看幾遍的好分享。
10年前說自己是做人工智慧的,大家都會一臉茫然,今天說自己是搞人工智慧的,大家都會是一臉崇拜。可見時代變遷。
提醒自己要多思考,請跟上人工智慧的發展步伐。感謝機器之心提供的這篇文章。
人工智慧成功必要的五個必要條件
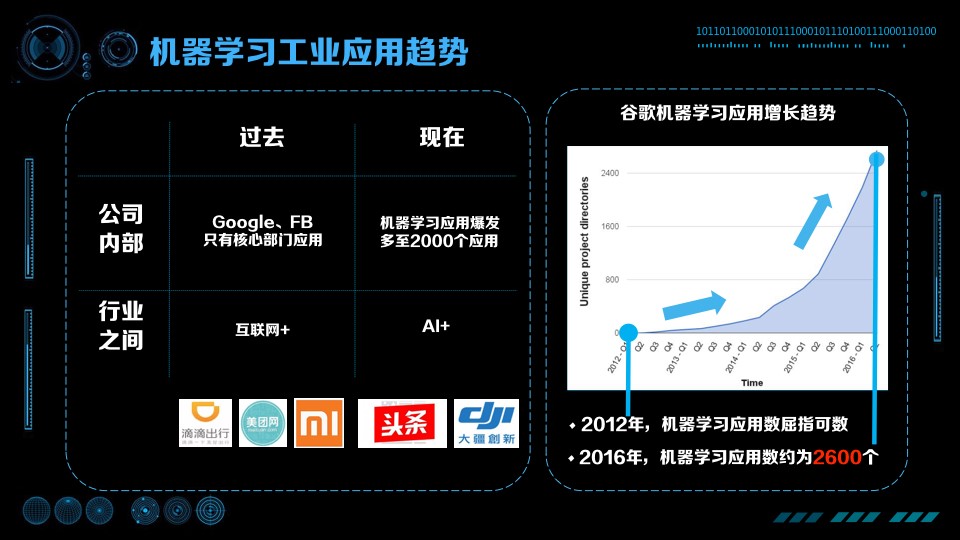
為什麼人工智慧在最近的一段時間非常火?為什麼人工智慧在 20 年前、10 年前沒有這麼火?為什麼 AlphaGo 能在今年打敗李世石而不是更早?我們直觀的會認為是因為演算法創新。但是演算法創新只是其中一點,國內外很多專家分析總結出了人工智慧成功的五個必要條件,這裡跟大家分享一下:
第一,邊界清晰。問題需要定義得非常清晰,比如 AlphaGo 做的是圍棋,圍棋是在 19×19 的棋盤上,黑白兩方輪流下子的問題,有吃有打劫。如果變成一個開放的問題,變成 20×20 的棋盤,變成黑白灰三方下棋,或者把打劫規則變一下,都會導致人工智慧的失敗。
第二,外部反饋。演算法要不斷的有外部輸入,知道我們在什麼樣的情況、演算法做出什麼樣的行為下,外部給出的反饋是什麼,這樣才能促進提高,比方說需要 AlphaGo 不斷地進行對弈,並且告訴它對弈的輸贏。
第三,計算資源。近些年演算法雖然有很大的進步,但計算資源也是產生智慧的關鍵。最近業界在分散式計算上的成功,讓我們相對於幾十年前有了飛躍的基礎。舉個非常有趣的例子,Google 在描述 AlphaGo 不同版本的時候,為了簡潔明瞭,直接使用計算能力來分類,而不是使用演算法來分類。簡版的 AlphaGo 被稱作「單機訓練的 AlphaGo」,複雜、更高智慧的 AlphaGo 稱為「多機、並行訓練的 AlphaGo」,從這裡也可以看出,計算資源起著至關重要的作用。
第四,頂尖的資料科學家和人工智慧科學家。增強學習、深度學習最近重新被提出,需要很多科學家大量的工作,才能讓這些演算法真正的推行,除了圍棋、視覺、語音之外,還有非常多的領域等待被探索。
第五,大資料。AlphaGo 的成功,關鍵的一點是 KGS 棋社的流行,KGS 上有數十萬盤高手對戰的棋譜,沒有這些資料 AlphaGo 絕對不可能這麼短的時間內打敗人類。
這些要素總結起來只有三點:一方面是技術,計算資源和大資料方面的支援;一方面是業務,邊界要清晰,業務有反饋;另一方面是人,包括科學家,包括應用到場景需要和人打交道。所以如果一個 AI 要成功的話總結起來三點,要關注技術、要關注業務、要關注人。工業界需要可擴充套件的機器學習系統
人工智慧的興起是計算能力、機器學習以及分散式計算髮展的結果。在實際的工業界之中,我們需要一個可擴充套件的機器學習系統(Scalable Machine Learning System),而不僅僅是一個可擴充套件系統(Scalable System),那什麼是可擴充套件的機器學習系統?

第一點,資料處理的能力隨機器的增加而增加,這是傳統的可擴充套件。第二點,智慧水平和體驗壁壘要隨著業務、資料量的增加而同時增加。這個角度的 Scalable 是很少被提到的,但這個層面上的可擴充套件性才是人工智慧被推崇的核心原因。
舉個例子,過去建立競爭壁壘主要通過業務創新快、行業內跑馬圈地,或是通過藉助新的渠道(比方說網際網路)提升效率。在這樣的方式中,由於產品本身相對容易被抄襲,那麼資本投入、運營與渠道是關鍵。但隨著資料的增加與 AI 的普及,現在有了一種新的方式,就是用時間與資料創造壁壘。舉個簡單的例子,如果現在去做一個搜尋引擎,即使有百度現成的技術現在也很難做得過百度,因為百度積累了長時間的資料,用同樣的演算法也很難跑出一個比百度更好的搜尋結果。這樣如果擁有能用好資料的人工智慧,就會獲得更好的體驗,反過來更好的體驗又會帶來更多的使用者,進一步豐富資料,促進人工智慧的提高。可以看出,由人工智慧產生的競爭壁壘是不斷迴圈迭代提升、更容易拉開差距的高牆。
可擴充套件的機器學習系統需要高 VC 維
那麼,我們怎麼能獲得一個既擁有高智慧水平又能 Scalable 的學習系統呢?
60 年代 Vapnik 和 Chervonenkis 提出了 VC 維理論,形式化的描述了機器學習演算法對複雜函式擬合的能力。對 VC 維的理解,可以舉個簡單的例子就類似於人大腦內的神經元,神經元數量越多,這個人可能就越聰明。當然,這個不是絕對的,智商高的人不一定做出來的成就是最高的,這裡關鍵的一點是個人的經歷也要多,之後經歷過很多事情、並且有思考的能力,才能悟出道理。在機器學習中,VC 維度講的也是這個道理。
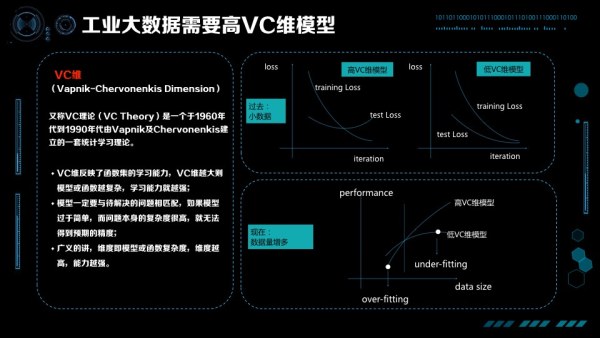
教科書上的 VC 維都是上面這樣的一張圖。因為過去的資料不大,訓練損失函式在不斷下降,測試損失函式在不斷的上升,要避免過擬合,VC 維就不能太高。比如你是個很聰明的孩子,但是在很小的時候不能讓你過多的思考瞎琢磨,否則很有可能走火入魔。過去對我們教導是在你經歷不多、資料不多時乾脆傻一點,就沒有那麼多精力去思考亂七八糟的事情。這是當時大家覺得比較好的解法,控制 VC 維,讓訓練資料的 Test Loss、Training Loss 同時下降。
但隨著時代的不斷髮展,資料也是在不斷增多的,我們的觀點有了新的變化。在資料量比較小的時候,高 VC 維的模型比低 VC 維的模型效果要差,產生了 over-fitting,這只是故事的一部分;有了更多資料以後,我們發現低 VC 維模型效果再也漲不上去了,但高的 VC 維模型還在不斷上升。這就是剛才說的智慧 Scalable 的概念,在我們有越來越多資料的時候,要關心的是 under-fitting 而不是 over-fitting,要關心的是怎樣提高 VC 維讓模型更加聰明,悟出大資料中的道理。
總結成一句話,如果要成功在工業界使用人工智慧,VC 維是非常重要的問題。
工業界怎麼提升 VC 維呢?我們知道「機器學習=資料+特徵+模型」,如果已經有很多資料,提升 VC 維的方法有兩條:一種是從特徵提升,一種是從模型提升。我們把特徵分為兩類:一類特徵叫巨集觀特徵,比如描述類特徵如年齡、統計類特徵如整體的點選率、或整體的統計資訊;另一類為微觀特徵,最典型的是 ID 類的特徵,每個人都有特徵,每個物品也有特徵,人和物品組合也有特徵。相應的模型也分為兩類,一部分是簡單模型如線性模型,另一類是複雜模型如深度學習模型。這裡,我們可以引出工業界機器學習四個象限的概念。
模型 X 特徵,工業界機器學習的四個象限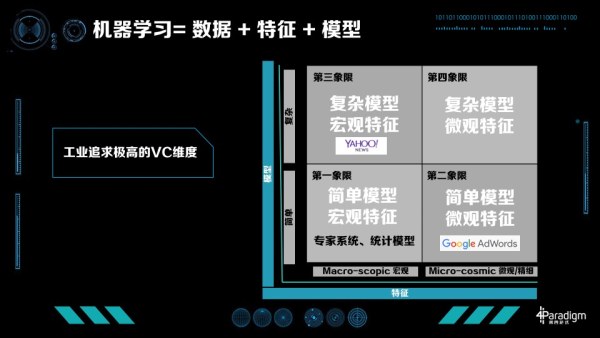
工業界具體怎麼做的?第一象限是簡單模型加上巨集觀特徵,在現在的工業界比較難以走通,很難得到極致化的優化效果。這個象限內,有七八十年代專家系統,還有一些統計模型。大家比較熟悉的 UCI Data 就是支援這個時代研究的典型資料,每個資料集有 1000 個左右的訓練資料,分的類數也不多,特徵也不多。對於這樣的資料統計模型比較盛行,要解決的問題是怎樣找出特徵之間的關係與各自的統計特性。
第二象限是簡單模型、複雜特徵,最成功的典型案例是 Google AdWords。Google 在很多技術上都是開山鼻祖,包括整個計算廣告學。Google AdWords 有上千億的特徵,每個人、每個廣告、每個 Query 的組合都在其中。這種模型非常成功,給 Google 帶來了非常大的收益。Google AdWords 佔 Google 70% 以上的收入,Google 的展示廣告也是用的這樣的技術,佔了 Google 大概剩下的 20% 左右的收入。
第三象限是複雜模型、巨集觀特徵典型的應用,比如 Bing ads,2013 年他們提出 BPR(Bayesian Probit Regression)來 Model 每個特徵的置信度。雅虎也是第三象限忠實的傳道士之一,大家所熟知的 COEC(Click Over Expected Click)這個演算法就是雅虎提出的,在上面做了很多模型。其次他們還設計了很多模型解決增強學習問題,比如多臂老虎機等等演算法。很多雅虎出去創業的同事最常使用的機器學習技術就是統計特徵加 GBDT(Gradient Boosting Decision Tree),通常能獲得非常好的效果。
第四象限,複雜模型和微觀特徵,現在還是熱門研究的領域,它最難的一點是模型的規模實在太大。比如廣告有上千億的特徵,如果做深度學習模型一個隱層有 1000 個特徵,可能會有萬萬億級別的引數。雖然資料很多,但萬萬億的資料還是難以獲得的。所以怎麼解決這個角度的模型複雜問題、正則化問題,目前研究還是一個熱點的研究方向。
如何沿著模型優化?

沿著模型優化主要由學術界主導,新的模型主要來自於 ICML、NIPS、ICLR 這樣的會議。他們主要的研究是非線性的,總結起來有「三把寶劍」:Kernel、Boosting、Neural Network。Boosting、Neural Network 現在非常流行,Boosting 最成功的是 GBDT,而 Neural Network 也在很多行業產生了顛覆性的變化。大約十年前,Kernel 也是很流行的。藉助 Kernel,SVM 有了異常強大的非線效能力,讓 SVM 風靡了 10-15 年。優化模型的科學家們為了實驗的方便,對工程實現的能力要求並不是特別高,大部分模型是可以單機載入的。要解決的實際問題主要是資料分散式,降低資料分散式帶來的通訊 overhead 等問題。
對於工業界中的具體問題,基於思考或觀察得到新的假設,加入新的模型、結構,以獲得更多的引數,這是工業界優化這一項限的步驟。
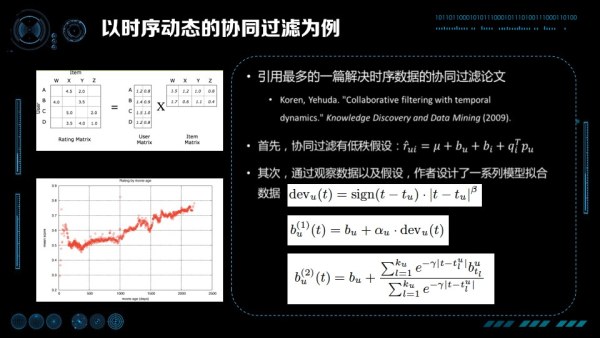
以時序動態的協同過濾為例,我們這裡引用的是 Koren, Yehuda 在 2009 年在 KDD 上發表的論文 Collaborative filtering with temporal dynamics,這是時序動態協同過濾被應用最多的一篇經典論文。在這篇論文裡,首先協同過濾的問題有一個低秩假設,作者認為由 User,Item 組成的稀疏矩陣是由兩個低秩矩陣相乘得到預估評分。第二,通過觀察資料,作者觀察到 IMDB 對某些電影的打分是隨著時間的加長,分數不斷上升(對那些經典的電影)。根據這樣線性的關係,設計「現在的時間」減去「首次被打分時間」作為偏置,擬合斜率就是一個好的模型。考慮到更復雜的情況下,打分隨時間的變化並不是單純的線性,作者進一步提出將線分成很多小段,每個小段做分段線性。
總結一下,通過機器學習優化的套路是什麼?首先,觀察資料;第二,找到規律;第三,根據規律做模型的假設;第四,對模型假設中的引數用資料進行擬合;第五,把擬合的結果用到線上,看看效果怎麼樣。這是模型這條路在工業界上優化的方法。
如何沿特徵優化?

特徵優化主要是工業界主導的,成果主要發表在 KDD、ADKDD 或者 WWW 上,這些模型相對簡單粗暴。主要是 LR,比較簡單,粗暴是說它的特徵會特別多。就像剛才提到的,Google 使用了上千億的特徵,百度也使用了上千億的特徵,這些特徵都是從最細的角度描述資料。
沿模型優化這條路的主要特點是什麼?模型一定是分散式的,同時工程挑戰是非常大的。上千億的特徵是什麼概念?即使一個引數用一個 Float 儲存,也需要上百 G 到上 T 的記憶體,是單機很難儲存下來的。這還只是模型所佔的內容空間,訓練起來還有其他中間引數與變數、資料也還要佔記憶體,所以這些演算法一定是模型分散式的。針對這些難點,學術界中 KDD 和 WWW 等會議上都在研究如何高效並行,以及如何保證高效並行的時候快速收斂。ASP、BSP 等模型和同步、非同步的演算法,都是為了保證高效分散式的同時能快速收斂。
應為線性模型理論較為成熟,工業界對模型本身的優化相對沒有那麼多,其更主要的工作是針對具體的應用提取特徵。為什麼會有那麼多特徵?因為我們對所有觀察到的微觀變數都進行建模。以搜尋廣告為例,每個 User ID、每個 Query、 每個廣告都有特徵。同時為了個性化,User+Query、User+廣告 ID、Query+廣告 ID,甚至 User+Query+廣告 ID 都能產生特徵。通過組合,特徵會發生爆炸,原來可能上億的特徵會變成上千億特徵。
初聽這樣的思路會覺得有點奇怪,把使用者歷史上搜過關鍵詞或者看過廣告 ID 作為特徵,如果這個使用者從來沒有搜尋過這個關鍵詞或者沒有看過這個廣告,那是不是就不能獲取特徵了呢?這個問題正是 LR+大規模特徵這條路最常被攻擊的一點,即如何進行模型泛化。在大規模離散特徵機器學習系統裡,解決泛化的方法是設計加入層次化特徵,保證在細粒度特徵無法命中的時候,層次化的上位更粗粒度特徵可以生效。比方說如果一個使用者是一個新使用者的話,我們沒有 UserID 特徵,但是我們有更高層次的性別、地域、手機型號等特徵生效,在預估中起作用。回到說之前的例子中,我們設計「Query+UserID」特徵,到「Query」與「UserID」特徵,再到更高階的性別屬性「男/女」、使用的裝置「安卓/ iOS」,可以組成一個完成的特徵體系,無論缺失什麼都可以用更高階的特徵幫助預估進行彌補。
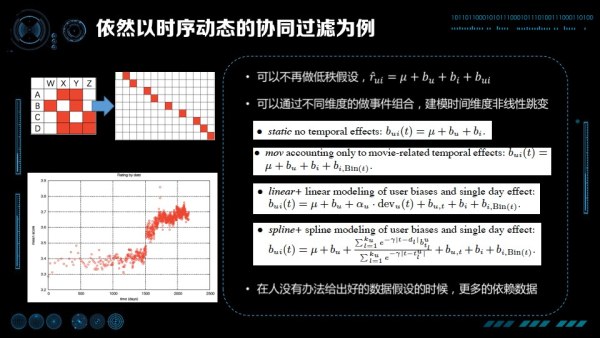
以之前提到的時序動態的協同過濾為例,我們看看如果走特徵這條路,該怎麼解決協同過濾的問題。首先我們不再做低秩假設,我們把所有的二階項可以展平成組合特徵。其次,我們會發現發現不是所有的資料都是呈線性的,特別有時候會產生一些突變,甚至都不能通過分段線性描述。還是在 Collaborative filtering with temporal dynamics 的論文中,由於作者也不知道什麼原因造成了突變,他的方法是把不同維度的資料與時間進行組合,對時間維度的非線性進行建模。加入 Item 把時間分成比較細的桶,做分段線性的擬合。同樣把 User 按時間進行分桶,保證對突變也能有比較好的擬合。
所以,當你不能給出比較好的資料假設時,不知道為什麼產生突變時,可以更多的依賴資料,用潛在引數建模可能性,通過資料學到該學的知識。
寬度還是深度?
大家都會比較好奇,沿著寬度走好還是沿著深度走好?並沒有那個模型在所有情況下都更好,換一句話說機器學習沒有免費的午餐(No Free-Lunch):不存在萬能模型。

No Free-Lunch Theory 是由 Wolpert 和 Macready 在 95 年提出的一個定理。他們證明對於任意演算法或優化演算法 A 與 B,如果在某一種損失函式上 A 好於 B,則一定存在另一個損失函式保證 B 好於 A。更直觀的描述是,總能找出一個損失函式讓任何演算法都不比隨機猜更好。
這告訴了我們什麼?所有的機器學習都是一個偏置,這個偏置是代表你對於資料的假設,偏置本身不會有誰比誰更好這樣的概念。如果使用更多的模型假設,就需要更少的資料,但如果模型本身越不符合真實分佈,風險就越大。當然我們也可以使用更少的模型假設,用資料支援模型,但你需要更多的資料支援,更好的特徵刻畫,然後表示出分佈。總結起來對於我們工業界來說,機器學習並沒有免費的午餐,一定要做出對業務合適的選擇。
寬與深的大戰
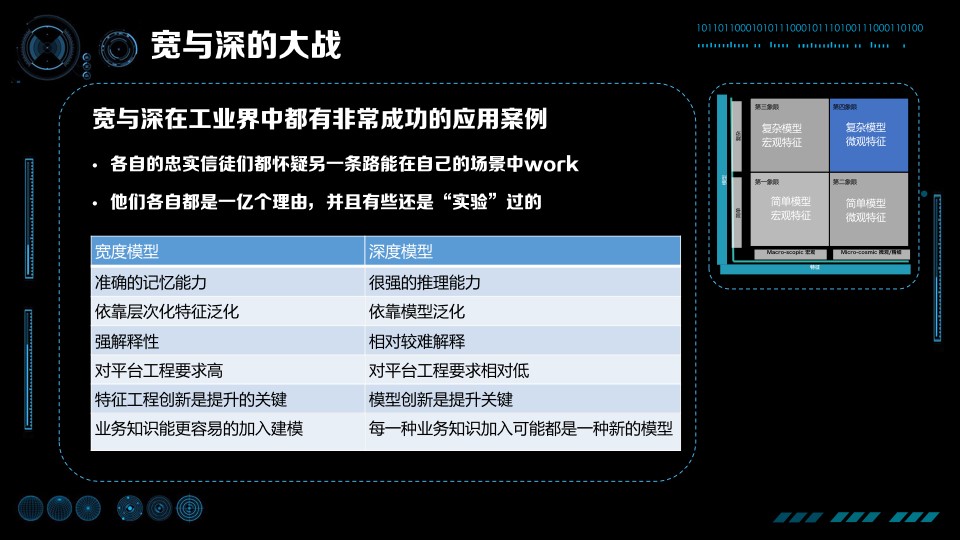
追求更高的 VC 維有兩條路:一個是走寬的、離散的那條路,即 Google AdWords 的道路;也可以走深的那條路,比如深度學習或者 YAHOO!News 那條路。這就是深與寬的大戰,因為寬與深在工業界都有非常成功的應用案例,堅信寬與深的人很長一段時間是並不互相理解的,各自忠實的信徒和粉絲們都會去擁護自己堅信的演算法,質疑另一條路走不通。堅信深度學習、複雜模型的人認為,寬的道路模型太簡單了,20 年就把所有的理論研究透徹,沒有什麼更多的創新,這樣的技術不可能在複雜問題上得到好的結果。堅信寬的模型的人,攻擊深度模型在某些問題上從來沒有真正把所有的資料都用好,從來沒有發揮出資料全部的價值,沒有真正的做到特別細緻的個性化。的確深度模型推理做得好,但個性化、記憶方面差很多。
非常有幸的是,我自己在寬和深兩邊都在工業界做過實際的探索與研究。吳恩達還沒正式加盟來百度之前,曾到百度訪問交流,當時我在鳳巢,有機會與他探討機器學習在工業界的一些進展與嘗試。在那時我們就發現在工業界中,寬與深有很強融合趨勢。Google 作為寬度模型的發起者,正在在廣告上嘗試使用深度模型,而我在百度也在已經做了同樣的事,不謀而合,Google 和百度這些寬模型的擁護者正在向深的方向走。同時吳恩達分享他在 Facebook 交流的時候,發現 Facebook 走的是複雜模型巨集觀特徵,雖然效果不錯,但也非常急切的想要嘗試怎樣使用更寬的模型,對廣告與推薦進行建模。
寬與深的模型並沒有誰比誰好,這就是免費午餐定理:不同業務使用不同的模型,不同的模型有不同的特點。我們對比一下寬度模型與深度模型:寬度模型有比較準確的記憶能力,深度模型有比較強的推理能力;寬度模型可以說出你的歷史,在什麼情況下點過什麼廣告,深度模型會推理出下次你可能喜歡哪一類東西。寬度模型是依靠層次化特徵進行泛化的,有很強的解釋性,雖說特徵很多,但是每一個預估、為什麼有這樣的預估、原因是什麼,可以非常好的解釋出來;深度模型是非常難以解釋的,你很難知道為什麼給出這樣的預估。寬度模型對平臺、對工程要求非常高,需要訓練資料非常多、特徵非常多;深度模型對訓練資料、對整個模型要求相對較低一點,但現在也是越來越高的。還有一個非常關鍵的區別點,如果你是 CEO、CTO,你想建一個機器學習的系統與團隊,這兩條路有非常大的區別。寬度模型可以比較方便與統一的加入業務知識,所以優化寬度模型的人是懂機器學習並且偏業務的人員,把專業的知識加入建模,其中特徵工程本身的創新是提升的關鍵;如果走深度模型,模型的創新是關鍵,提升模型更關鍵來自於做 Machine Learning 的人,他們從業務獲得知識並且得到一些假設,然後把假設加入模型之中進行嘗試。
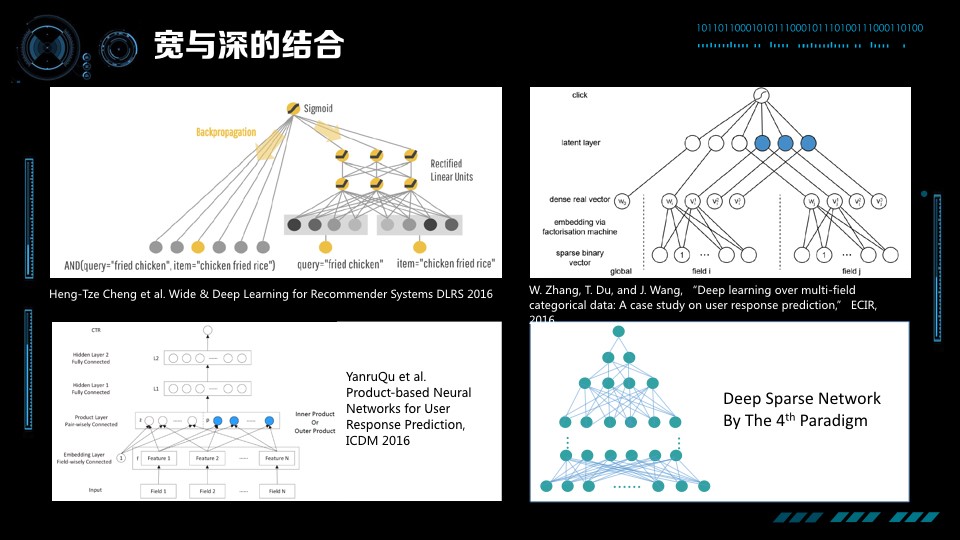
寬度和深度的大戰,就我看來各自都有各自的缺點,我們要各取所長做寬與深的結合。寬與深的結合已經逐漸成為一個研究熱點,Google 在今年 4 月份發表的一篇論文,介紹他們的最新工作「Deep & Wide Model」。模型分為 Deep 與 Wide 兩部分,好處是它既能對比較細的特徵有記憶,同時也有推理的能力。我們認為將來的方向都應該朝這路走。
除此之外,近期還有不少工作在探索這個方向,張偉楠 2016 年 ECIR 發表論文論述如何通過底層輸入加上因子分解機讓一個稀疏矩陣的深度學習可解,隨後在 ICDM 上發表論文進一步加入 Inner Product 和 Outer Product 希望更好的刻畫特徵之間的關係。第四正規化最近也有一些新進展,今年 7 月我們釋出了 DSN 演算法,演算法底層是上千億大小的寬度網路,上層是一個全連線的網路。難點在於如何解決它的可計算性以及如何解決模型的分散式,如何保持模型的稀疏與避免過擬合。總的來說這方面還是非常前沿的、非常熱門的研究領域。
如何上線:從監督學習到強化學習
不管是寬也好、深也好、又寬又深也好,有這麼多厲害模型,是不是歡歡喜喜搞好模型、做好特徵,線下評估 AUC 漲了,我們就趕快上線?不要高興太早,線下做好的模型實際上是一個監督學習模型,並不能保證它線上效果好。

以搜尋廣告為例,上圖中最左邊表示的是原系統對廣告進行排序產生的結果,線上系統展示 6 條廣告,還有一些是沒有被展示的廣告。展示的廣告中有被點選的廣告(黃色)和沒被點選的廣告(藍色)。我們使用展示過的廣告研發下一代機器學習模型,如上圖中間所示,優化之後發現被點選的廣告線下預估得點選率更高,位置向上提升,沒有被點選的廣告位置向下變化。但是真正的應用到線上的時候(上如最右邊所示),面對的侯選廣告不止是它展示出來的廣告,而是所有的廣告。可能之前根本就沒被原系統排上來的廣告被排到了非常高的位置,這些廣告可能很多根本就不會被點選。這樣以來,展示過的廣告雖然保持了原來的順序,但是中間插入了很多不會被點選、原來沒被排上的廣告,佔用廣告展示位,使得系統 AUC 很差。
這裡說一下我當年在百度搜索廣告上線深度學習的的故事。那時百度鳳巢還是在使用大規模離散 LR 系統,上千億的個性化的特徵讓廣告效果有長足的進步,剛獲得百度最高獎。而這個時候,我是在這個 LR 系統的基礎上,嘗試使用深度學習的技術進一步提升效果。怎麼讓一個上千億特徵的寬度系統變身深度系統在但是還是一個沒被研究過非常困難的問題,我們花了大半年的時間歷經千辛萬苦線上下獲得了非常顯著的指標提升,歡天喜地的想要上線,但剛一上線,我們就發現,線下模型訓練的越好,線上獲得的效果反而越差。這使我們當時非常沮喪,找了很久原因,定位到發現不是模型不對,也不是深度、寬度的問題,而是監督學習的問題——線上系統並不是問題封閉的監督學習系統,而是開放的不斷變化的系統。這就好比你去學打《星際爭霸》,不能通過頂級玩家的錄影來學,因為學到套路並不一定能打敗初級玩家,而必須以賽代練,自己上手,才可以把學到的知識真的用起來,面對變化的現實世界。
回過來看,如何上線其實是從監督學習到強化學習的問題。強化學習一般是閉環系統,系統裡會不斷的有外部反饋,這個反饋又是由系統產生的輸出帶來的結果。那如何更好的用系統輸出產生的結果進行強化學習?強化學習面臨的空間是一個未知空間,在 PPT 的廣告的例子中,可以看到的空間是原系統產生出來的空間(只有黃、藍色廣告),但是線上面對的空間其實是黃、藍加上綠這些廣告構成的空間。怎麼更好的探索黃、藍、綠的空間,是強化學習要解決的問題。有很多工作在嘗試解決這方面的問題,包括多臂老虎機、UCB 等等很多演算法,最近這些強化學習技術也被用到了搜尋廣告與推薦系統。總結起來,一定不要開心的太早,線上系統越強資料越有偏,學習越有偏的資料取得的效果,越不能代表上線的效果。
拆解複雜目標到單一目標,逐個優化
有這麼多好的技術,怎麼更好的服務業務?機器學習做的是單目標優化問題,並沒有能做多目標優化的機器學習演算法。雖然有研究在做嘗試,但在工業界還處於研究的初步階段。在真正出現多目標機器學習演算法之前,我們要更多的解決單目標優化的問題。

比方說新聞推薦就是一個多目標複雜的問題,想要優化的指標極多——我們想優化留存、想優化時長、想優化點選率、想優化轉發、想減少低俗、想優化時效性、想加速新使用者冷啟動等等,只優化某一個目標並不能讓我們一勞永逸。那這裡回想到以前有一個做推薦的朋友就因此特別的苦惱,因為每天面對這麼多的要考慮的因素,每天都在自己跟自己左右互搏,非常的分裂。他在優化點選率時就很擔心,是不是變低俗了?優化低俗的時候是不是降低了使用者的參與?優化參與時又想閱讀時長是不是會受到影響?但是,如果一心想一次優化所有的目標,那麼沒有一個目標最終能被優化。機器學習解決問題的套路是通過把目標分解,逐個進行優化。
舉搜尋廣告的例子,搜尋廣告的收入可以拆解成:流量 * 有廣告展示的流量比例 (asr) * 平均頁面廣告展示條數 (asn) * 點選率 (ctr) * 廣告平均計費價格 (acp)。拆解成這麼多目標後,優化點選率時就不用考慮其他的因素,點選率用模型優化,價格、條數用競價機制優化,流量通過產品與渠道優化。把目標拆開後可以非常舒服的優化每一項,每一項都優化得非常極致,整個系統就能做到極致了。再舉一個停留時長的例子。如果我們想優化閱讀的整體停留時長,並不是去按照直觀優化每個頁面的停留時常,而是將停留時長分解成點選率 * 點選後頁面停留時長,然後分開進行優化。
如果進行了合理的拆解,我們實際上可以有更多基礎模型,利用這些基礎模型,我們可以定義出針對業務目標的機制,比如說指數加權乘法或者逐級閾值門限機制等。利用設計好的機制,我們可以調整各個目標之間的關係,做出取捨,還可以定量的觀察與獲得指標間的兌換比例,比方說在模型不進行變化的前提下,多少點選率的降低能兌換出多少總時長的增加。應為每個指標都是獨立的,我們只需要用 ABTest 就可以根據公司目標調整這些機制引數了。這樣的方法相對於根據目標調整資料更能解釋清楚,調整資料是我把目標的拆解直接加到資料中,認為什麼目標重要就把那個目標對應的資料加倍、權重加倍。但困難在於加倍資料後模型需要重新訓練,也很難說清楚處於連續變化狀態中的目標,各個分指標是怎麼互換的。
關注人
最後分享一下我們在工業界應用中,關注人的一些經驗。關注人其實是一件我之前很少想的事情。如果你專注做機器學習,你可能認為與你交流的人、用你的技術的人或多或少懂得機器學習。但如果我們的目標是讓所有人都能用上人工智慧、讓工業界更多的產業用上人工智慧,你面對的人關於機器學習的水平參差不齊,就是一個非常現實的問題。在這樣的情況下,關注人在其中就是至關重要的事。
開頭提到的機器學習成功必要條件的五點中,專家數量是機器學習成功的必要因素。困難之一是在更廣闊的工業界,專家教授並沒有那麼多,企業內部需要優化的業務數量也遠遠大於專家數量。第二是非專業 AI 人員在無法理解(至少巨集觀上、直觀上理解)模型原理之前,他們是不相信模型能夠更好的優化他的業務的。比如你要把司機替換成自動駕駛,會發現人有非常非常多的顧慮,因為人不知道為什麼機器會做出左右、前後、剎車的判斷,也不知道背後的機器學習會在什麼時候失效、什麼時候能應用。這些問題在當前的技術前提下都是很難被直接定義、描述清楚的,那麼這就會導致人工智慧很難被推廣到更大的領域中。

如果要讓更多的人能使用上這樣的技術,首先是要解決模型的可解釋性。對應研究中的下一代技術叫 XAI(Explainable Artificial Intelligence),是一個更易理解的、更可解釋的 AI 系統。XAI 是 DARPA 今年的 6 月份提出的專案,被美國認為是攸關國家安全高度的人工智慧的技術。
模型的可解釋非常有用,更好的可解釋性、可理解性可以把人工智慧演算法或技術推廣到更多公司、以及推廣到公司其他部門,否則會碰到很多不同層面的問題。模型的可解釋有很多研究方向,做圖片分類時通過深度學習給出一個 Output,說圖片是貓的概率是 0.93。這會令人疑惑,圖片中的確是一隻貓,但並不知道為什麼機器認為它是一隻貓。將來的學習過程可能是,圖片放進來不僅會給出一個結果說它是貓,還會給出它是一隻貓的原因——兩個毛茸茸的耳朵、還有爪子、腳上還有很多毛、還有小肉墊,因此認為它是貓。這樣能更好的理解模型能做什麼、不能做什麼,這是應用人工智慧至關重要的點。
要解決可解釋性的問題,我們可以有多個思路,第一個思路是對於重要的模型,我們針對性的設計解釋機制。比方說考慮如何去解釋一個大規模特徵 LR 模型的問題,雖然 LR 模型天生是個解釋性很好的模型,但是特徵特別多的情況下,由於它是微觀模型,並不容易看到模型整體。就像觀察全國 14 億人每個人的行為,我們可以瞭解很多事情的發生,但是這還是不夠的的,我們需要從微觀特徵中得到巨集觀的統計和巨集觀的分析。這條思路其他重要的工作包括如何視覺化以及解釋深度學習的內部機制。第二個思路是我們也可以設計出一些全新的模型,這些模型最重要的設計目標就是在高可解釋性的同時不丟失預測效果。最後一個思路是做模型的黑箱推理,不管是深度模型、寬度模型或者其他模型,通過黑盒的輸入輸出來窺探模型內部的執行機制。
除了模型可解釋,在實際應用中,模型可控也是非常重要的一點。越重要的領域對模型可控的要求越強,因為不能出錯。推薦和廣告出錯一次沒什麼問題,如果貸款判斷失誤或是無人駕駛判斷失誤,後果可能會關係到國計民生。為什麼模型可控是一個難的問題呢?因為剛才說到模型要好 VC 維就一定要高、一定要有足夠的自由度,但可控是要限制解空間的自由度,讓模型滿足很多規則與約束。這就相當於想要造一個超音速的飛行器,但同時要求能用繩子牽著像風箏一樣被控制方向。這方面,我們也在進行探索,針對具體的問題,比方說定價,我們可以設計出一些既滿足規則、VC 維又足夠高的模型。
最後一點,模型的互動性、可干預性、可參與性。機器學習更多的是通過觀歷史預測未來,如果是歷史上沒有發生過的事情,還是需要通過專家更好的預測。一方面我們不能把人全部替掉,另一方面人在人工智慧時代可以產生更重要的作用。怎樣設計一個模型把專家的知識加進來,在資料不夠充分的時候更相信專家,有了足夠的積累就更相信資料和事實,是非常重要研究的話題。
Take-Home Message
最後,總結一下這次分享,有這麼幾個關鍵資訊:
- 第一點, 我們要設計一個開放的可擴充套件的機器學習系統。它一定需要是高 VC 維的系統,才能保證隨著業務增長,效率與效果也不斷提升。
- 第二點, 沒有免費的午餐,也沒有萬能的模型。
- 第三點, 寬度模型和深度模型各有利弊,根據場景、根據團隊選擇最合適你的。
第四點, 模型從線下走到線上其實是強化學習的過程,你(和你的老闆)最好做好半年抗戰的準備。這個時間不是指寫演算法、做工程的時間,而是做強化學習、不斷的迭代積累資料,讓模型越來越好的時間。這點非常重要,否則新的模型很難用到實際的工作中。無數死於襁褓的模型都是慘遭缺乏強化學習之痛。 - 第五點, 關注業務,設定更專注的目標解決更寬泛的問題。不要妄想一個機器學習模型能解決所有問題,要解決所有的問題就設計更多的模型,用機制讓這些模型共同工作。
- 第六點, 關注產品和業務人員,因為他們會最終決定 AI 能使用的深度和寬度。
今天我的分享就到這裡。謝謝大家!
問答環節
聽眾:第四正規化的 Deep Sparse Networks 適合解決什麼問題?
陳雨強:解決既要求資料有很強的離散性或很強的個性化,同時又要求有很強的推理的問題。Deep Sparse Networks 能從更細的角度能把特徵進行組合,挖掘出特徵之間不同的關係,個性化的推薦、廣告、排序,包括要做預估的場景都是 Deep Sparse Networks 適合的。
聽眾:第四正規化的商業模式是什麼,是給這些中小型企業提供人工智慧服務,還是給大公司提供服務?大企業可能都有自己的團隊,那第四正規化是做一個平臺性的工具,還是將來也做產品?要一直做送水人,還是跟 BAT 這種傳統網際網路去結合?
陳雨強:我覺得最關鍵一點是,BAT 解決的問題和各行各業要解決的 AI 問題並不一樣。各行各業都有使用 AI 的需求,我們的商業模式是提供一個 AI 的平臺,讓客戶有 AI 的能力、讓客戶自己使用人工智慧。
我們最近開放的公有云上,面對的目標客戶是有很高的人工智慧質量訴求,但是現在並沒有能力建立這樣的團隊的公司,諸如一些網際網路公司,他們的發展目標也是關注在業務上的。另外一方面,我們會服務金融、保險、電信等領域的一些巨頭,他們其實有非常強烈的使用 AI 的場景和訴求,但在技術上沒有完全接軌最新的技術。通過平臺的方式,我們讓他們的人員用上最新的技術產生更好的價值。
能做的事情太多,並且 BAT 和其他科技公司沒有一家完全覆蓋這部分業務。大資料公司很多,真正讓大資料產生價值的公司很少,目前看還是相對不飽和的市場。
聽眾:我好奇的一點是,廣點通是一個機器系統嗎?投放的時候通過選擇年齡、性別這樣的標籤可以代替監督學習的部分嗎?以及,為了提升投放效果,是應該把它當成黑盒子去反覆測試嗎?
陳雨強:首先,廣點通是一個非常好的機器學習系統。第二,選擇年齡、性別能不能代替監督學習,這是兩個不同的概念。年齡、性別、地域是使用者畫像,選擇的標籤是可被驗證的、與產品最息息相關的。比如針對女性使用者的產品雖然男性使用者點選率會非常高,可你根本不希望任何男性點進來。所以這部分是點選率模型不能解決的問題,一定要經過 Targeting 解決。
還有一類是使用者畫像是並不必需的。比如來定義他喜歡車還是喜歡金融,這是一個很寬泛的概念,每家公司定義都不同。比方說高階客戶、低端客戶這樣的標籤,遊戲公司的高階客戶是每天玩 20 個小時遊戲的人,但金融公司的高階客戶很可能不是每天玩 20 小時遊戲的人,所以通用、含糊的標籤一般沒有特別大的意義。
第三,如何優化。我覺得 ABtest 是最好的方式,如果平臺支援,可以通過出價、通過組合觀察如何獲得最佳的 ROI,是現有比較有效的方法。如果說怎麼結合機器學習,可以把 ROI 與資料做一個結合,這樣更清楚哪些標籤或者哪些投放的關鍵詞更有可能獲得更高的 ROI。
聽眾:去年吳恩達寫了一篇文章叫「每個企業都需要一個首席智慧官」,第四正規化不在任何一個企業裡,但可能也起到一個智慧官的作用。對於怎麼把機器學習變成可解釋的東西,能和我們分享講一個具體的故事,或者跟企業打交道面臨需要解釋的困難嗎?
陳雨強:首席智慧官需要做的事情有很多,涉及到如何在公司發揮人工智慧的價值、推進人工智慧、讓人工智慧更好的被接受、對趨勢的判斷、對技術的理解以及平臺的搭建,還包括技術的推廣。
我們在某個比較大的國有股份制銀行做好了一個模型,僅用一個月的時間就讓某一個具體的業務提升了 60% 的收入,換算成錢一年是十幾億的收入。銀行就非常急想上線,但是需要讓我們解釋我們的模型為什麼能工作,為什麼比他們之前的演算法和模型好。我們模型其實是一個寬模型,有上億的特徵,特徵是可以一個一個拿出來看的,但是並不能瞭解模型為什麼起作用。我們設計了一個可解釋模型,用樹模型這個相對容易解釋的方式,你和我們的寬模型,讓客戶瞭解我們模型的背後在做什麼事情。同時業務人員看了我們的模型,也獲得一些啟發,幫他們找到了一些新的業務規律。這個模型最終一是被用來做可解釋模型,第二是用來做他們審計的模型,應對銀行的監管訴求。
聽眾:深度模型和寬度模型的選擇是應該發生在專案開始之前,還是以結果為導向,這兩個模型都會去做,最終實際效果哪個更好我選擇哪個模型?
陳雨強:這個問題在於選擇建設適合你的機器學習系統。比如說這個系統面對的是不斷變化的業務,寬度模型是非常好的能結合業務知識和專家意見的機制。如果是一個技術為主、模型為主的團隊,走深度這條路也是可以獲得非常大的提升的。說到底不只是技術選型的問題,還是管理、架構的問題。選擇什麼樣的路決定將來怎麼搭建團隊、怎麼獲得持續的提升,因為機器學習一定不是一次就能完成的,是不斷提升的。
聽眾:在模型角度出發,什麼情況下即使資料是非常充足的,我們也認為專家的意見更可靠?
陳雨強:如果資料比較充分,專家的意見又比較靠譜,它們兩個是高度一致的。專家更大的作用還是在於巨集觀上,可以非常容易的加入巨集觀的外部資訊。這些資訊如果計入模型相對會有滯後性,這是沒有辦法克服的,專家的及時性會更加好。
聽眾:假設資料的情況非常理想,在模型方面您會做哪些努力保證這個模型的可控性是最強的?
陳雨強:模型可控性不是所有的方方面面都被控制住,可控是模型達到的業務目標。舉用機器學習解決智慧定價的問題為例,對信用卡分期產品進行定價,3 期、6 期、9 期、12 期有不同的手續費,一個合理的假設或者一個正常的要求可控的規則是,期數越高單期手續費應該越低。如果機器學習解決這個問題,不能保證期數越高手續費就一定越低。
所以具體方法是什麼?先設計一個部分強可控的模型,控制它的單調性、一致性和引數範圍;另一部分不需要可控的引數,讓它自由的學習,通過這種方式來達到可控。
聽眾:過去人工智慧研究專家系統,現在深度學習和專家系統是不是能夠結合?
陳雨強:這方面研究還是挺活躍的,近期的馬爾科夫邏輯網把邏輯和神經網路在一起,還有在貝葉斯方法最近也相對更熱了一點。大家也意識到深度學習很難解釋,所以通過邏輯、推理、概率這種方式能得到更可解釋的模型。我們自己也在思考,怎樣能更好的把專家的知識結合進來。過去其實分兩塊,一塊就是說 KR(Knowledge Representation),一種就是做推理,現在有了深度學習、有了各種學習方向,可能會有更多的發展。