
unity優化《一》
從DrawCall 到GC
一:首先優化從哪裡著手?
1.drawcall 是啥?就是CPU對底層圖形程式(如OpenGL ES)介面的呼叫,以在螢幕上畫出東西。
2.fragment是啥?經常有人說vf啥的,vertex我們都知道是頂點,那fragment呢?畫素是構成數碼影像 的基本單元,而fragment是有可能成為畫素的東西,意思就是不一定會被畫出來的潛在畫素。涉及 GPU.
3.batching是啥?批處理之前需要很多次呼叫(drawcall)的物體合併,之後只需呼叫一次底層圖形程式 的介面就行。
4.記憶體分配:除了unity自身,還有mono,還有託管,還有引入的dll。
二:影響CPU效率的因素。
1.DrawCall。
2.物理元件(Physics).
3.GC
4.程式碼質量
DrawCall是CPU呼叫底層圖形介面。比如有上千個物體,每一個的渲染都需要去呼叫一次底層介面,而每一次的呼叫CPU都需要做很多工作,
那麼CPU必然不堪重負。但是對於GPU來說,圖形處理的工作量是一樣的。所以對DrawCall的優化,主要就是為了儘量解放CPU在呼叫圖形介面上的
開銷。所以針對drawcall我們主要的思路就是每個物體儘量減少渲染次數,多個物體最好一起渲染。
動態批處理的約束:
- 批處理動態物體需要在每個頂點上進行一定的開銷,所以動態批處理僅支援小於900頂點的網格物體。
- 如果你的著色器使用頂點位置,法線和UV值三種屬性,那麼你只能批處理300頂點以下的物體;如果你的著色器需要使用頂點位置,法線,UV0,UV1和切向量,那你只能批處理180頂點以下的物體。
- 不要使用縮放。分別擁有縮放大小(1,1,1) 和(2,2,2)的兩個物體將不會進行批處理。
- 統一縮放的物體不會與非統一縮放的物體進行批處理。
- 使用縮放尺度(1,1,1) 和 (1,2,1)的兩個物體將不會進行批處理,但是使用縮放尺度(1,2,1) 和(1,3,1)的兩個物體將可以進行批處理。
- 使用不同材質的例項化物體(instance)將會導致批處理失敗。
- 擁有lightmap的物體含有額外(隱藏)的材質屬性,比如:lightmap的偏移和縮放係數等。所以,擁有lightmap的物體將不會進行批處理(除非他們指向lightmap的同一部分)。
- 多通道的shader會妨礙批處理操作。比如,幾乎unity中所有的著色器在前向渲染中都支援多個光源,併為它們有效地開闢多個通道。
- 預設體的例項會自動地使用相同的網格模型和材質。
所以,儘量使用靜態的批處理。
物理元件:
1.設定一個合適的Fixed Timestep。設定的位置如圖:
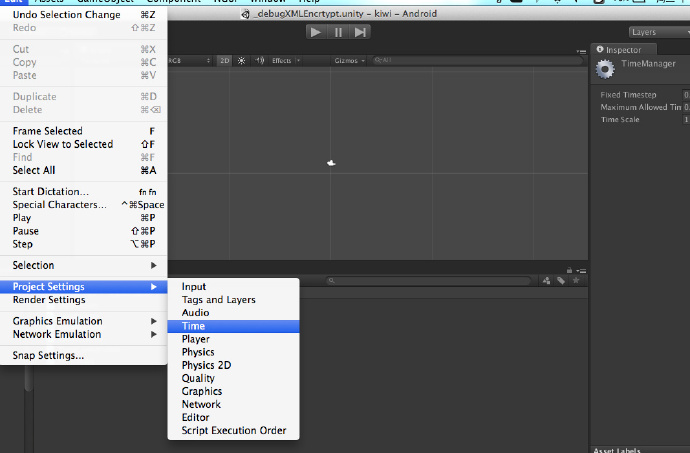
那何謂“合適”呢?首先我們要搞明白Fixed Timestep和物理元件的關係。物理元件,或者說遊戲中模擬各種物理效果的元件,最重要的是什麼呢?計算啊。對,需要通過計算才能將真實的物理效果展現在虛擬的遊戲中。那麼Fixed Timestep這貨就是和物理計算有關的啦。所以,若計算的頻率太高,自然會影響到CPU的開銷。同時,若計算頻率達不到遊戲設計時的要求,有會影響到功能的實現,所以如何抉擇需要各位具體分析,選擇一個合適的值。
2.就是不要使用網格碰撞器(mesh collider):為啥?因為實在是太複雜了。網格碰撞器利用一個網格資源並在其上構建碰撞器。對於複雜網狀模型上的碰撞檢測,它要比應用原型碰撞器精確的多。標記為凸起的(Convex )的網格碰撞器才能夠和其他網格碰撞器發生碰撞。各位上網搜一下mesh collider的圖片,自然就會明白了。我們的手機遊戲自然無需這種價效比不高的東西。
當然,從效能優化的角度考慮,物理元件能少用還是少用為好。
處理記憶體,卻讓CPU受傷的GC
在CPU的部分聊GC,感覺是不是怪怪的?其實小匹夫不這麼覺得,雖然GC是用來處理記憶體的,但的確增加的是CPU的開銷。因此它的確能達到釋放記憶體的效果,但代價更加沉重,會加重CPU的負擔,因此對於GC的優化目標就是儘量少的觸發GC。
首先我們要明確所謂的GC是Mono執行時的機制,而非unity3d遊戲引擎的機制,所以GC也主要是針對Mono的物件來說的,而它管理的也是Mono的託管堆。 搞清楚這一點,你也就明白了GC不是用來處理引擎的assets(紋理啦,音效啦等等)的記憶體釋放的,因為U3D引擎也有自己的記憶體堆而不是和Mono一起使用所謂的託管堆。
其次我們要搞清楚什麼東西會被分配到託管堆上?不錯咯,就是引用型別咯。比如類的例項,字串,陣列等等。而作為int,float,包括結構體struct其實都是值型別,它們會被分配在堆疊上而非堆上。所以我們關注的物件無外乎就是類例項,字串,陣列這些了。
那麼GC什麼時候會觸發呢?兩種情況:
- 首先當然是我們的堆的記憶體不足時,會自動呼叫GC。
- 其次呢,作為程式設計人員,我們自己也可以手動的呼叫GC。
所以為了達到優化CPU的目的,我們就不能頻繁的觸發GC。而上文也說了GC處理的是託管堆,而不是Unity3D引擎的那些資源,所以GC的優化說白了也就是程式碼的優化。那麼匹夫覺得有以下幾點是需要注意的:
- 字串連線的處理。因為將兩個字串連線的過程,其實是生成一個新的字串的過程。而之前的舊的字串自然而然就成為了垃圾。而作為引用型別的字串,其空間是在堆上分配的,被棄置的舊的字串的空間會被GC當做垃圾回收。
- 儘量不要使用foreach,而是使用for。foreach其實會涉及到迭代器的使用,而據傳說每一次迴圈所產生的迭代器會帶來24 Bytes的垃圾。那麼迴圈10次就是240Bytes。
- 不要直接訪問gameobject的tag屬性。比如if (go.tag == “human”)最好換成if (go.CompareTag (“human”))。因為訪問物體的tag屬性會在堆上額外的分配空間。如果在迴圈中這麼處理,留下的垃圾就可想而知了。
- 使用“池”,以實現空間的重複利用。
- 最好不用LINQ的命令,因為它們會分配臨時的空間,同樣也是GC收集的目標。而且我很討厭LINQ的一點就是它有可能在某些情況下無法很好的進行AOT編譯。比如“OrderBy”會生成內部的泛型類“OrderedEnumerable”。這在AOT編譯時是無法進行的,因為它只是在OrderBy的方法中才使用。所以如果你使用了OrderBy,那麼在IOS平臺上也許會報錯。
程式碼?指令碼?
聊到程式碼這個話題,也許有人會覺得匹夫多此一舉。因為程式碼質量因人而異,很難像上面提到的幾點,有一個明確的評判標準。也是,公寫公有理,婆寫婆有理。但是匹夫這裡要提到的所謂程式碼質量是基於一個前提的:Unity3D是用C++寫的,而我們的程式碼是用C#作為指令碼來寫的,那麼問題就來了~指令碼和底層的互動開銷是否需要考慮呢?也就是說,我們用Unity3D寫遊戲的“遊戲指令碼語言”,也就是C#是由mono執行時託管的。而功能是底層引擎的C++實現的,“遊戲指令碼”中的功能實現都離不開對底層程式碼的呼叫。那麼這部分的開銷,我們應該如何優化呢?
1.以物體的Transform元件為例,我們應該只訪問一次,之後就將它的引用保留,而非每次使用都去訪問。這裡有人做過一個小實驗,就是對比通過方法GetComponent<Transform>()獲取Transform元件, 通過MonoBehavor的transform屬性去取,以及保留引用之後再去訪問所需要的時間:
- GetComponent = 619ms
- Monobehaviour = 60ms
- CachedMB = 8ms
- Manual Cache = 3ms
2.如上所述,最好不要頻繁使用GetComponent,尤其是在迴圈中。
3.善於使用OnBecameVisible()和OnBecameVisible(),來控制物體的update()函式的執行以減少開銷。
4.使用內建的陣列,比如用Vector3.zero而不是new Vector(0, 0, 0);
5.對於方法的引數的優化:善於使用ref關鍵字。值型別的引數,是通過將實參的值複製到形參,來實現按值傳遞到方法,也就是我們通常說的按值傳遞。複製嘛,總會讓人感覺很笨重。比如Matrix4x4這樣比較複雜的值型別,如果直接複製一份新的,反而不如將值型別的引用傳遞給方法作為引數。
好啦,CPU的部分匹夫覺得到此就介紹的差不多了。下面就簡單聊聊其實匹夫並不是十分熟悉的部分,GPU的優化。
GPU的優化
GPU與CPU不同,所以側重點自然也不一樣。GPU的瓶頸主要存在在如下的方面:
- 填充率,可以簡單的理解為圖形處理單元每秒渲染的畫素數量。
- 畫素的複雜度,比如動態陰影,光照,複雜的shader等等
- 幾何體的複雜度(頂點數量)
- 當然還有GPU的視訊記憶體頻寬
那麼針對以上4點,其實仔細分析我們就可以發現,影響的GPU效能的無非就是2大方面,一方面是頂點數量過多,畫素計算過於複雜。另一方面就是GPU的視訊記憶體頻寬。那麼針鋒相對的兩方面舉措也就十分明顯了。
- 減少頂點數量,簡化計算複雜度。
- 壓縮圖片,以適應視訊記憶體頻寬。
減少繪製的數目
那麼第一個方面的優化也就是減少頂點數量,簡化複雜度,具體的舉措就總結如下了:
- 保持材質的數目儘可能少。這使得Unity更容易進行批處理。
- 使用紋理圖集(一張大貼圖裡包含了很多子貼圖)來代替一系列單獨的小貼圖。它們可以更快地被載入,具有很少的狀態轉換,而且批處理更友好。
- 如果使用了紋理圖集和共享材質,使用Renderer.sharedMaterial 來代替Renderer.material 。
- 使用光照紋理(lightmap)而非實時燈光。
- 使用LOD,好處就是對那些離得遠,看不清的物體的細節可以忽略。
- 遮擋剔除(Occlusion culling)
- 使用mobile版的shader。因為簡單。
優化視訊記憶體頻寬
第二個方向呢?壓縮圖片,減小視訊記憶體頻寬的壓力。
- OpenGL ES 2.0使用ETC1格式壓縮等等,在打包設定那裡都有。
- 使用mipmap。
MipMap
這裡匹夫要著重介紹一下MipMap到底是啥。因為有人說過MipMap會佔用記憶體呀,但為何又會優化視訊記憶體頻寬呢?那就不得不從MipMap是什麼開始聊起。一張圖其實就能解決這個疑問。

上面是一個mipmap 如何儲存的例子,左邊的主圖伴有一系列逐層縮小的備份小圖
是不是很一目瞭然呢?Mipmap中每一個層級的小圖都是主圖的一個特定比例的縮小細節的複製品。因為存了主圖和它的那些縮小的複製品,所以記憶體佔用會比之前大。但是為何又優化了視訊記憶體頻寬呢?因為可以根據實際情況,選擇適合的小圖來渲染。所以,雖然會消耗一些記憶體,但是為了圖片渲染的質量(比壓縮要好),這種方式也是推薦的。
記憶體的優化
既然要聊Unity3D執行時候的記憶體優化,那我們自然首先要知道Unity3D遊戲引擎是如何分配記憶體的。大概可以分成三大部分:
- Unity3D內部的記憶體
- Mono的託管記憶體
- 若干我們自己引入的DLL或者第三方DLL所需要的記憶體。
第3類不是我們關注的重點,所以接下來我們會分別來看一下Unity3D內部記憶體和Mono託管記憶體,最後還將分析一個官網上Assetbundle的案例來說明記憶體的管理。
Unity3D內部記憶體
Unity3D的內部記憶體都會存放一些什麼呢?各位想一想,除了用程式碼來驅動邏輯,一個遊戲還需要什麼呢?對,各種資源。所以簡單總結一下Unity3D內部記憶體存放的東西吧:
- 資源:紋理、網格、音訊等等
- GameObject和各種元件。
- 引擎內部邏輯需要的記憶體:渲染器,物理系統,粒子系統等等
Mono託管記憶體
因為我們的遊戲指令碼是用C#寫的,同時還要跨平臺,所以帶著一個Mono的託管環境顯然必須的。那麼Mono的託管記憶體自然就不得不放到記憶體的優化範疇中進行考慮。那麼我們所說的Mono託管記憶體中存放的東西和Unity3D內部記憶體中存放的東西究竟有何不同呢?其實Mono的記憶體分配就是很傳統的執行時記憶體的分配了:
- 值型別:int型啦,float型啦,結構體struct啦,bool啦之類的。它們都存放在堆疊上(注意額,不是堆所以不涉及GC)。
- 引用型別:其實可以狹義的理解為各種類的例項。比如遊戲指令碼中對遊戲引擎各種控制元件的封裝。其實很好理解,C#中肯定要有對應的類去對應遊戲引擎中的控制元件。那麼這部分就是C#中的封裝。由於是在堆上分配,所以會涉及到GC。
而Mono託管堆中的那些封裝的物件,除了在在Mono託管堆上分配封裝類例項化之後所需要的記憶體之外,還會牽扯到其背後對應的遊戲引擎內部控制元件在Unity3D內部記憶體上的分配。
舉一個例子:
一個在.cs指令碼中宣告的WWW型別的物件www,Mono會在Mono託管堆上為www分配它所需要的記憶體。同時,這個例項物件背後的所代表的引擎資源所需要的記憶體也需要被分配。
一個WWW例項背後的資源:
- 壓縮的檔案
- 解壓縮所需的快取
- 解壓縮之後的檔案
如圖:

那麼下面就舉一個AssetBundle的例子:
Assetbundle的記憶體處理
以下載Assetbundle為例子,聊一下記憶體的分配。匹夫從官網的手冊上找到了一個使用Assetbundle的情景如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
IEnumerator DownloadAndCache (){
// Wait for the Caching system to be ready
while
(!Caching.ready)
yield
return
|