
Multi-Oriented Text Detection with Fully Convolutional Networks
2.相關工作
自然影象中的文字檢測已經受到計算機視覺和文件分析社群的廣泛關注。然而,大多數文字檢測方法主要以兩種方式集中於檢測水平或近水平文字:1)定位單詞的邊界框[4,3,17,15,18,33,5,6],2)組合檢測和識別程式成為端到端的文字識別方法[8,28]。場景文字檢測和識別的綜合調查可參考[30,36]。
在本節中,我們將重點介紹為多方向文字檢測提供的最相關的工作。在野外進行多4160定向文字檢測首先由[31,29]研究。它們的檢測管道類似於基於連通分量提取的傳統方法,集成了每個字元和文字行的方向估計。 [9]將每個MSER元件視為圖中的頂點,然後將文字檢測轉換為圖分割槽問題。 [32]提出了一種多階段聚類演算法,用於對MSER元件進行分組以檢測多向文字。 [28]提出了一種基於SWT [4]的面向多向文字的端到端系統。最近,ICDAR2015文字檢測競賽已經發布了面向多向文字檢測的具有挑戰性的基準,許多研究人員已經在其上報告了他們的結果。
此外,值得一提的是,最近的兩種方法[25,8,6]和我們使用深度卷積神經網路的方法在幾個方面都取得了優於傳統方法的優越效能:1)學習更強大的元件通過CNN畫素標記表示[8]; 2)利用CNN的強大辨別能力,更好地消除誤報[6,35]; 3)通過CNN學習一個強大的字元/單詞識別器,用於端到端文字檢測[25,7]。但是,這些方法僅關注水平文字檢測。
3.提議的方法
在本節中,我們將詳細描述所提出的方法。 首先,通過完全卷積網路(稱為Text-Block FCN)檢測文字塊。 然後,通過考慮本地資訊(MSER元件)從這些文字塊中提取多方向文字行候選。 最後,通過字元質心資訊消除偽文字行候選。 字元質心資訊由較小的完全卷積網路(名為Character-Centroid FCN)提供。
3.1. 文字塊檢測
在過去幾年中,場景文字檢測中的大多數主要方法都是基於檢測字元。在早期實踐[16,18,29]中,大量手動設計的特徵用於識別具有強分類器的字元。最近,一些作品[6,8]取得了很好的成績,採用CNN作為字元檢測器。然而,即使是最先進的字元檢測器[8]在複雜的背景下仍然表現不佳(圖4(b))。由於三個方面,字元檢測器的效能受到限制:首先,字元易受多種條件的影響,如模糊,不均勻照明,低解析度,斷開行程等;其次,背景中的大量元素在外觀上與人物相似,使得它們極難區分;第三,角色本身的變化,例如字型,顏色,語言等,增加了分類器的學習難度。相比之下,文字塊具有更多可區分和穩定的屬性。文字塊的區域性和全域性外觀都是區分文字區域和非文字區域的有用線索(圖4(c))。完全卷積網路(FCN)是最近提出的一種深度卷積神經網路,它在畫素級識別任務上取得了很好的效能,如物件分割[12]和邊緣檢測[26]。由於以下幾個優點,這種網路非常適合於檢測文字塊:1)同時考慮本地和全域性上下文資訊。 2)以端到端的方式進行培訓; 3)受益於完全連線的層的移除,FCN在畫素標記中是有效的。在本節中,我們將學習名為Text-Block FCN的FCN模型,以整體方式標記文字塊的顯著區域。
Text-Block FCN
我們將VGG 16層網路[22]轉換為我們的文字塊檢測模型,如圖3所示。前5個卷積階段來自VGG 16層網路。卷積階段的感受域大小是可變的,有助於不同階段可以捕獲具有不同大小的上下文資訊。每個卷積階段之後是去卷積層(等於1×1卷積層和上取樣層)以生成相同大小的特徵圖。然後,辨別和分層融合圖是這些上取樣對映的深度級聯。最後,用1×1卷積層和S形層替換完全連線的層,以有效地進行畫素級預測。
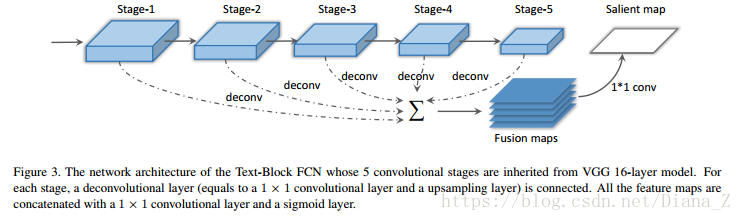
在訓練階段,由於以下原因,每個文字行或單詞的邊界框內的畫素被認為是正區域:首先,相鄰字元之間的區域與其他非文字區域不同;其次,全域性文字結構可以納入模型;第三,文字行或單詞的邊界框易於註釋和獲得。地面實況圖的一個例子如圖5所示。交叉熵損失函式和隨機梯度下降用於訓練該模型。

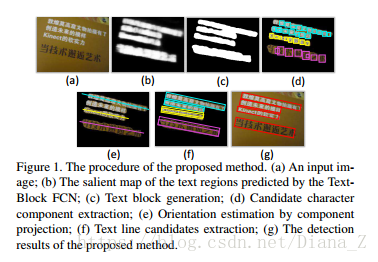
在測試階段,文字區域的salient map,利用來自不同階段的所有上下文資訊,首先由訓練的Text-Block FCN模型計算。如圖2所示,階段1的特徵圖捕獲更多區域性結構,如梯度(圖2(b)),而較高階段捕獲更多全域性資訊(圖2(e)(f)) 。然後,保留概率大於0.2的畫素,並將連線的畫素組合在一起成為幾個文字塊。文字塊檢測結果的一個例子如圖1(c)所示。

3.2. 多方位文字行候選生成
在本節中,我們將介紹如何基於文字塊形成多方向文字行候選。雖然文Text-Block FCN檢測到的文字塊提供了文字行的粗略定位,但它們仍然遠遠不能令人滿意。為了進一步提取文字行的準確邊界框,需要考慮有關文字的方向和比例的資訊。文字行或單詞中的字元元件顯示文字的比例。此外,可以通過分析字元元件的佈局來估計文字的方向。首先,我們通過MSER [16]提取文字塊中的字元元件。然後,類似於文件分析[19]中的許多歪斜校正方法,通過元件投影來估計文字塊內文字行的方向。最後,通過有效組合塊級(全域性)提示和元件級別(本地)提示的新方法提取文字行候選。
字元元件提取
我們的方法使用MSER [16]來提取字元元件(圖1(d)),因為MSER對比例,方向,位置,語言和字型的變化不敏感。採用兩個約束來消除大部分虛假成分:面積和縱橫比。具體地,字元候選的最小面積比需要大於閾值T1,並且它們的縱橫比必須限於[1/T2,T2]。在這兩個約束條件下,大多數錯誤元件都被排除在外。
方向估計
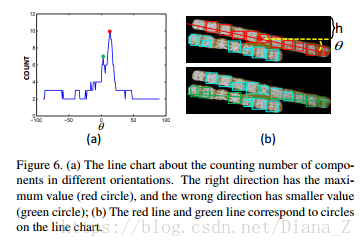
在本文中,我們假設來自同一文字塊的文字行具有大致均勻的空間佈局,並且來自一個文字行的字元是直線或近直線的排列。受文獻分析[19]中基於投影輪廓的偏斜估計演算法的啟發,我們根據計陣列件提出一種投影方法,以估計文字行的可能方向。假設文字塊中文字行的方向是θ,垂直座標偏移是h,我們可以在文字塊上畫一條線(綠色或紅色線如圖6(b)所示)。並且計數分量Φ(θ,h)的值等於線路所經過的字元分量的數量。由於右方向的元件數通常具有最大值,如果我們對所有方向上的計數分量的峰值進行統計,則可以容易地找到可能的方向θr(圖6(a))。通過這種方式,θr可以很容易地計算如下:

其中Φ(θ,h)表示當方向為θ且垂直座標偏移為h時的分量數。
文字行候選生成
與基於元件的方法[16,4,6]不同,在我們的方法中生成文字行候選的過程不需要在文字塊的指導下捕獲文字行中的所有字元。首先,我們將元件分成組。如果文字塊α中的一對元件(A和B)滿足以下條件,則它們被組合在一起:
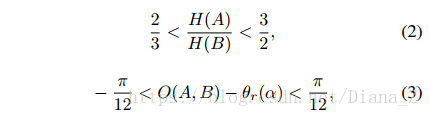
其中H(A)和H(B)代表A和B的高度,O(A,B)代表該對的方向,θr(α)是α的估計方向。
然後,對於一組β= {ci},ci是第i個元件,我們沿著θr(α)的方向繪製一條通過β的中心的線L。點集P定義為:
其中B(α)表示α的邊界點。
最後,β的最小邊界框bb作為文字行候選框被計算出來:
其中U表示包含所有點和元件的最小邊界框。
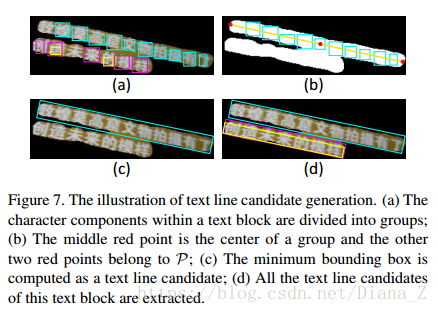
圖7說明了這個過程。我們對每個文字塊重複此過程以獲得影象中的所有文字行候選。通過同時考慮兩個水平線索,與基於元件的方法相比,我們的方法具有兩個優點[16,4,6]。首先,在文字塊的指導下,MSER元件不需要準確捕獲所有字元。即使某些字元被MSER遺漏或部分檢測到,文字行候選的生成也不會受到影響(例如圖7中的三個候選者)。其次,自然場景中多方向文字檢測的先前作品[29,9,32]通常使用一些脆弱的聚類/分組演算法進行基於角色等級的文字方向估計。這種方法對缺失字元和非文字噪聲很敏感。我們的方法通過使用投影方法從整體輪廓估計方向,該方法比基於字元聚類/分組的方法更有效和更健壯。
3.3. 文字行候選分類
在最後階段(第3.2節)生成的候選項的一小部分是非文字或冗餘。為了刪除錯誤的候選者,我們基於文字行候選的字元質心提出兩個標準。為了預測角色質心,我們採用了另一種名為Character-Centroid FCN的FCN模型。
Character-Centroid FCN
Character-Centroid FCN繼承自Text-Block FCN(第3.1節),但僅使用前3個卷積階段。與TextBlock FCN相同,每個階段後跟一個1×1卷積層和一個上取樣層。全連線的層也用1×1卷積層和sigmoid層代替。該網路也使用交叉熵損失函式進行訓練。通常,Character-Centroid FCN是Text-Block FCN的小版本。

圖8中示出了幾個示例以及地面實況圖。地面實況圖的正區域由與角色質心的距離小於15%的相應字元高度的畫素組成。在測試階段,我們首先可以獲得文字行候選的質心概率圖。然後,收集地圖上的極值點E = {(ei,si)}作為質心,其中ei表示第i個極值點,並且si表示ei定義在上的概率圖的值的分數。圖9中顯示了幾個例子。為了去除錯誤的候選者,在獲得質心之後,採用兩個基於強度和幾何特性的直觀而有效的標準:
強度標準
對於文字行候選,如果字元質心的數量nc <2,或者質心的平均得分Savg <0.6,我們將其視為假文字行候選。質心的平均分數定義為:

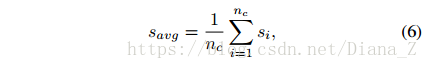
幾何標準
文字行候選框內的字元的排列總是近似為直線。 我們採用方位角μ的平均值和質心之間的方位角的標準偏差σ來表徵這些屬性。 μ和σ定義為:
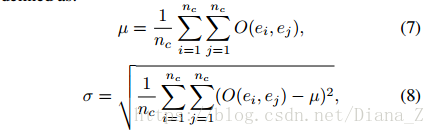
其中O(ei,ej)表示ei和ej之間的方位角。 在實踐中,我們僅保留μ<π/32且σ<π/16的候選框。
通過上述兩個約束,排除了假文字行候選,但仍然存在一些冗餘候選。 為了進一步去除冗餘候選者,對剩餘候選者應用標準非最大抑制,並且將非最大抑制中使用的分數定義為所有質心的分數之和。
4.實驗
為了將提出的方法與競爭方法進行全面比較,我們在幾個最近的標準基準上評估了我們的方法:ICDAR2013,ICDAR2015和MSRATD500。
程式碼:
https://github.com/stupidZZ/FCN_Text