
學習筆記之——基於深度學習的分類網路
之前博文介紹了基於深度學習的常用的檢測網路《學習筆記之——基於深度學習的目標檢測演算法》,本博文為常用的CNN分類卷積網路介紹,本博文的主要內容來自於R&C團隊的成員的調研報告以及本人的理解~如有不當之處,還請各位看客賜教哈~好,下面進入正題。
目錄
引言
卷積神經網路(CNN)又稱卷積網路,通常用做處理影象序列。經典的CNN層包括三個層次,卷積層、啟用函式和池化層。通常在輸出之前有幾個完全連線的層來整合資料並完成分類。本博文將介紹幾種經典的分類卷積網路:LeNet-5、AlexNet、ZFNet、VGGNet、GoogLeNet、ResNet。
分類網路
LeNet
LeNet-5由Yann LeCun等人於1989年提出,它是一種用於手寫體字元識別的非常高效的卷積神經網路,推動了深度學習領域的發展。LeNet5通過巧妙的設計,利用卷積、引數共享、池化等操作提取特徵,避免了大量的計算成本,最後再使用全連線神經網路進行分類識別,這個網路是卷積神經網路架構的起點,後續許多網路都以此為範本進行優化。
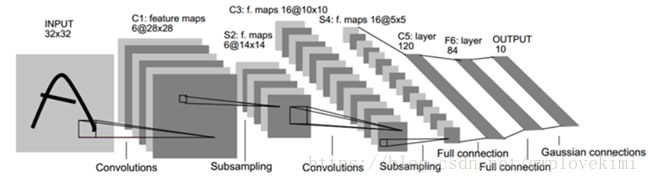
LeNet-5共有7層,不包含輸入,每層都包含可訓練引數;每個層有多個特徵對映(feature map
網路結構
INPUT層-輸入層:首先是資料 INPUT 層,輸入影象(0~9的手寫體數字)的尺寸統一歸一化為32*32,使背景級別(白色)對應-0.1,前景(黑色)對應1.175。這使得輸入平均值約為0,而方差約為1,目的是加速學習。32*32的影象大小比MNIST資料集的圖片要大一些,這麼做的原因是希望潛在的明顯特徵如筆畫斷點或角能夠出現在最高層特徵檢測子感受野(receptive field)的中心。因此在訓練整個網路之前,需要對28*28的影象加上paddings(即周圍填充0)。

C1層-卷積層
輸入圖片:32*32
卷積核大小:5*5
卷積核種類:6
輸出feature map大小:28*28
*注: 輸入維度n×n,卷積核大小f×f,填充p,步長s,則輸出維度為:
可訓練引數:(5*5+1) * 6(每個濾波器5*5=25個unit引數和一個bias引數,一共6個濾波器)
連線數:(5*5+1)*6*28*28=122304
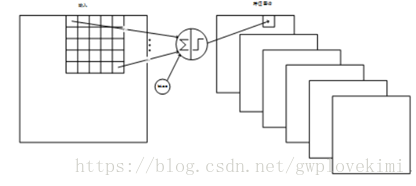
S2層-池化層(下采樣層)
輸入:28*28
取樣區域:2*2
取樣方式:4個輸入相加,乘以一個可訓練引數,再加上一個可訓練偏置。結果通過sigmoid。
*注:sigmoid函式:
取樣種類:6
輸出featureMap大小:14*14
連線數:(2*2+1)*6*14*14
S2中每個特徵圖的大小是C1中特徵圖大小的1/4。
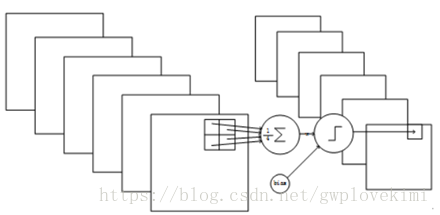
詳細說明:第一次卷積之後緊接著就是池化運算,分別對2*2大小的區域進行池化,於是得到了S2,6個14*14的特徵圖。S2這個pooling層是對C1中的2*2區域內的畫素求和並乘以一個權值係數再加上一個偏置,然後將這個結果再做一次對映。Pooling層的主要作用就是減少資料,降低資料維度的同時保留最重要的資訊。在資料減少後,可以減少神經網路的維度和計算量,也可以防止引數太多過擬合。
C3層-卷積層
輸入:S2的feature map組合
卷積核大小:5*5
卷積核種類:16
輸出featureMap大小:10*10
可訓練引數:6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516
連線數:10*10*1516=151600
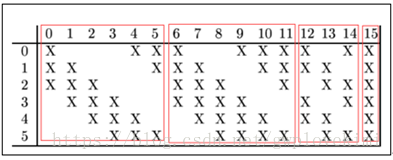
C3層是一個卷積層,卷積和和C1相同,卷積核大小依然為5*5,不同的是C3的每個節點與S2中的多個圖相連。每個圖與S2層的連線的方式如上表所示。這種不對稱的組合連線的方式有利於提取多種組合特徵。C3的前6個feature map(對應上圖第一個紅框的6列)與S2層相連的3個feature map相連線(上圖第一個紅框,每一列中X的數量為3),後面6個feature map與S2層相連的4個feature map相連線(上圖第二個紅框,每一列中X的數量為4),後面3個feature map與S2層部分不相連的4個feature map相連線,最後一個與S2層的所有feature map相連。總共有6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516個引數。而影象大小為10*10,所以共有151600個連線。
C3與S2中前3個圖相連的卷積結構如下圖所示:
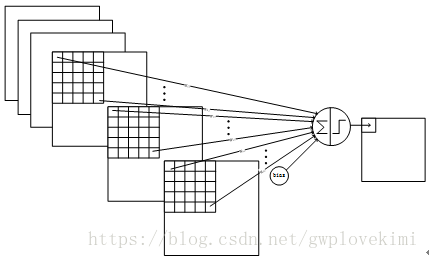
S4層-池化層(下采樣層)
輸入:10*10
取樣區域:2*2
取樣方式:4個輸入相加,乘以一個可訓練引數,再加上一個可訓練偏置。結果通過sigmoid
取樣種類:16
輸出featureMap大小:5*5
神經元數量:5*5*16=400
連線數:16*(2*2+1)*5*5=2000
S4中每個特徵圖的大小是C3中特徵圖大小的1/4
C5層-卷積層
輸入:S4層的全部16個單元特徵map(與S4全相連)
卷積核大小:5*5
卷積核種類:120
輸出featureMap大小:1*1
可訓練引數/連線:120*(16*5*5+1)=48120
詳細說明:C5層是一個卷積層。由於S4層的16個圖的大小為5×5,與卷積核的大小相同,所以卷積後形成的圖的大小為1×1。這裡形成120個卷積結果。每個都與上一層的16個圖相連。所以共有(5×5×16+1)×120 = 48120個引數,同樣有48120個連線。C5層的網路結構如下:
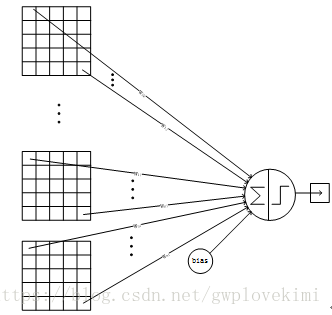
F6層-全連線層
輸入:C5層輸出的 120維向量
計算方式:計算輸入向量和權重向量之間的點積,再加上一個偏置,結果通過sigmoid函式輸出。
可訓練引數:84*(120+1)=10164
詳細說明:6層是全連線層。F6層有84個節點,對應於一個7×12的位元圖,-1表示白色,1表示黑色,這樣每個符號的位元圖的黑白色就對應於一個編碼。該層的訓練引數和連線數是(120 + 1)×84=10164。
F6層的連線方式如下:
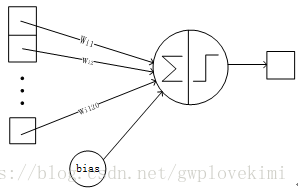
Output層-全連線層
Output層也是全連線層,共有10個節點,分別代表數字0到9,且如果節點i的值為0,則網路識別的結果是數字i。採用的是徑向基函式(RBF)的網路連線方式。假設x是上一層的輸入,y是RBF的輸出,則RBF輸出的計算方式是:
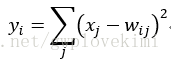
上式w_ij 的值由i的位元圖編碼確定,i從0到9,j取值從0到7*12-1。RBF輸出的值越接近於0,則越接近於i,即越接近於i的ASCII編碼圖,表示當前網路輸入的識別結果是字元i。該層有84×10=840個引數和連線。然後與Softmax連線,最終輸出結果。
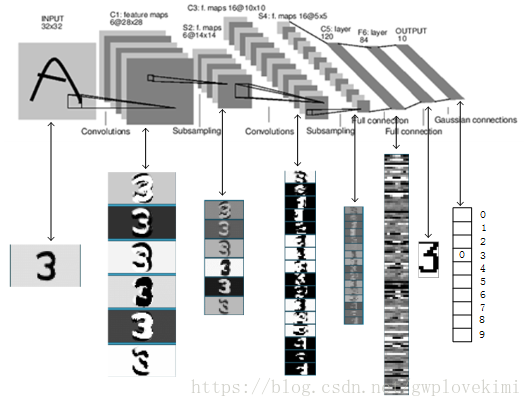
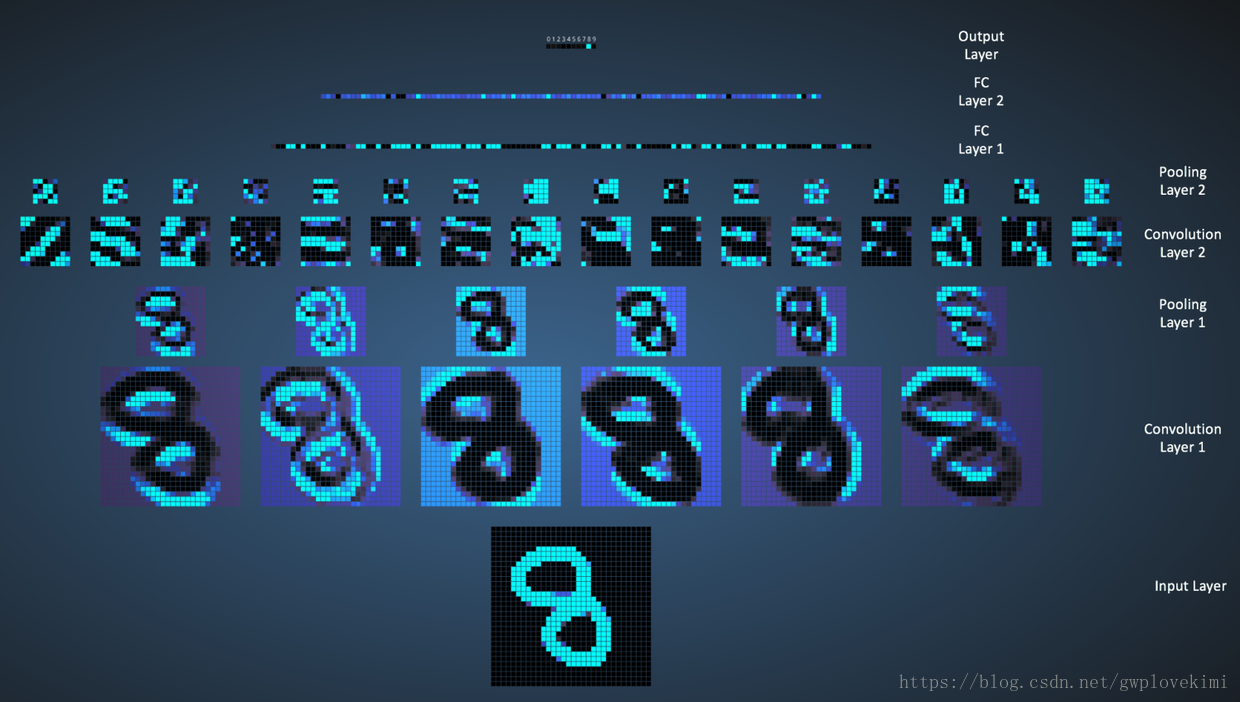
上圖是LeNet-5識別數字3的過程。下圖是LeNet-5識別數字8的過程。
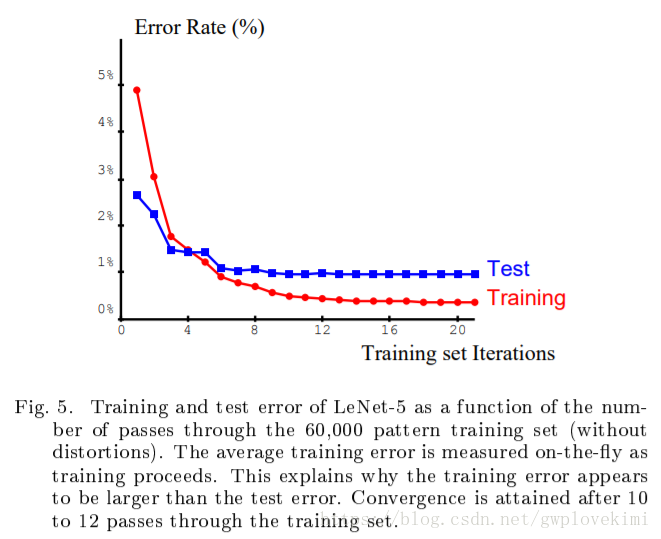
測試結果
在MNIST 中60000個訓練集上,誤差在第10~12次迭代時趨近收斂。
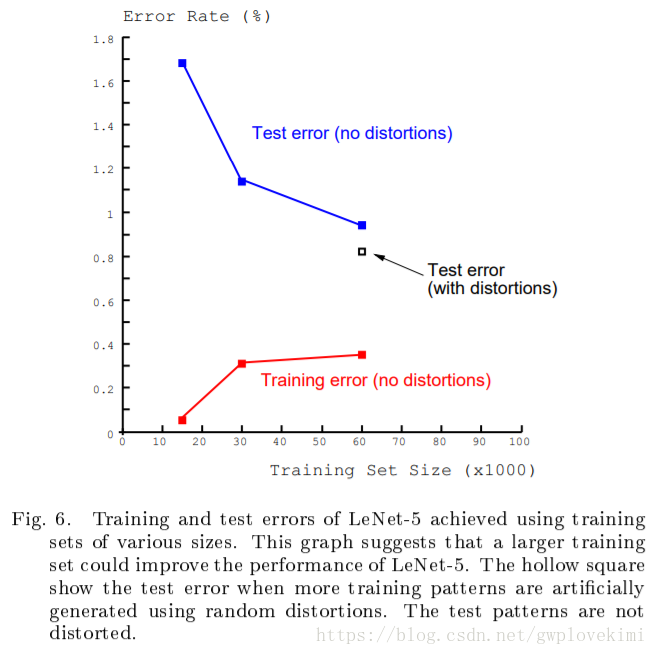
隨著訓練集的擴充,測試誤差在減小。在測試集經過人工隨機扭曲擴充套件的情況下,測試誤差達到了0.8%。
LeNet-5與其他分類演算法的分類錯誤率結果比較。
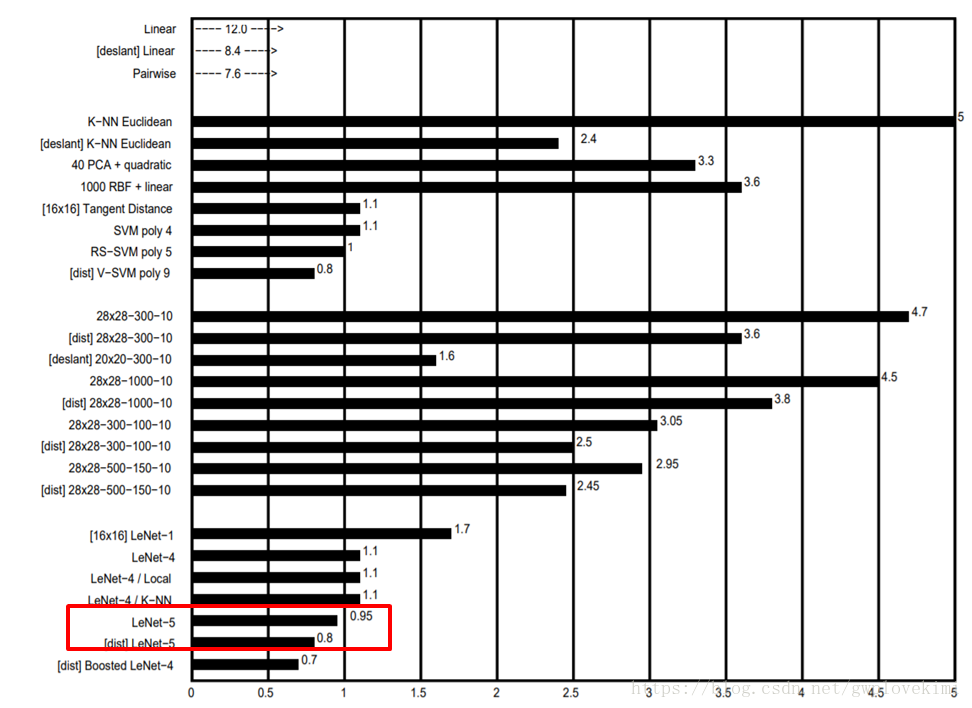
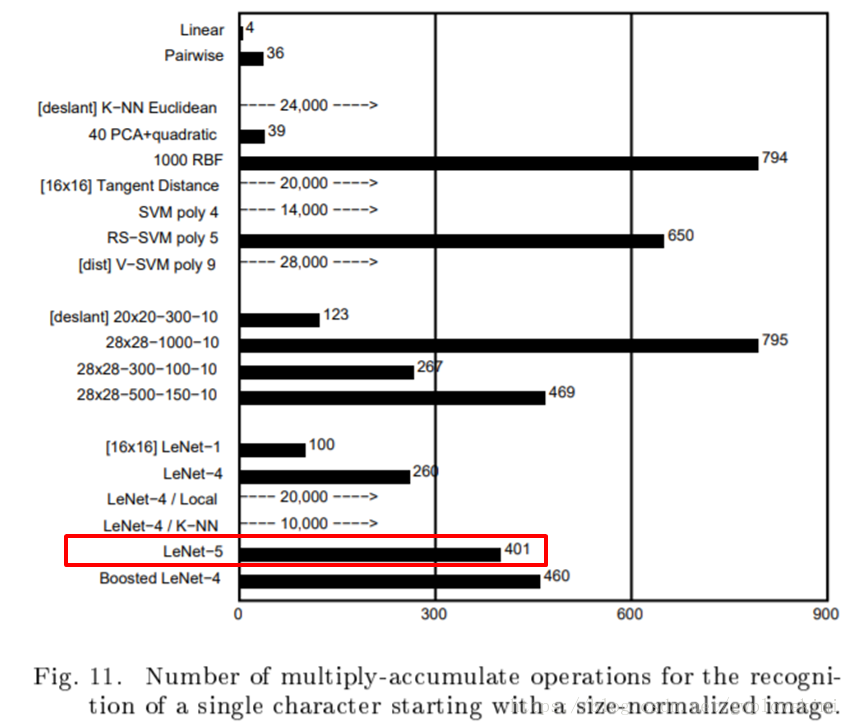
LeNet-5與其他分類演算法的所必需進行的累加乘法操作次數結果比較。
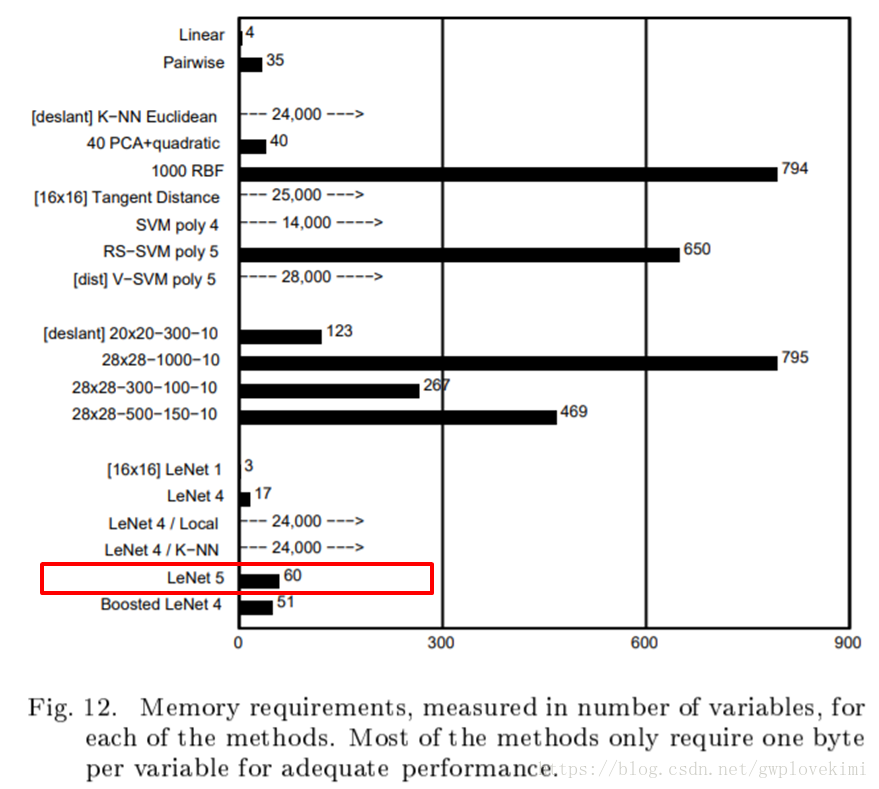
LeNet-5與其他分類演算法的必需儲存變數的空間大小結果比較。
總結
優點:
LeNet-5是一種用於手寫體字元識別的非常高效的卷積神經網路。
卷積神經網路能夠很好的利用影象的結構資訊。
卷積層的引數較少,這也是由卷積層的主要特性即區域性連線和共享權重所決定。
缺點:
由於當時缺乏大規模訓練資料,計算機的計算能力也跟不上,LeNet-5 對於複雜問題的處理結果並不理想,下圖為82個被LeNet-5誤判的數字影象,誤判原因主要為訓練集沒有表現以下數字的特徵。

意義:是第一個真正意義上的深度學習網路,也是現在許多卷積神經網路的雛形。在20世紀90年代,LeNet-5被用於歐美許多大銀行的自動手寫識別系統(讀取支票手寫數字等),為商業發展提供幫助。
AlexNet
2012年,Alex Krizhevsky、Ilya Sutskever設計出了一個深層的卷積神經網路AlexNet,奪得了2012年ImageNet LSVRC的冠軍,且準確率遠超第二名(top5錯誤率為15.3%,第二名為26.2%),引起了很大的轟動。AlexNet可以說是具有歷史意義的一個網路結構,在此之前,深度學習已經沉寂了很長時間,自2012年AlexNet誕生之後,後面的ImageNet冠軍都是用卷積神經網路(CNN)來做的,並且層次越來越深,使得CNN成為在影象識別分類的核心演算法模型,帶來了深度學習的大爆發。
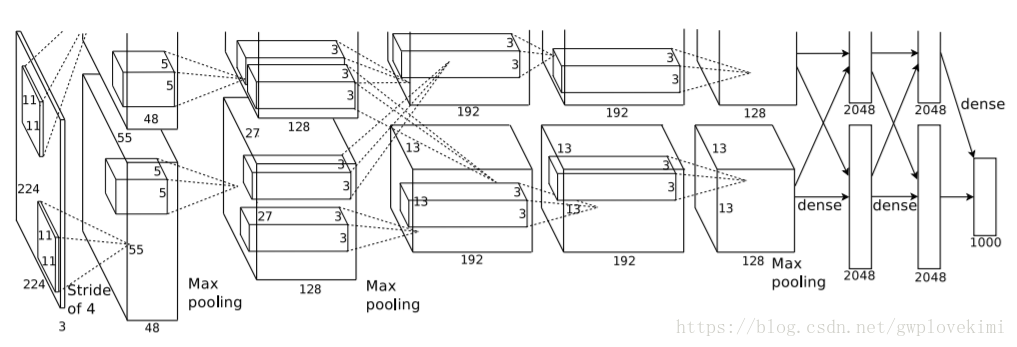
網路結構
AlexNet包括了8個引數層(不包括池化層和區域性響應歸一化LRN層),5層卷積層和3層全連線層,最後一個全連線層的輸出送到一個1000維的Softmax層,產生一個覆蓋1000類標籤的分佈。LRN層出現在第1個及第2個卷積層後,最大池化層(3*3,步長為2)出現在2個LRN層及最後一個卷積層後。ReLU啟用函式應用在這8層每一層後面。
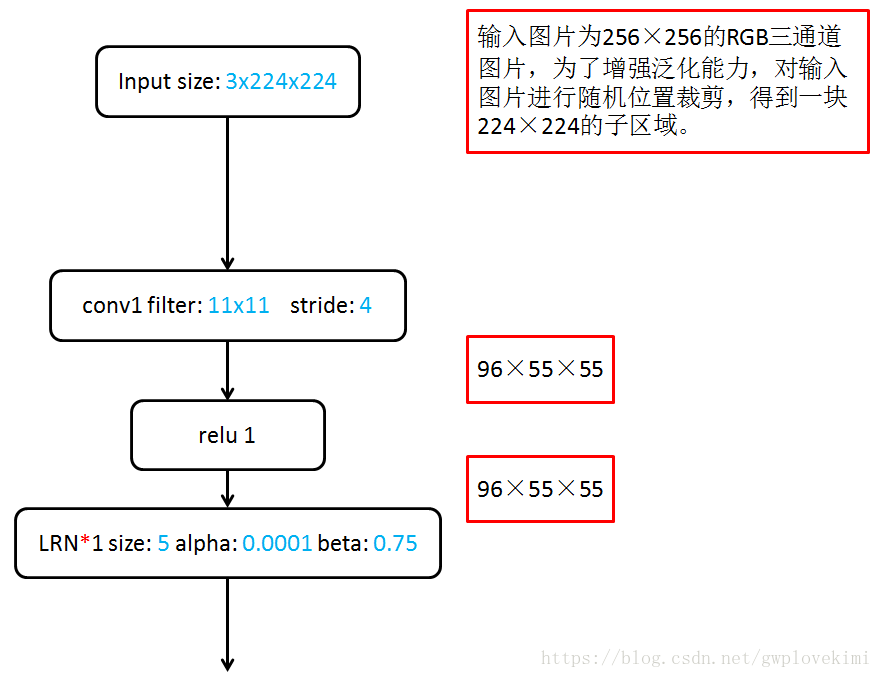
Local Response Normalization, LRN,區域性響應歸一化。指在某一層得到了多通道的響應圖後,對響應圖上某一位置和臨近通道的值按照如下公式做歸一化:
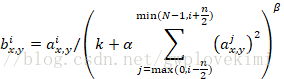
其中是特徵響應feature map圖第
個通道上在
位置上的值,k、α、β均為超引數(Alex選用的引數為
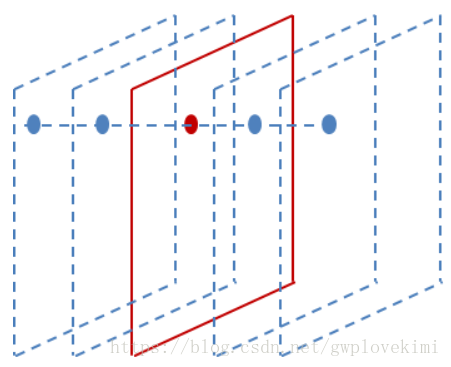
)區域性響應歸一化模擬的是動物神經中的橫向抑制效應。從公式中可看出,如果在該位置,該通道和臨近通道的絕對值都比較大的話,歸一化之後值會有變得更小的趨勢。LRN示意圖如下圖所示,紅色的feature map中特定的位置與其鄰近通道上的相同位置的值進行歸一化。
Alex等人提出LRN時指出其對網路分類指標的提升是有幫助的(top-1錯誤率下降1.4%,top-5錯誤率下降1.2%),然而隨著更深層次的網路被提出,LRN被認為並沒有什麼作用,論文Very Deep Convolutional Networks for Large-scale Image Recognition指出在VGGNet第11層的網路中LRN已經起了副作用。
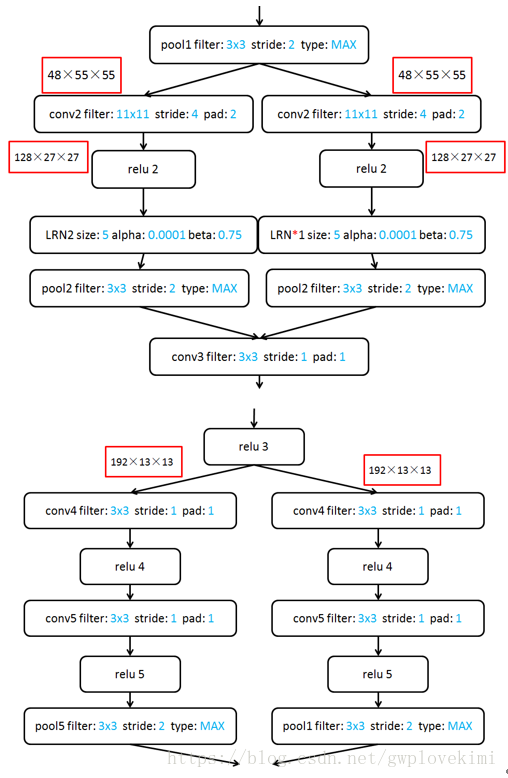
以上兩個分組卷積是因為Alex當時的顯示卡不夠強大,為了減少計算量同時方便並行,所以採用了同時在兩塊GPU上分組計算的方法。傳統的卷積層中,相鄰的池化單元是不重疊的。如果步長小於卷積核大小,那麼池化層將重疊。在AlexNet中使用了MAXPooling,步長為2,卷積核大小為3。論文指出,這種重疊的池化層能“稍微”減輕過擬合。
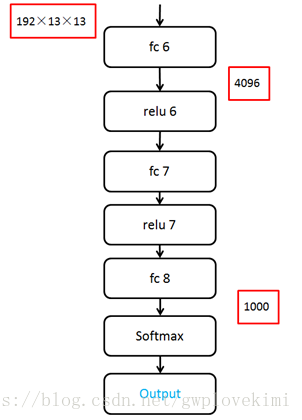
在fc6、fc7兩層,AlexNet使用了Dropout方法來避免過擬合。具體操作是每個神經元有50%的概率被設定為沒有響應,這使得對於每次訓練,神經網路的體系結構都會不同,使得網路更加健壯。

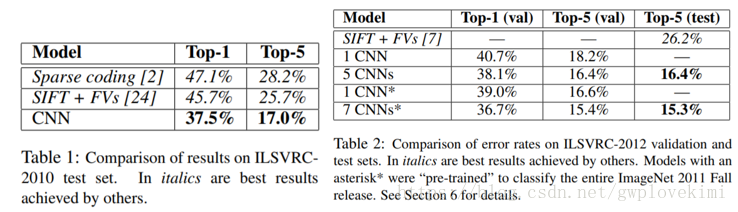
測試結果
網路特點
- 使用非線性啟用函式:ReLU
- 防止過擬合的方法:Dropout,Data augmentation
- 大資料訓練:百萬級ImageNet影象資料
- 其他:GPU實現,LRN歸一化層的使用
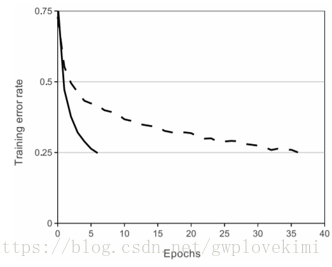
For 1: Sigmoid 是常用的非線性的啟用函式,它能夠把輸入的連續實值“壓縮”到0和1之間。特別的,如果是非常大的負數,那麼輸出就是0;如果是非常大的正數,輸出就是1。LeNet-5使用的啟用函式便是Sigmoid函式。然而,Sigmoid函式有兩個致命的缺點:1)當輸入非常大或者非常小的時候,會有飽和現象,這些神經元的梯度是接近於0的。如果初始值很大的話,梯度在反向傳播的時候因為需要乘上一個sigmoid 的導數,所以會使得梯度越來越小,這會導致網路變的很難學習。2)Sigmoid 的 輸出不是0均值。這是不可取的,因為這會導致後一層的神經元將得到上一層輸出的非0均值的訊號作為輸入。產生的一個結果就是:如果資料進入神經元的時候是正的,那麼計算出的梯度也會始終都是正的。Alex用ReLU代替了Sigmoid,發現使用 ReLU 得到的SGD的收斂速度會比sigmoid/tanh 快很多。如下圖,在 CIFAR-10測試集上,實線代表使用ReLU作為啟用函式的訓練誤差曲線,虛線代表使用tanh作為啟用函式的訓練誤差曲線,ReLU收斂速度遠快於tanh。主要是因為它是linear,而且 non-saturating(因為ReLU的導數始終是1),相比於sigmoid/tanh,ReLU 只需要一個閾值就可以得到啟用值,而不用去算一大堆複雜的運算。
For 2: 對原始圖片進行擴充以減少過擬合Data augmentation,方法有:從原始影象(256,256)中,隨機的裁剪出一些影象(224,224)。水平翻轉影象。給影象增加一些隨機的光照。
總結
優點:資料增強,採用了Dropout、Data augmentation避免過擬合,採用ReLU整流線性單元代替Sigmoid函式,第一次採用GPU加速,使得訓練網路的速度大大提高。在ILSVRC2012的比賽中取得了優異的成績。
意義:它證明了CNN在複雜模型下的有效性,然後利用GPU加速使得訓練在可接受的時間範圍內得到結果。AlexNet對幾年前的神經網路結構影響深遠,2013年ILVRC的冠軍結構ZFNet、亞軍結構VGGNet都是以AlexNet為基礎的。從這一年開始,幾乎所有參加ILVRC的參賽者都開始使用卷積神經網路,少數沒有使用深度卷積神經網路的參賽者都處於墊底位置。AlexNet的提出確實讓CNN和GPU的概念變得流行,且推動了監督學習的發展。
ZFNet
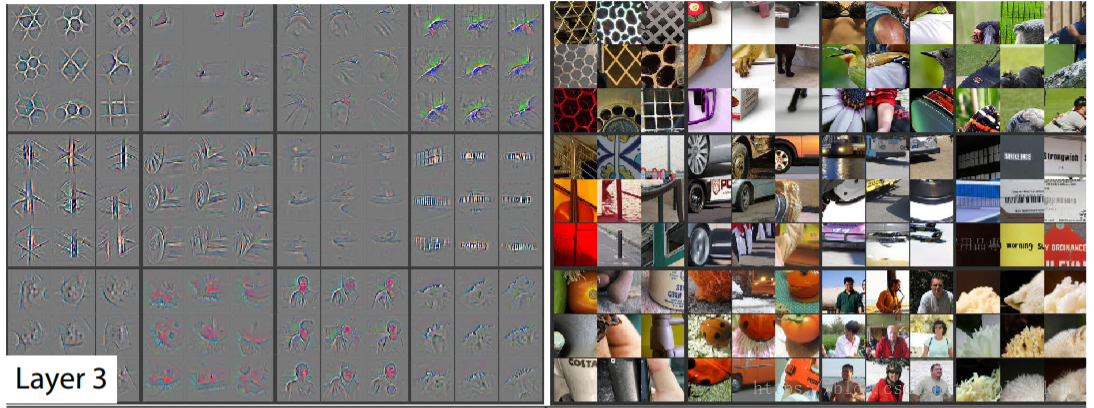
ZFNet是由紐約大學的Matthew Zeiler和Rob Fergus所設計,該網路在AlexNet上進行了微小的改進,但這篇文章主要貢獻在於在一定程度上解釋了卷積神經網路為什麼有效,以及如何提高網路的效能。該網路的貢獻在於:1)使用了反捲積網路,可視化了特徵圖。通過特徵圖證明了淺層網路學習到了影象的邊緣、顏色和紋理特徵,高層網路學習到了影象的抽象特徵;2)根據特徵視覺化,提出AlexNet第一個卷積層卷積核太大,導致提取到的特徵模糊;3)通過幾組遮擋實驗,對比分析找出了影象的關鍵部位;4)論證了更深的網路模型,具有更好的效能。
網路結構
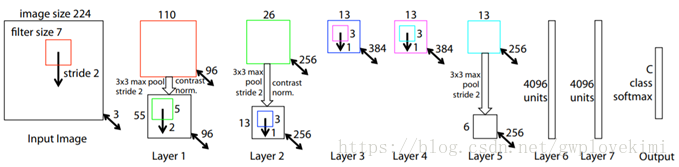
ZFNet大體保留了AlexNet的結構,而通過特徵視覺化發現了AlexNet的一些不足之處,對其中一些引數進行了調整:由於AlexNet第一層卷積核混雜了大量的高頻和低頻資訊,缺少中頻資訊,故ZFNet將第1層卷積核的大小由11×11調整為7×7;b、c分別為AlexNet、ZFNet第1層所提取的特徵。

由於AlexNet第2層卷積過程選擇4作為步長,產生了混亂無用的特徵,故ZFNet將卷積步長由4調整為2。d、e分別為AlexNet、ZFNet第2層所提取的特徵,後者沒有前者中的模糊特徵。

網路特點
反捲積網路Deconvnet:用於瞭解(視覺化)卷積網路中間層的feature map。在ZFNet中,卷積網路的每一層都附加了一個反捲積層,提供了一條由輸出feature map到輸入影象的反通路。首先,輸入影象通過卷積網路,每層都會產生特定feature map,而後將反捲積網路中觀測層的其他連線權值全部置零,將卷積網路觀測層產生的feature map當作輸入,傳送給對應的反捲積層,並依次進行i.unpooling,ii.矯正,iii.反捲積。
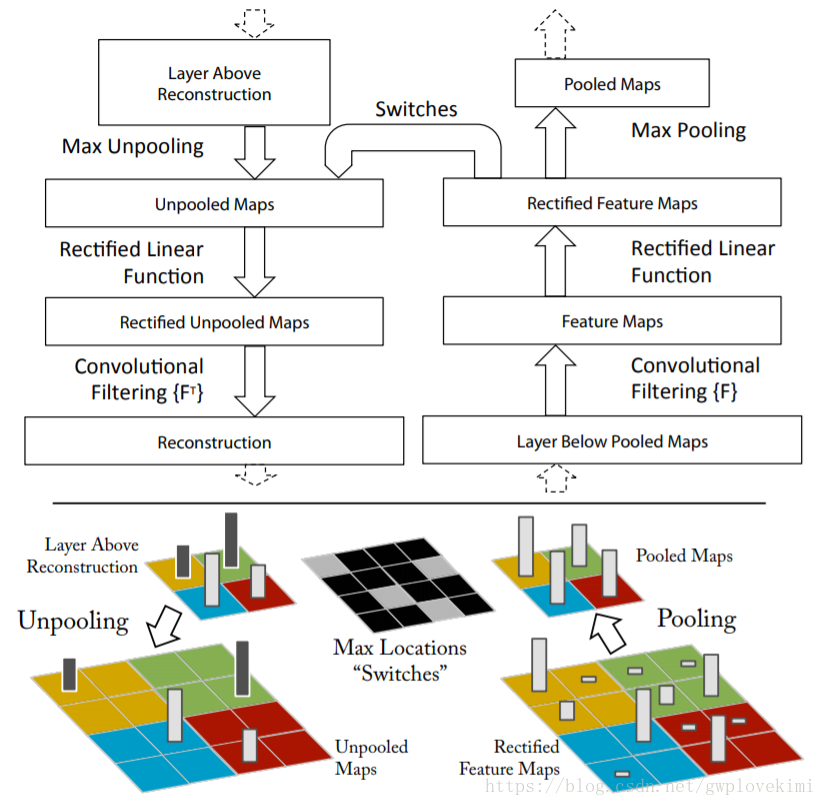
unpooling: 在MAXpooling的過程中,用Switches表格記錄下每個pooling區域中的最大值,在unpooling過程中,將最大值標註回記錄所在位置,其餘位置填充0。
矯正:在卷積網路中,使用ReLU作為啟用函式保證所有輸出都為非負數,這個約束對反捲積過程依然成立,因此將重構訊號同樣傳輸入ReLU中。
反捲積:卷積網路使用學習得到的卷積核與上層輸出feature map做卷積得到該層輸出的feature map,為了實現逆過程,反捲積網路使用相同卷積核的轉置作為核,與矯正後的feature map進行卷積運算。



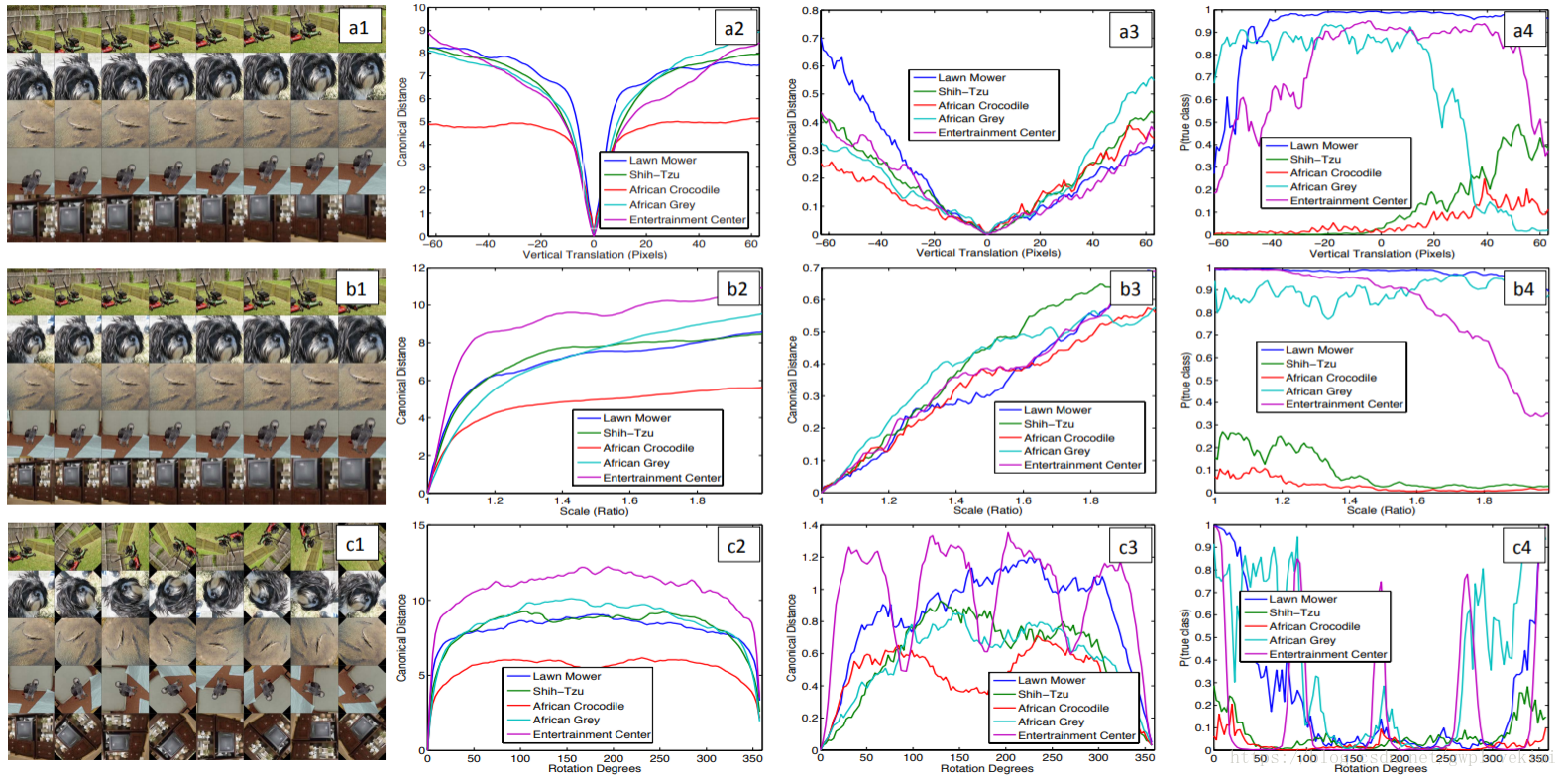
特徵不變性:如圖,5張不同的圖片分別被平移、旋轉、縮放。在網路的第1層,輸入圖片任何小的微變都會導致輸出特徵變化明顯,但隨著層數的增加,平移和縮放的變化對最終結果影響越小,但旋轉產生的變化並不會減小。這說明卷積網路無法對旋轉操作產生不變性,除非物體具有很強的對稱性。

遮擋實驗:
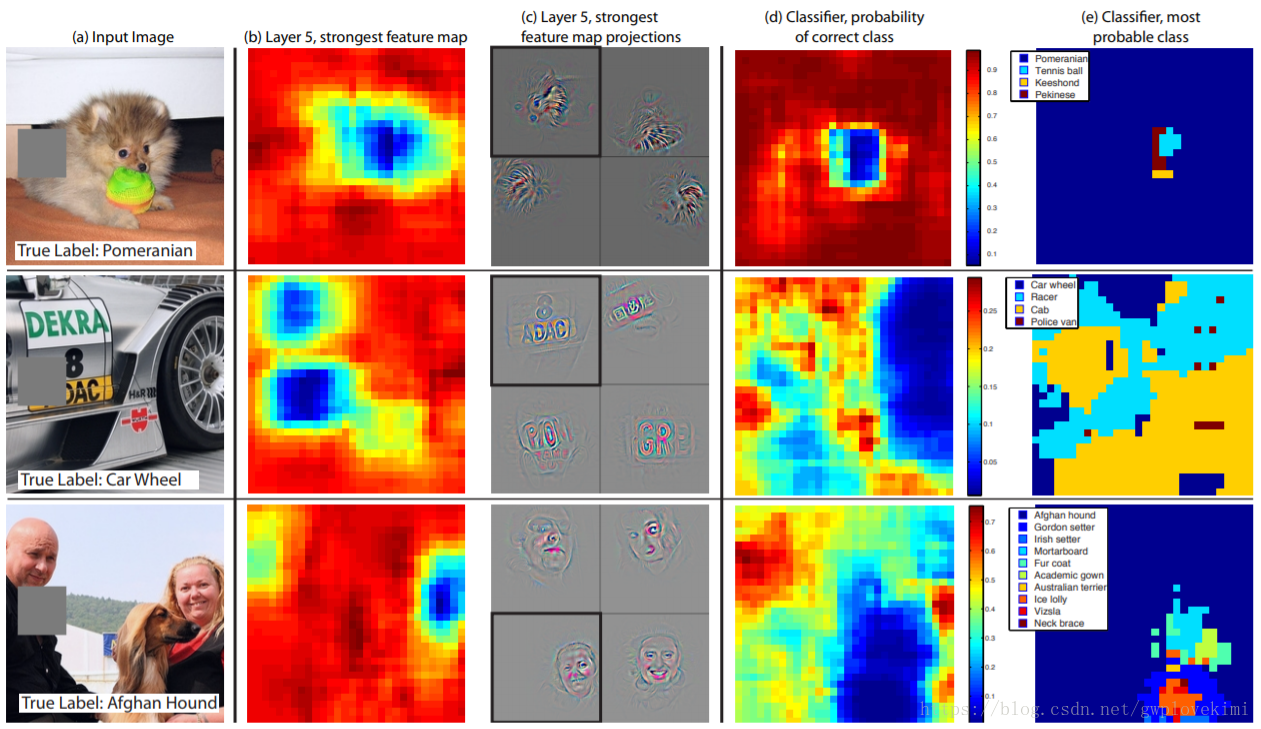
ZFNet展示了輸入圖片被遮擋的情況。Zeiler等人使用一個灰色矩形對輸入影象的每個部分進行遮擋,並測試在不同遮擋情況下,分類器的輸出結果,當關鍵區域發生遮擋時,分類器效能急劇下降。上圖中的第1行展示了狗狗圖片產生的最強特徵,當存在遮擋時,對應輸入圖片的特徵產生刺激強度降低(藍色區域)。使用部分遮擋的擴充套件訓練集可以使網路產生相關性,提升分類準確度。
訓練與測試結果
使用ImageNet2012所給的130萬張圖片進行測試,每張RGB影象被預處理為256×256的大小。ZFNet使用小批量資料SGD隨機梯度下降,mini-batch=128,學習率為10-2,動量為0.9。在第6、第7層全連線層中使用Dropout方法(Dropout比率為50%)

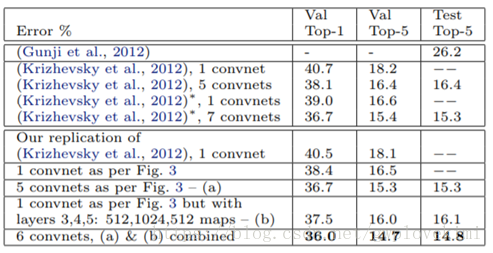
利用改進後的ZFNet在ImageNet2012訓練集上訓練並測試,得出的top-5錯誤率為14.8%,比AlexNet的15.3%下降了0.5%。
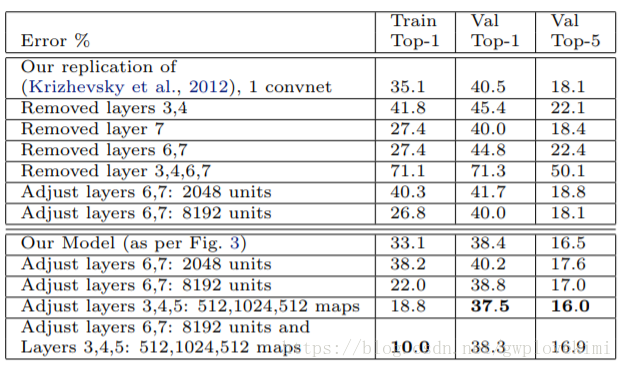
Zeiler等人測試了改變AlexNet模型的結構對最終分類結果所造成的影響。當第6、7層被完全刪除後,錯誤率上升至22.4%,而刪除所有的卷積層後,錯誤率劇烈上升至50.1%,這說明模型的深度與分類效果密切相關,深度越大,效果越好,而改變全連線層的節點個數對分類效能影響不大。
為了測試模型泛化能力,Zeiler等人還利用ZFNet測試了Caltch-101,Caltch-256和PASCAL VOC2012共3個庫,測試方法為不改變1~7層的訓練結果,而只對最深層的softmax分類器重新訓練。
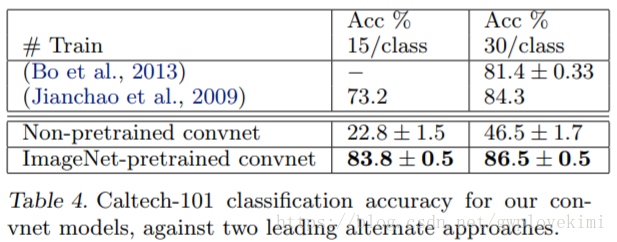
比較可知,基於ImageNet學到的特徵更有效。
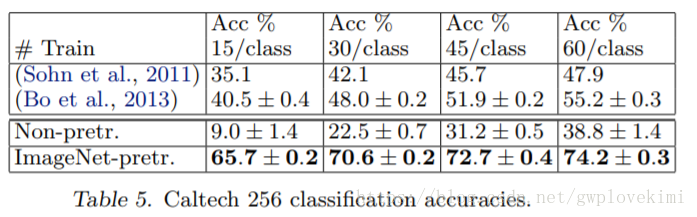
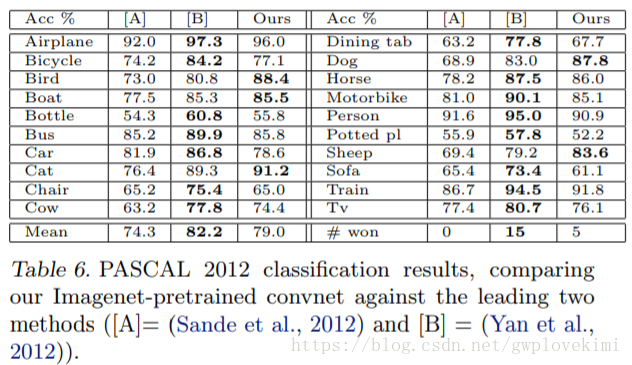
PASCAL庫中的測試圖片有可能一張包含多個物體,而ZFNet模型一張圖片只給出一個預測,所以沒能超越歷史最好記錄,約落後了3.2%。
通過以上實驗,說明使用ImageNet2012資料集訓練得到的CNN的特徵提取功能就有通用性。
總結
優點 / 意義:ZFNet是CNN領域視覺化理解的開山之作。在一定程度上解釋了卷積神經網路為什麼有效,以及如何提高網路的效能。
侷限:大體繼承了AlexNet的結構,沒有提出太多對提升分類準確度有實際幫助的方法。
VGGNet
VGGNet是由牛津大學計算機視覺組和Google DeepMind專案的研究員共同研發的卷積神經網路模型,VGGNet探索了卷積神經網路的深度與其效能之間的關係,通過反覆堆疊3*3的小型卷積核和2*2的最大池化層,VGGNet成功地構築了16~19層深的卷積神經網路。該模型取得了ILSVRC2014比賽分類專案的第2名和定位專案的第1名。
網路結構
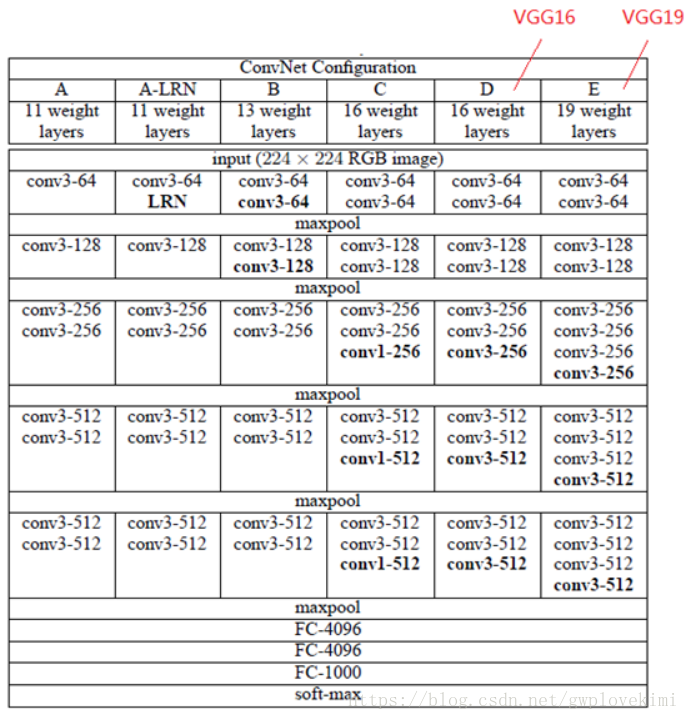
VGG由5層卷積層、3層全連線層、softmax輸出層構成,層與層之間使用max-pooling(最大化池)分開,所有隱層的啟用單元都採用ReLU函式。VGG16
在訓練期間,VGGNet的輸入是固定大小的224×224 RGB影象。預處理是從每個畫素中減去在訓練集上計算的RGB均值。影象通過一堆卷積層,VGGNet使用感受野很小的濾波器:3×3(這是捕獲左/右,上/下,中心概念的最小尺寸)。在其中一種配置中,我們還使用了1×1卷積濾波器,可以看作輸入通道的線性變換(後面是非線性)。卷積步長固定為1個畫素;卷積層輸入的空間填充要滿足卷積之後保留空間解析度,即3×3卷積層的填充為1個畫素。空間池化由五個最大池化層進行,這些層在一些卷積層之後(不是所有的卷積層之後都是最大池化)。在2×2畫素視窗上進行最大池化,步長為2。各層引數如下圖所示。

百萬級別
VGG16的模型圖如下:
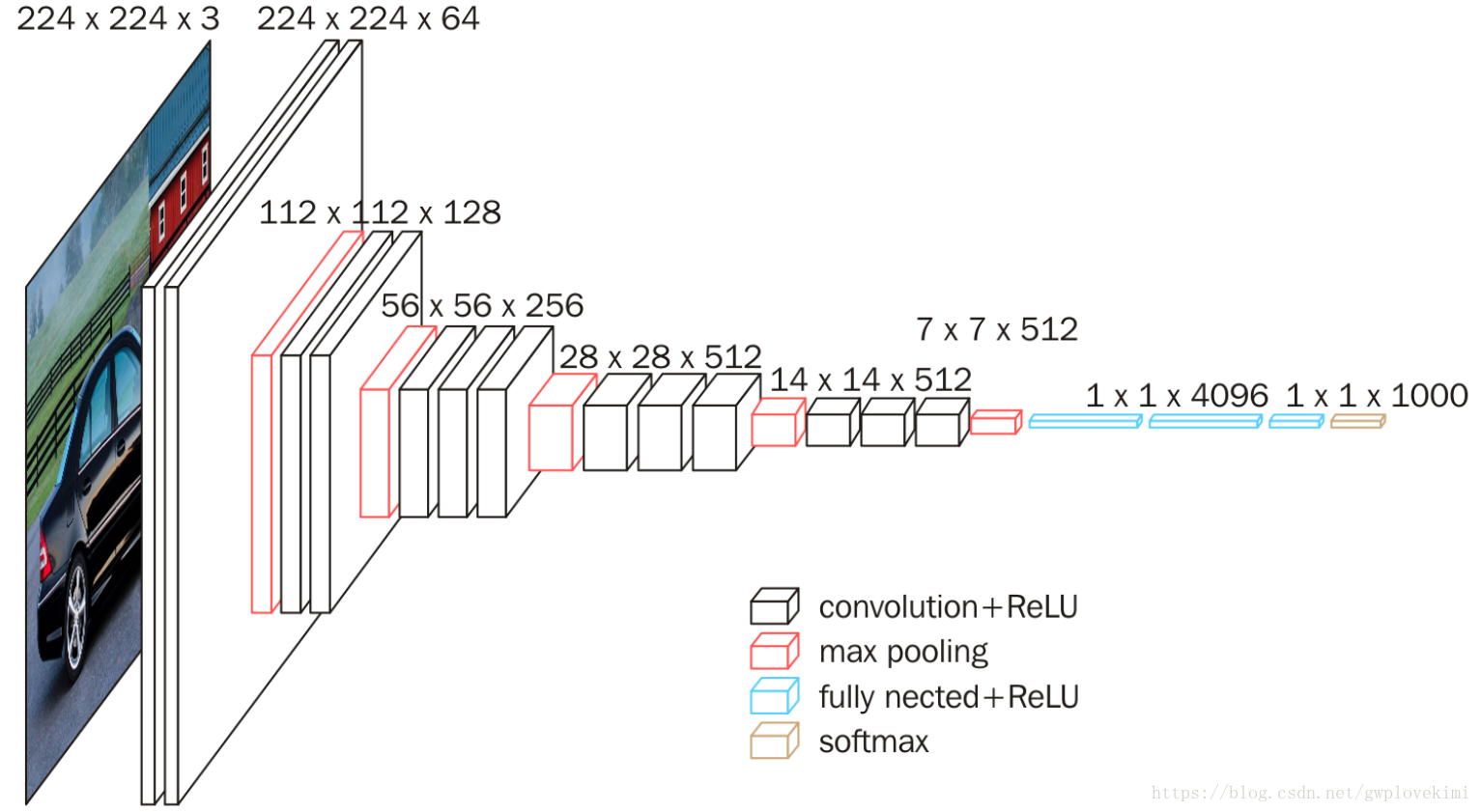
在卷積層(在不同架構中具有不同深度)之後是三個全連線(FC)層:前兩個每個都有4096個通道,第三個執行1000維ILSVRC分類,因此包含1000個通道(一個通道對應一個類別)。最後一層是softmax層。所有網路中全連線層的配置是相同的。
所有隱藏層都配備了ReLU。VGGNet網路(除了一個)都不包含區域性響應規範化(LRN)因為這種規範化並不能提高在ILSVRC資料集上的效能,但增加了記憶體消耗和計算時間。
網格特點
VGGNet將小卷積核帶入人們的視線,對比AlexNet中第一個卷積層使用的filter大小為11×11,stride為4,C3和C5層中使用的都是5×5的卷積核;而出現在VGGNet大多數的卷積核的大小均為 3×3,stride均為1。將卷積核的大小縮小的好處為1)減少引數,2)相當於進行了更多的非線性對映,可以增加網路的擬合/表達能力。
For 1: 假設三層3×3卷積堆疊的輸入和輸出有C個通道,堆疊卷積層的引數為3(32C2)=27C2個權重;然而,單個7×7卷積層將需要72C2=49C2個引數,即引數多81%。這可以看作是對7×7卷積濾波器進行正則化,迫使它們通過3×3濾波器(在它們之間注入非線性)進行分解。
For 2: 多少個串聯的小卷積核就對應著多少次啟用的過程,而一個大的卷積核就只有一次啟用的過程。引入了更多的非線性變換,也就意味著模型的表達能力會更強,可以去擬合更高維的分佈。
VGG網路的通道數比AlexNet網路的通道數多,第一層的通道數為64,後面每層都進行了翻倍,最多到512個通道,通道數的增加,使得更多的資訊可以被提取出來。
VGG結合1×1卷積層來替換輸出前的3個全連線層,以增加決策函式非線性而不影響卷積層的感受野。這使得測試得到的全卷積網路因為沒有全連線的限制,因而可以接收任意寬或高的輸入。VGGNet使用1×1卷積來在相同維度空間上做線性投影(輸入和輸出通道的數量相同),再由修正函式對結果非線性化。
訓練與測試結果
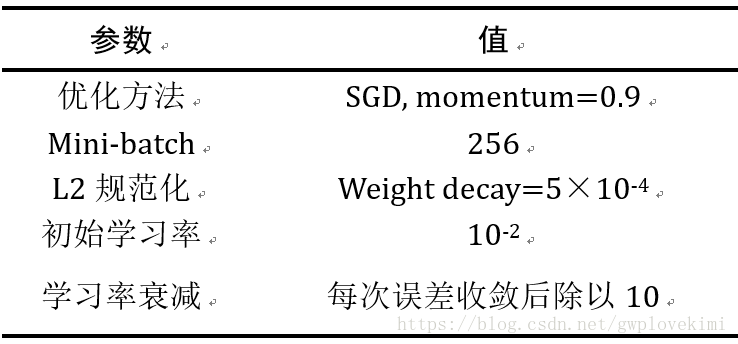
通過使用具有動量的小批量(mini-batch)梯度下降優化多項式邏輯迴歸目標函式來進行訓練。批量大小設為256,動量為0.9。訓練通過權重衰減進行L2正則化(weight decay=5×10-4),前兩個全連線層使用Dropout方法(Dropout比率設定為0.5)。學習率初始設定為10−2,然後當驗證集準確率停止改善時,減少10倍。學習率總共降低3次,學習在37萬次迭代後停止(74個epochs)。
S定義為歸一化訓練影象的最小邊(訓練尺度),VGGNet的輸入是從S影象中裁剪得到的。VGGNet訓練影象大小的方式有兩種,一是修正對應單尺度訓練的S,VGGNet針對S=256和S=384進行測試(S=384時使用的是S=256時訓練的權重,學習率調整為10-3),二是進行多尺度訓練,每個訓練影象通過從一定範圍(分別為256、512)隨機取樣S來單獨進行歸一化。這種過程也可以看做通過尺度抖動使資料集增強。
單一尺度評估結果:
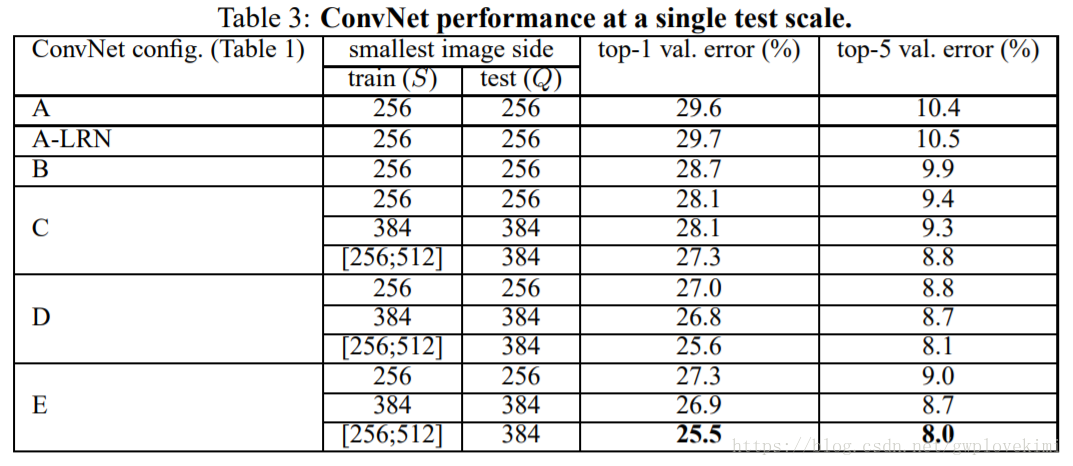
通過分析表3結果,得出如下結論。
- 使用區域性響應歸一化local response normalization(A-LRN)並不能改善A網路效能。
- 分類誤差隨著深度增加而降低。
- 在訓練時採用影象尺度抖動(scale jittering)可以改善影象分類效果。
多尺度評估結果:
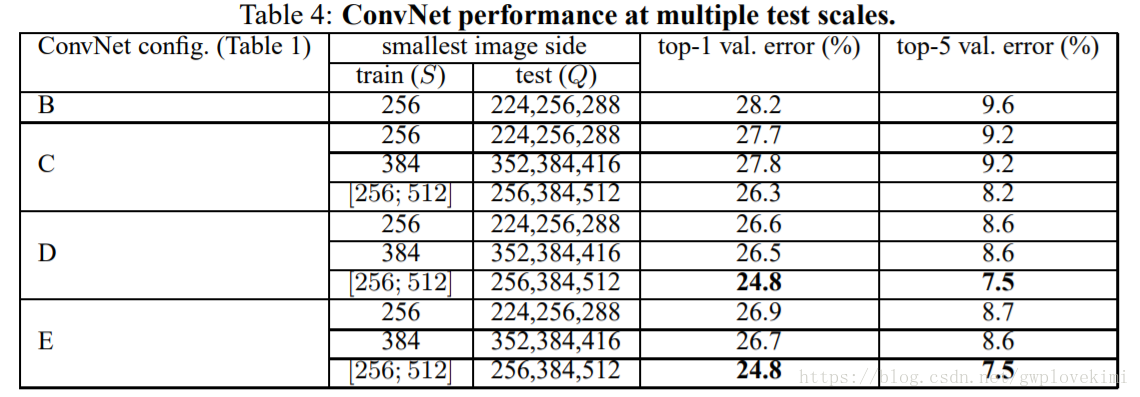
相對於單一尺度評估,多尺度評估提高了分類精度。
與其他模型對比結果:
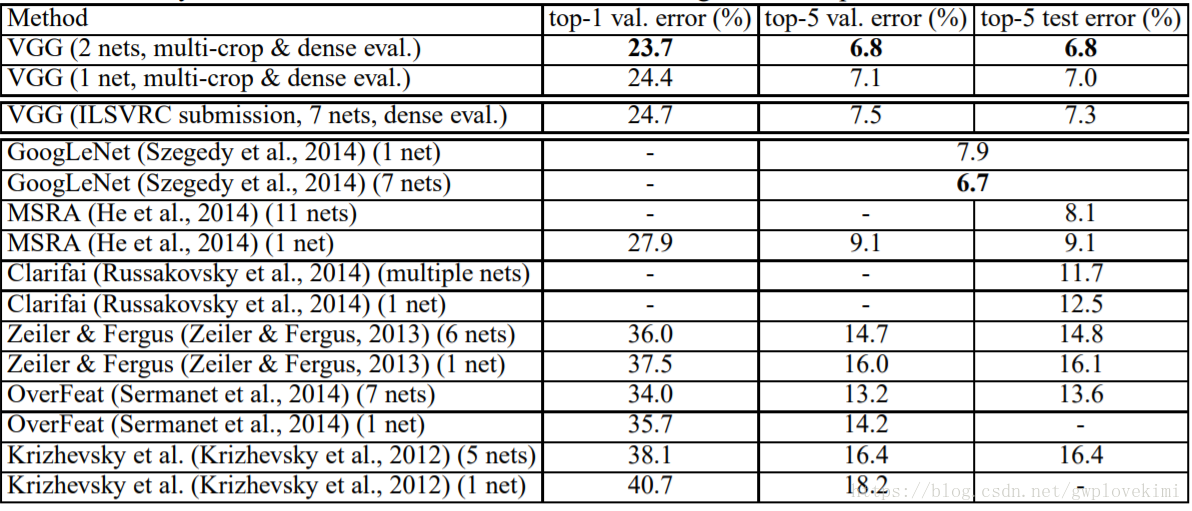
從上表可以看出,深度VGGNet顯著優於前一代模型,在ILSVRC-2012和ILSVRC-2013競賽中取得了最好的結果。VGGNet取得的結果對於分類任務獲勝者(GoogLeNet具有6.7%的錯誤率)也具有競爭力,並且大大優於ILSVRC-2013獲勝者Clarifai,其使用外部訓練資料取得了11.2%的錯誤率,沒有外部資料則為11.7%。這是非常顯著的,考慮到我們最好的結果是僅通過組合兩個模型實現的——明顯少於大多數ILSVRC的參賽者。在單網路效能方面,VGG的架構取得了最好結果(7.0%測試誤差),超過單個GoogLeNet 0.9%。
總結
意義:VGGNet創新地使用3×3小卷積來代替之前模型中的大卷積,在訓練和測試時使用了多尺度評估做資料增強。
優點:VGGNet相比於AlexNet層數更深,引數更多,但是卻可以更快的收斂。利用卷積代替全連線,輸入可適應各種尺寸的圖片。
GoogLeNet
有了VGG的鋪墊,人們開始意識到,為了更好的網路效能,有一條途徑就是加深網路的深度和寬度,但是太過於複雜,引數過多的模型就會使得模型在不夠複雜的資料上傾向於過擬合,並且過多的引數意味著需要更多的算力,也就是需要更多的時間和更多的錢。Google公司的Christian Szegedy在2015年提出了GoogLeNet,其核心思想是:將全連線,甚至是卷積中的區域性連線,全部替換為稀疏連線。原因有二:1)生物神經系統中的連線是稀疏的;2)如果一個數據集的概率分佈可以由一個很大、很稀疏的深度神經網路表示時,那麼通過分析最後一層啟用值的相關統計和對輸出高度相關的神經元進行聚類,可以逐層地構建出一個最優網路結構。也就是說,一個深度稀疏網路可以被逐層簡化,並且因為保留了網路的統計性質,其表達能力也沒有被明顯減弱。
但是由於計算機硬體計算稀疏資料的低效性,現在需要提出的是一種,既能保持網路結構的稀疏性,又能利用密集矩陣計算的高效性的方法。大量研究表明,可以將稀疏矩陣聚類為較為密集的子矩陣來提高計算效能,基於此,Inception模組應運而生。
Inception-v1
首次出現在ILSVRC 2014的比賽中,以較大優勢取得了第一名。該Inception Net通常被稱為Inception-v1,它最大的特點是控制了計算量和引數量的同時,獲得了非常好的分類效能——top-5錯誤率6.67%,只有AlexNet的一半不到。Inception V1有22層深,比AlexNet的8層或者VGGNet的19層還要更深。但其計算量只有15億次浮點運算,同時只有500萬的引數量,僅為AlexNet引數量(6000萬)的1/12,卻可以達到遠勝於AlexNet的準確率 。
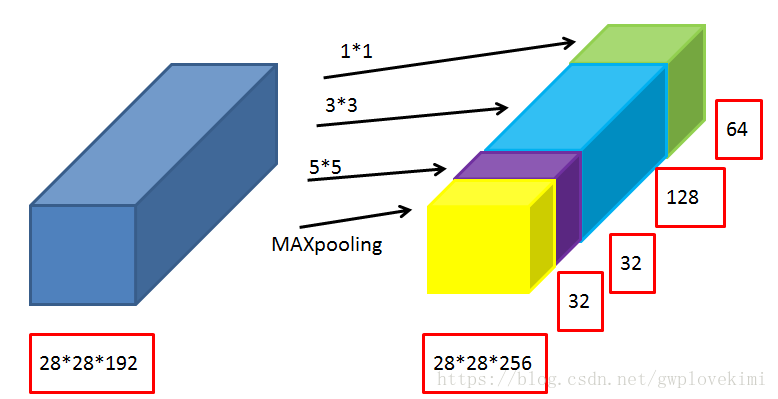
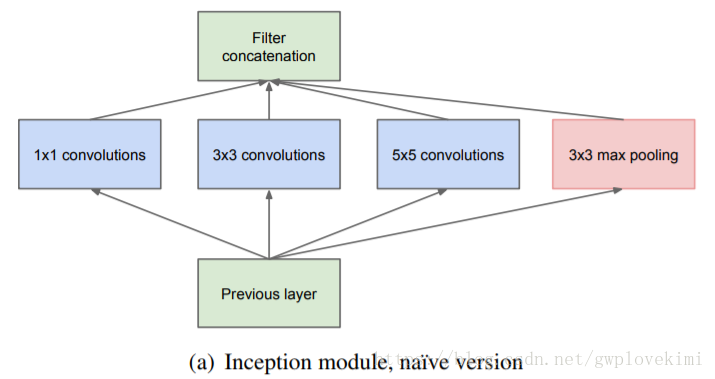
Inception 模組
這種基本模組使用了3種不同的卷積核,提取到的是3種不同尺度的特徵,既有較為巨集觀的特徵又有較為微觀的特徵,增加了特徵的多樣性。池化層目的是保留較為原始的輸入資訊。在模組的輸出端將提取到的各種特徵在channel維度上進行拼接,得到多尺度的特徵feature map。
相關推薦
學習筆記之——基於深度學習的分類網路
之前博文介紹了基於深度學習的常用的檢測網路《學習筆記之——基於深度學習的目標檢測演算法》,本博文為常用的CNN分類卷積網路介紹,本博文的主要內容來自於R&C團隊的成員的調研報告以及本人的理解~如有不當之處,還請各位看客賜教哈~好,下面
學習筆記之——基於深度學習的影象超解析度重構
最近開展影象超解析度( Image Super Resolution)方面的研究,做了一些列的調研,並結合本人的理解總結成本博文~(本博文僅用於本人的學習筆記,不做商業用途) 本博文涉及的paper已經打包,供各位看客下載哈~h
學習筆記之——基於深度學習的目標檢測演算法
國慶假期閒來無事~又正好打算入門基於深度學習的視覺檢測領域,就利用這個時間來寫一份學習的博文~本博文主要是本人的學習筆記與調研報告(不涉及商業用途),博文的部分來自我團隊的幾位成員的調研報告(由於隱私關係,不公告他們的名字了哈~),同時結合
學習筆記之——基於pytorch的卷積神經網路
本博文為本人的學習筆記。參考材料為《深度學習入門之——PyTorch》 pytorch中文網:https://www.pytorchtutorial.com/ 關於反捲積:https://github.com/vdumoulin/conv_arithmetic/blob/ma
學習筆記之——基於pytorch的殘差網路(deep residual network)
本博文為本人學習pytorch系列之——residual network。 前面的博文( 學習筆記之——基於深度學習的分類網路)也已經介紹過ResNet了。ResNet是2015年的ImageNet競賽的冠軍,由微軟研究院提出,通過引入residual block能夠成功地訓練高達
Pybrain學習筆記-4 基於前饋神經網路的分類器
話不多說,直接上程式碼: 5.test_pybrian_5 #!usr/bin/env python #_*_coding:utf-8_*_ ''' Created on 2017年4月14日 Topic:Classification with Feed-Forward Neural Networks @a
Laravel學習筆記之基於PHPStorm編輯器的Laravel開發
引言 本文主要講述在PHPStorm編輯器中如何使用PHPStorm的Laravel外掛和Laravel IDE Helper來開發Laravel程式,結合個人積累的一點經驗來說明使用PHPStorm編輯器來開發程式還是很順手的,內容主要基於PHPStorm官方文件Laravel Developm
學習筆記之——SRGAN深度調研報告
SRGAN這個網路的最大貢獻就是使用了生成對抗網路(Generative adversarial network)來訓練SRResNet,使其產生的HR影象看起來更加自然,有更好的視覺效果(SRResNet是生成網路,對抗網路是用來區分真實的HR影象和通過SRResNet還原出來的HR影象,SR
學習筆記之——基於pytorch的SFTGAN(xintao程式碼學習,及資料處理部分的學習)
程式碼的框架仍然是——《https://github.com/xinntao/BasicSR》 給出SFTGAN的論文《Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transfo
Deep Learning回顧之基於深度學習的目標檢測
轉自:https://www.52ml.net/20287.html 引言 普通的深度學習監督演算法主要是用來做分類,如圖1(1)所示,分類的目標是要識別出圖中所示是一隻貓。而在ILSVRC(ImageNet Large Scale Visual Recognitio
學習筆記之——基於pytorch的FSRCNN
本博文為本人學習基於pytorch的FSRCNN的學習筆記,僅供本人學習記錄用 先採用data_aug.m來增廣資料 再採用generate_train.m將資料生成.h5文件。 至於測試集,此處只採用set5中的五張圖片,所以先不用generate_tes
Docker學習筆記之容器的四種網路模式
首先從映象庫pull一個rhel7的映象下來,這些東西你得玩,光看沒意思。 本人pull了前兩個映象進行測試,如果連線失敗可以多試幾次,連上之後速度不算很差 docker pull richxsl/rhel7 docker pull bluedata/r
Spring原始碼學習筆記之基於ClassPathXmlApplicationContext進行bean標籤解析
bean 標籤在spring的配置檔案中, 是非常重要的一個標籤, 即便現在boot專案比較流行, 但是還是有必要理解bean標籤的解析流程,有助於我們進行 基於註解配置, 也知道各個標籤的作用,以及是怎樣被spring識別的, 以及配置的時候需要注意的點. 傳統的spring專案,s
IP地址和子網劃分學習筆記之《知識學習篇:子網劃分詳解》
子網掩碼 IP地址 子網劃分 在學習掌握了前面的IP地址和子網劃分之《進制計數》和IP地址和子網劃分之《IP地址詳解》這兩部分知識後,接下來將學習子網劃分。 一、子網掩碼 要學習子網劃分,首先就要必須知道子網掩碼,只有掌握了子網掩碼這部分內容,才能很好的理解和劃分子網。 1、子網掩碼介紹 子網掩碼
機器學習筆記之十——整合學習之Bagging
上一節學習了決策樹:https://blog.csdn.net/qq_35946969/article/details/85039097 最後說到提升決策樹的效能,整合就是非常強大的解決方案。 藉助一個圖,直觀的瞭解整合學習: Bagging &nbs
學習筆記:《深度學習框架PyTorch入門與實踐》(陳雲)Part1
學習筆記:《深度學習框架PyTorch入門與實踐》(陳雲)Part1 2017年1月,FAIR團隊在GitHub上開源了PyTorch。 常見的深度學習框架:
吳恩達機器學習 學習筆記 之 一 監督學習和無監督學習
一、 1-1 welcome 1-2 什麼是機器學習——Machine Learning 機器學習尚無明確定義,現有的定義有: (1)Field of study that gives computers the ability to learn about being
學習筆記1:深度學習環境搭建win+python+tensorflow1.5+CUDA9.0+cuDNN7.0
2018年2月13買了一臺Dell Inspiron7577,i7-7700hq、1050Ti顯示卡、win10家庭版。由於課題需要開始學習深度學習,之前在實驗室和自己的筆記本上安裝TensorFlow總是不成功,不然就是僅實現cpu運算。本次安裝主要是按照這
【基於深度學習的細粒度分類筆記8】深度學習模型引數量(weights)計算,決定訓練模型最終的大小
Draw_convnet 這幅圖是通過開源的工具draw_convnet(https://github.com/gwding/draw_convnet)生成的。在清楚整個前向計算網路中的每一個層的輸入輸出以及引數設定後可以自己手動畫出計算圖出來,對於引數量計算就很直觀了
基於深度學習的影象語義分割技術概述之背景與深度網路架構
本文為論文閱讀筆記,不當之處,敬請指正。 A Review on Deep Learning Techniques Applied to Semantic Segmentation: 原文連結 摘要 影象語義分割正在逐漸成為計算機視覺及機器學習研究人員的研究熱點。大