
Day4:感知機
阿新 • • 發佈:2018-11-03
在機器學習中,感知機(perceptron)是二分類的線性分類模型,屬於監督學習演算法。輸入為例項的特徵向量,輸出為例項的類別(取+1和-1)。感知機對應於輸入空間中將例項劃分為兩類的分離超平面。感知機旨在求出該超平面,為求得超平面匯入了基於誤分類的損失函式,利用梯度下降法 對損失函式進行最優化(最優化)。感知機的學習演算法具有簡單而易於實現的優點,分為原始形式和對偶形式。感知機預測是用學習得到的感知機模型對新的例項進行預測的,因此屬於判別模型。感知機由Rosenblatt於1957年提出的,是神經網路和支援向量機的基礎。
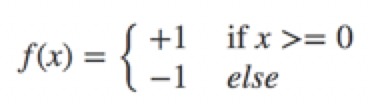 在二分類問題中,f(x)的值(+1或-1)用於分類x為正樣本(+1)還是負樣本(-1)。
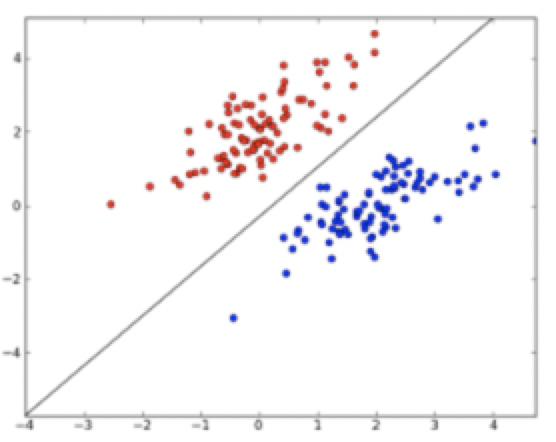
感知機是一種線性分類模型,屬於判別模型。我們需要做的就是找到一個最佳的滿足w⋅x+b=0的w和b值,即分離超平面(separating hyperplane)。如下圖,一個線性可分的感知機模型。
在二分類問題中,f(x)的值(+1或-1)用於分類x為正樣本(+1)還是負樣本(-1)。
感知機是一種線性分類模型,屬於判別模型。我們需要做的就是找到一個最佳的滿足w⋅x+b=0的w和b值,即分離超平面(separating hyperplane)。如下圖,一個線性可分的感知機模型。
 參考:李航《統計學習方法》
參考:李航《統計學習方法》

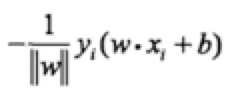
![]() 那麼,所有點到超平面的總距離為:
那麼,所有點到超平面的總距離為:
![]() 不考慮
不考慮
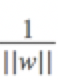 就得到感知機的損失函數了。
就得到感知機的損失函數了。
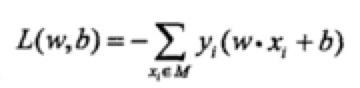
![]() 其中M為誤分類的集合。這個損失函式就是感知機學習的經驗風險函式。
可以看出,隨時函式L(w,b)是非負的。如果沒有誤分類點,則損失函式的值為0,而且誤分類點越少,誤分類點距離超平面就越近,損失函式值就越小。一個特定的樣本點的損失函式:在誤分類時是引數w,b的線性函式,在正確分類時是0,因此,對於給定的訓練資料集T,損失函式L(w,b)是連續可導函式。
感知機學習的策略是在假設空間中選取使損失函式式最小的模型引數w,b,即感知機模型。
其中M為誤分類的集合。這個損失函式就是感知機學習的經驗風險函式。
可以看出,隨時函式L(w,b)是非負的。如果沒有誤分類點,則損失函式的值為0,而且誤分類點越少,誤分類點距離超平面就越近,損失函式值就越小。一個特定的樣本點的損失函式:在誤分類時是引數w,b的線性函式,在正確分類時是0,因此,對於給定的訓練資料集T,損失函式L(w,b)是連續可導函式。
感知機學習的策略是在假設空間中選取使損失函式式最小的模型引數w,b,即感知機模型。
 上圖就是隨機梯度下降法一步一步達到最優值的過程,說明一下,梯度下降其實是區域性最優。感知機學習演算法本身是誤分類驅動的,因此我們採用隨機梯度下降法。
首先,任選一個超平面w0和b0,然後使用梯度下降法不斷地極小化目標函式
上圖就是隨機梯度下降法一步一步達到最優值的過程,說明一下,梯度下降其實是區域性最優。感知機學習演算法本身是誤分類驅動的,因此我們採用隨機梯度下降法。
首先,任選一個超平面w0和b0,然後使用梯度下降法不斷地極小化目標函式
 極小化過程不是一次使M中所有誤分類點的梯度下降,而是一次隨機的選取一個誤分類點使其梯度下降。使用的規則為 θ:=θ−α∇θℓ(θ),其中α是步長,∇θℓ(θ)是梯度。假設誤分類點集合M是固定的,那麼損失函式L(w,b)的梯度通過偏導計算:
極小化過程不是一次使M中所有誤分類點的梯度下降,而是一次隨機的選取一個誤分類點使其梯度下降。使用的規則為 θ:=θ−α∇θℓ(θ),其中α是步長,∇θℓ(θ)是梯度。假設誤分類點集合M是固定的,那麼損失函式L(w,b)的梯度通過偏導計算:
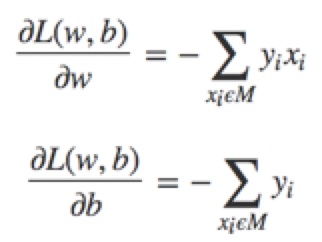 然後,隨機選取一個誤分類點,根據上面的規則,計算新的w,b,然後進行更新:
然後,隨機選取一個誤分類點,根據上面的規則,計算新的w,b,然後進行更新:
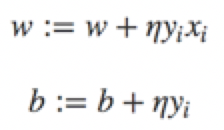 其中η是步長,大於0小於1,在統計學習中稱之為學習率(learning rate)。這樣,通過迭代可以期待損失函式L(w,b)不斷減小,直至為0.
綜上所述,得到如下演算法:
其中η是步長,大於0小於1,在統計學習中稱之為學習率(learning rate)。這樣,通過迭代可以期待損失函式L(w,b)不斷減小,直至為0.
綜上所述,得到如下演算法:
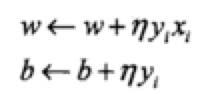 (4) 轉至(2),直至訓練集中沒有誤分類點
直觀解釋:當一個例項點被誤分類時,調整w,b,使分離超平面向該誤分類點的一側移動,以減少該誤分類點與超平面的距離,直至超越該點被正確分類。
上面的演算法是感知機的基本演算法,對應於後面的對偶形式,稱為原始形式。
(4) 轉至(2),直至訓練集中沒有誤分類點
直觀解釋:當一個例項點被誤分類時,調整w,b,使分離超平面向該誤分類點的一側移動,以減少該誤分類點與超平面的距離,直至超越該點被正確分類。
上面的演算法是感知機的基本演算法,對應於後面的對偶形式,稱為原始形式。
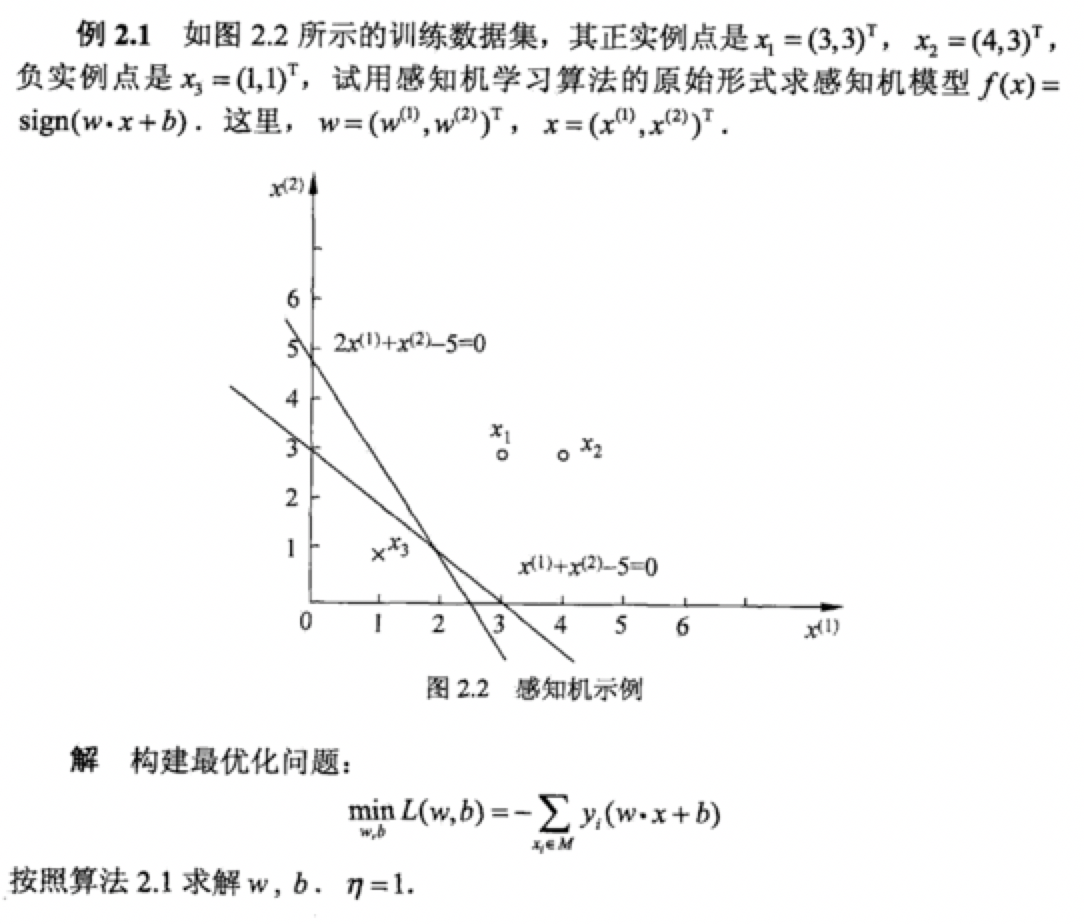

 4.1感知機學習演算法的對偶形式
4.1感知機學習演算法的對偶形式



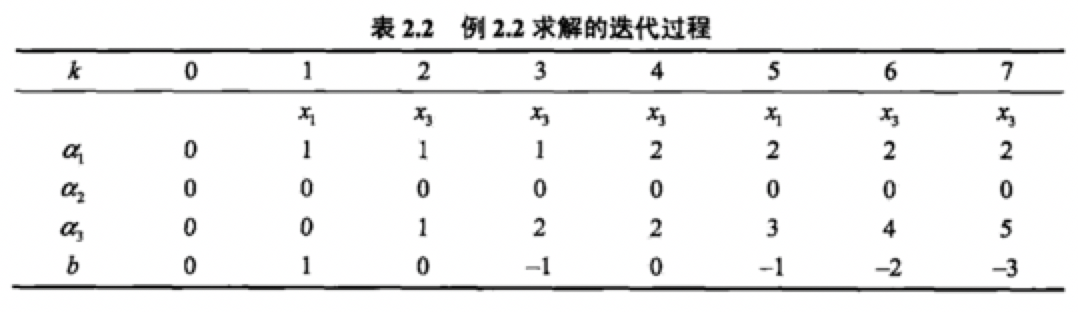 我們推導如下。從原始形式中我們可以知道。w的更新過程。
第一次更新是x1y1=((3,3)T,1 ) 點不能是函式模型大於零,所以 w1=w0+x1y1
第二次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w2=w1+x3y3
第三次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w3=w2+x3y3
第四次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w4=w3+x3y3
第五次更新是x1y1=((3,3)T,1 )點不能使其大於零,所以 w5=w4+x1y1
第六次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w6=w5+x3y3
第七次更新是x3y3=((1,1)T,-1 )點能使其大於零,所以 w7=w6+x3y3
然後我們得到
我們推導如下。從原始形式中我們可以知道。w的更新過程。
第一次更新是x1y1=((3,3)T,1 ) 點不能是函式模型大於零,所以 w1=w0+x1y1
第二次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w2=w1+x3y3
第三次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w3=w2+x3y3
第四次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w4=w3+x3y3
第五次更新是x1y1=((3,3)T,1 )點不能使其大於零,所以 w5=w4+x1y1
第六次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w6=w5+x3y3
第七次更新是x3y3=((1,1)T,-1 )點能使其大於零,所以 w7=w6+x3y3
然後我們得到
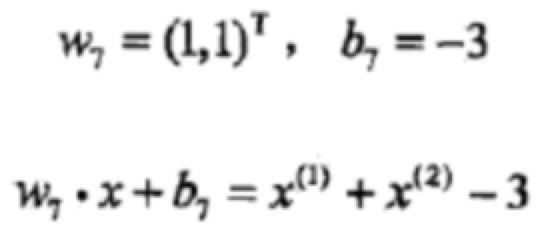
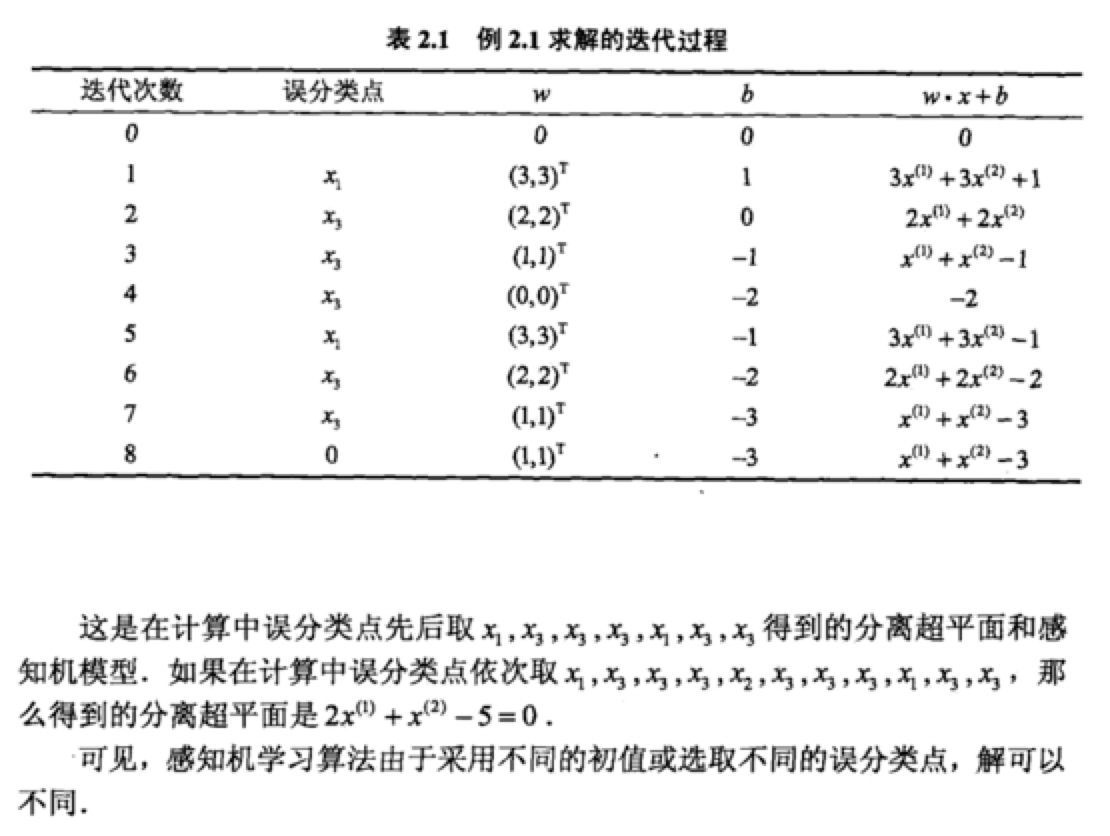
 從上面可以總結出w7=w6+x3y3
w7=w5+x3y3 +x3y3
w7=w4+x1y1+x3y3 +x3y3
w7=w3+x3y3+x1y1+x3y3 +x3y3
w7=w2+x3y3+x3y3+x1y1+x3y3 +x3y3
w7=w1+x3y3 +x3y3+x3y3+x1y1+x3y3 +x3y3
w7=w0+x1y1 +x3y3 +x3y3+x3y3+x1y1+x3y3 +x3y3
所以我們可以得出最終w7的值為兩次x1y1 +五次x3y3
也就等於在對偶形式中
從上面可以總結出w7=w6+x3y3
w7=w5+x3y3 +x3y3
w7=w4+x1y1+x3y3 +x3y3
w7=w3+x3y3+x1y1+x3y3 +x3y3
w7=w2+x3y3+x3y3+x1y1+x3y3 +x3y3
w7=w1+x3y3 +x3y3+x3y3+x1y1+x3y3 +x3y3
w7=w0+x1y1 +x3y3 +x3y3+x3y3+x1y1+x3y3 +x3y3
所以我們可以得出最終w7的值為兩次x1y1 +五次x3y3
也就等於在對偶形式中
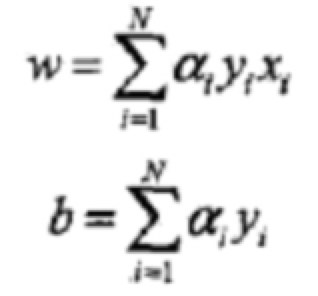


1、定義
假設輸入空間(特徵向量)為X⊆Rn,輸出空間為Y={-1, +1}。輸入x∈X表示例項的特徵向量,對應於輸入空間的點;輸出y∈Y表示示例的類別。由輸入空間到輸出空間的函式:f(x)=sign(w·x+b)稱為感知機。 其中,引數w叫做權值向量weight,b稱為偏置bias。w·x表示w和x的內積。∑i=1mwixi=w1x1+w2x2+...+wnxn sign為符號函式,即
在二分類問題中,f(x)的值(+1或-1)用於分類x為正樣本(+1)還是負樣本(-1)。
感知機是一種線性分類模型,屬於判別模型。我們需要做的就是找到一個最佳的滿足w⋅x+b=0的w和b值,即分離超平面(separating hyperplane)。如下圖,一個線性可分的感知機模型。
2、資料集的線性可分性
參考:李航《統計學習方法》
3、感知機學習策略
損失函式 如果訓練集是可分的,感知機的學習目的是求得一個能將訓練集正例項點和負例項點完全分開的分離超平面。為了找到這樣一個平面(或超平面),即確定感知機模型引數w和b,即確定感知機模型引數w,b,需要確定一個學習策略,即定義(經驗)損失函式並將損失函式極小化。 損失函式的一個自然選擇是誤分類點的總數,但是這樣的損失函式不是引數w,b的連續可導函式,不易優化,損失函式的另一個選擇是誤分類點到超平面的距離(可以自己推算一下,這裡採用的是幾何間距,就是點到直線的距離)4、感知機學習演算法
上圖就是隨機梯度下降法一步一步達到最優值的過程,說明一下,梯度下降其實是區域性最優。感知機學習演算法本身是誤分類驅動的,因此我們採用隨機梯度下降法。
首先,任選一個超平面w0和b0,然後使用梯度下降法不斷地極小化目標函式
極小化過程不是一次使M中所有誤分類點的梯度下降,而是一次隨機的選取一個誤分類點使其梯度下降。使用的規則為 θ:=θ−α∇θℓ(θ),其中α是步長,∇θℓ(θ)是梯度。假設誤分類點集合M是固定的,那麼損失函式L(w,b)的梯度通過偏導計算:
然後,隨機選取一個誤分類點,根據上面的規則,計算新的w,b,然後進行更新:
其中η是步長,大於0小於1,在統計學習中稱之為學習率(learning rate)。這樣,通過迭代可以期待損失函式L(w,b)不斷減小,直至為0.
綜上所述,得到如下演算法:
4.1感知機學習演算法原始形式
輸入:T={(x1,y1),(x2,y2)...(xN,yN)}(其中xi∈X=Rn,yi∈Y={-1, +1},i=1,2...N,學習速率為η) 輸出:w, b;感知機模型f(x)=sign(w·x+b) (1) 初始化w0,b0,權值可以初始化為0或一個很小的隨機數 (2) 在訓練資料集中選取(x_i, y_i) (3) 如果yi(w xi+b)≤0
(4) 轉至(2),直至訓練集中沒有誤分類點
直觀解釋:當一個例項點被誤分類時,調整w,b,使分離超平面向該誤分類點的一側移動,以減少該誤分類點與超平面的距離,直至超越該點被正確分類。
上面的演算法是感知機的基本演算法,對應於後面的對偶形式,稱為原始形式。
4.1感知機學習演算法的對偶形式
我們推導如下。從原始形式中我們可以知道。w的更新過程。
第一次更新是x1y1=((3,3)T,1 ) 點不能是函式模型大於零,所以 w1=w0+x1y1
第二次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w2=w1+x3y3
第三次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w3=w2+x3y3
第四次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w4=w3+x3y3
第五次更新是x1y1=((3,3)T,1 )點不能使其大於零,所以 w5=w4+x1y1
第六次更新是x3y3=((1,1)T,-1 )點不能使其大於零,所以 w6=w5+x3y3
第七次更新是x3y3=((1,1)T,-1 )點能使其大於零,所以 w7=w6+x3y3
然後我們得到
5、python實現

1 import random 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 def sign(v): 6 if v>=0: 7 return 1 8 else: 9 return -1 10 11 def train(train_num,train_datas,lr): 12 w=[0,0] 13 b=0 14 for i in range(train_num): 15 x=random.choice(train_datas) 16 x1,x2,y=x 17 if(y*sign((w[0]*x1+w[1]*x2+b))<=0): 18 w[0]+=lr*y*x1 19 w[1]+=lr*y*x2 20 b+=lr*y 21 return w,b 22 23 def plot_points(train_datas,w,b): 24 plt.figure() 25 x1 = np.linspace(0, 8, 100) 26 x2 = (-b-w[0]*x1)/w[1] 27 plt.plot(x1, x2, color='r', label='y1 data') 28 datas_len=len(train_datas) 29 for i in range(datas_len): 30 if(train_datas[i][-1]==1): 31 plt.scatter(train_datas[i][0],train_datas[i][1],s=50) 32 else: 33 plt.scatter(train_datas[i][0],train_datas[i][1],marker='x',s=50) 34 plt.show() 35 36 if __name__=='__main__': 37 train_data1 = [[1, 3, 1], [2, 2, 1], [3, 8, 1], [2, 6, 1]] # 正樣本 38 train_data2 = [[2, 1, -1], [4, 1, -1], [6, 2, -1], [7, 3, -1]] # 負樣本 39 train_datas = train_data1 + train_data2 # 樣本集 40 w,b=train(train_num=50,train_datas=train_datas,lr=0.01) 41 plot_points(train_datas,w,b)原始感知機
1 import random 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 def sign(v): 6 if v>=0: 7 return 1 8 else: 9 return -1 10 11 def train(train_num,train_datas,lr): 12 w=0.0 13 b=0 14 datas_len = len(train_datas) 15 alpha = [0 for i in range(datas_len)] 16 train_array = np.array(train_datas) 17 gram = np.matmul(train_array[:,0:-1] , train_array[:,0:-1].T) 18 for idx in range(train_num): 19 tmp=0 20 i = random.randint(0,datas_len-1) 21 yi=train_array[i,-1] 22 for j in range(datas_len): 23 tmp+=alpha[j]*train_array[j,-1]*gram[i,j] 24 tmp+=b 25 if(yi*tmp<=0): 26 alpha[i]=alpha[i]+lr 27 b=b+lr*yi 28 for i in range(datas_len): 29 w+=alpha[i]*train_array[i,0:-1]*train_array[i,-1] 30 return w,b,alpha,gram 31 32 def plot_points(train_datas,w,b): 33 plt.figure() 34 x1 = np.linspace(0, 8, 100) 35 x2 = (-b-w[0]*x1)/(w[1]+1e-10) 36 plt.plot(x1, x2, color='r', label='y1 data') 37 datas_len=len(train_datas) 38 for i in range(datas_len): 39 if(train_datas[i][-1]==1): 40 plt.scatter(train_datas[i][0],train_datas[i][1],s=50) 41 else: 42 plt.scatter(train_datas[i][0],train_datas[i][1],marker='x',s=50) 43 plt.show() 44 45 if __name__=='__main__': 46 train_data1 = [[1, 3, 1], [2, 2, 1], [3, 8, 1], [2, 6, 1]] # 正樣本 47 train_data2 = [[2, 1, -1], [4, 1, -1], [6, 2, -1], [7, 3, -1]] # 負樣本 48 train_datas = train_data1 + train_data2 # 樣本集 49 w,b,alpha,gram=train(train_num=500,train_datas=train_datas,lr=0.01) 50 plot_points(train_datas,w,b)對偶感知機
6、參考資料
李航《統計學習方法》