
神經網路框架
一、啟用函式
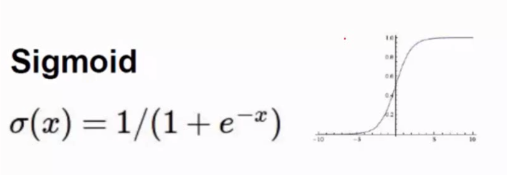
線性操作分類能力不強,而非線性表達可以分開資料。
神經網路中隱層就是增加了啟用函式,使得神經網路表達出更強大的效果。
Sigmoid可作為啟用函式,但容易引起梯度消失(導數趨近於0)。

max(0,x)就是ReLU啟用函式,可以解決梯度消失問題,導數簡單,已經常用的神經網路啟用函式。

(JavaScript可以寫網頁版的神經網路)
二、過擬合
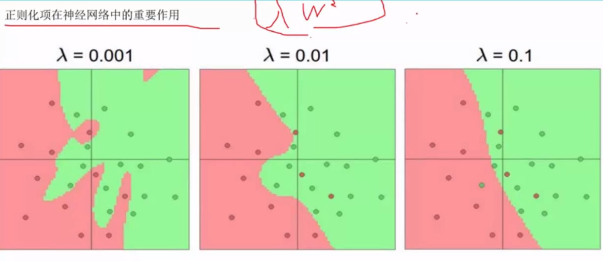
λ越小,過擬合越嚴重,把離群點作為單獨資料群擬合,λ調整至合適值,保證模型的泛化能力。
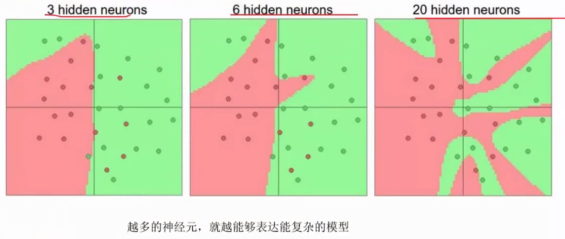
神經元越多,越能表達複雜模型,但也越容易出現過擬合降低模型泛化能力。
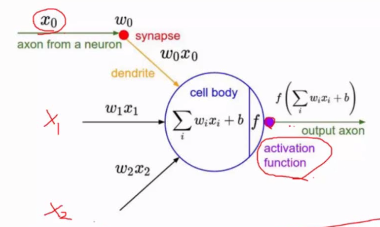
最後每一個操作都要經過啟用函式(activation function)作用,才能使最終結果產生非線性。
神經元就是權重引數w。
三、資料預處理
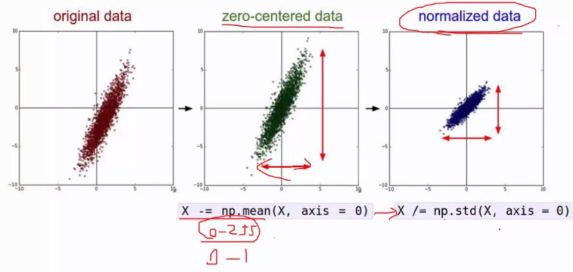
原始資料樣本都減去均值得到以0為中心化的資料,此時x、y軸浮動大小不一致,需要消除他們的差異,做歸一化,得到[0,1]範圍的資料。
四、權重初始化

一般採用高斯初始化或隨機初始化,常用隨機初始化。
b一般用0值初始化,也可以用1初始化。
五、DROP-OUT
每次隨機迭代,不是一次把所有的神經元進行迭代。可以降低過擬合風險。
一般訓練過程中出現過擬合是正常的,不出現反而可能是異常的。
相關推薦
神經網路框架
一、啟用函式 線性操作分類能力不強,而非線性表達可以分開資料。 神經網路中隱層就是增加了啟用函式,使得神經網路表達出更強大的效果。 Sigmoid可作為啟用函式,但容易引起梯度消失(導數趨近於0)。 max(0,x)就是ReLU啟用函式,可以解決梯度消失問題,導數簡單,已經常用
FINN(一)簡介一種快速,可擴充套件的二值化神經網路框架
摘要: 研究表明,卷積神經網路具有明顯的冗餘,即使權重和啟用從浮點減少到二進位制值,也可以獲得高分類精度。在本文中,我們介紹了FINN,一個使用靈活的異構流體系結構構建快速和靈活的FPGA加速器的框架。通過利用一組新的優化功能,可以實現二值化神經網路到硬體的高效
Torch7下搭建卷積神經網路框架
之前的博文,如一文讀懂卷積神經網路(CNN)、多層網路與反向傳播演算法詳解、感知機詳解、卷積神經網路詳解等已經比較詳細的講述了神經網路以及卷積神經網路的知識。本篇博文主要講述在Torch7中神經網路如何建立以及相關的原理(即神經網路包NN的內容),雖然講述的是神經網路的建
脈衝神經網路框架之bindsnet
當前脈衝神經網路的框架其實比較多,我之前用過PyNN+Nest,也用過下曼大的SpiNNaker,因為研究嘛,經常要修改學習演算法一些比較底層的東西,框架用起來實在是太麻煩,有時想改部分東西,發現別人都封裝好,不好改,所以就走上自己寫程式碼的不歸路。 一路走來,最大問題不是寫不出程式
分散式神經網路框架 CaffeOnSpark在AWS上的部署過程
一、介紹 Caffe 是一個高效的神經網路計算框架,可以充分利用系統的GPU資源進行平行計算,是一個強大的工具,在影象識別、語音識別、行為分類等不同領域都得到了廣泛應用。有關Caffe的更多內容請參考專案主頁: 不過Caffe的常用部署方式是單機的,這就意味
神經網路框架-Pytorch使用介紹
Pytorch上手使用 近期學習了另一個深度學習框架庫Pytorch,對學習進行一些總結,方便自己回顧。 Pytorch是torch的python版本,是由Facebook開源的神經網路框架。與Tensorflow的靜態計算圖不同,pytorch的計算圖
開源神經網路框架Caffe2全介紹
本文作者吳逸鳴,整理自作者在GTC China 2017大會上的演講,首發於作者的知乎文章。 我個人認為這是一份很值得分享的資料,因為 這應該是第一次使用全中文來講解Caffe2和FB的AI應用的演講 觀看這次演講不需要機器學習/神經網路,甚至電腦科學的基礎。它適合每一個願意瞭解人工智慧、神
用TensorFlow搭建一個萬能的神經網路框架(持續更新)
部落格作者:凌逆戰 部落格地址:https://www.cnblogs.com/LXP-Never/p/12774058.html 文章程式碼:https://github.com/LXP-Never/blog_data/tree/master/tensorflow_model 我一直覺得Ten
「開源」TensorSpace.js -- 神經網路3D視覺化框架,在瀏覽器端構建可互動模型
TensorSpace是一套用於構建神經網路3D視覺化應用的框架。 開發者可以使用類 Keras 風格的 TensorSpace API,輕鬆建立視覺化網路、載入神經網路模型並在瀏覽器中基於已載入的模型進行3D可互動呈現。 TensorSpace 可以使您更直觀地觀察神經網路模型,並瞭解該模型是如何通過
一種用迴歸神經網路學習說話人嵌入的無監督神經網路預測框架
An Unsupervised Neural Prediction Framework for Learning Speaker Embeddings using Recurrent Neural Networks 一種用迴歸神經網路學習說話人嵌入的無監督神經網路預測框架 摘要 本文提出
TensorSpace:一套用於構建神經網路3D視覺化應用的框架
作者 | syt123450、Chenhua Zhu、Yaoxing Liu (本文經原作者授權轉載) 今天要為大家推薦一套超酷炫的,用於構建神經網路 3D 視覺化應用的框架——TensorSpace。 有什麼用途? 大家可以使用類 Keras
《TensorFlow:實戰Google深度學習框架》——6.3 卷積神經網路常用結構
1、卷積層 圖6-8顯示了卷積層神經網路結構中重要的部分:濾波器(filter)或者核心(kernel)。 過濾器可以將當前層神經網路上的一個子節點矩陣轉化為下一層神經網路上的一個單位節點矩陣 。 單位節點矩陣指的是一個長和寬都為1,但深度不限的節點矩陣 。 在一個卷積層巾,過濾器
《TensorFlow:實戰Google深度學習框架》——6.2 卷積神經網路簡介(卷積神經網路的基本網路結構及其與全連線神經網路的差異)
下圖為全連線神經網路與卷積神經網路的結構對比圖: 由上圖來分析兩者的差異: 全連線神經網路與卷積網路相同點 &nb
《TensorFlow:實戰Google深度學習框架》——6.3 卷積神經網路常用結構(池化層)
池化層在兩個卷積層之間,可以有效的縮小矩陣的尺寸(也可以減小矩陣深度,但實踐中一般不會這樣使用),co。池從而減少最後全連線層中的引數。 池化層既可以加快計算速度也可以防止過度擬合問題的作用。 池化層也是通過一個類似過濾器結構完成的,計算方式有兩種: 最大池化層:採用最
TensorFlow+實戰Google深度學習框架學習筆記(12)------Mnist識別和卷積神經網路LeNet
一、卷積神經網路的簡述 卷積神經網路將一個影象變窄變長。原本【長和寬較大,高較小】變成【長和寬較小,高增加】 卷積過程需要用到卷積核【二維的滑動視窗】【過濾器】,每個卷積核由n*m(長*寬)個小格組成,每個小格都有自己的權重值, 長寬變窄:過濾器的長寬決定的 高度變高:過濾器的個數決定的 &nb
TensorFlow+實戰Google深度學習框架學習筆記(13)------Mnist識別和卷積神經網路AlexNet
一、AlexNet:共8層:5個卷積層(卷積+池化)、3個全連線層,輸出到softmax層,產生分類。 論文中lrn層推薦的引數:depth_radius = 4,bias = 1.0 , alpha = 0.001 / 9.0 , beta = 0.75 lrn現在僅在AlexNet中使用,
使用者畫像(2)使用keras框架搭建神經網路模型
import pickle import pandas as pd import tensorflow as tf import numpy as np import matplotlib.pyplot as plt from keras import back
改善深層神經網路——超引數除錯、Batch正則化和程式框架(7)
目錄 1.超引數除錯 深度神經網路需要除錯的超引數(Hyperparameters)較多,包括: α:學習因子 β:動量梯度下降因子 :Adam演算法引數 #layers:神經網路層數
java深度學習框架Deeplearning4j實戰(一)BP神經網路分類器
1、Deeplearning4j 深度學習,人工智慧今天已經成了IT界最流行的詞,而tensorflow,phython又是研究深度學習神經網路的熱門工具。tensorflow是google的出品,而phython又以簡練的語法,獨特的程式碼結構和語言特性為眾多資料科學家和
TensorFlow遊樂場及神經網路簡介,我以《Tensorflow:實戰Google深度學習框架》為主,基礎最重要
轉載:https://blog.csdn.net/broadview2006/article/details/80128755 本文將通過TensorFlow遊樂場來快速介紹神經網路的主要功能。TensorFlow遊樂場(http://playground.tensorflow.org)是一個通