
第二次結對程式設計專案總結
第二次結對程式設計專案總結
第二次結對專案(詞頻統計要求網址):
https://www.cnblogs.com/xinz/archive/2011/11/27/2265000.html
專案網址:
基本要求
根據輸入的命令列引數,對文字中的字元進行對應的統計,例如使用-c命令統計字元出現次數,利用-f統計單詞出現次數等等。專案一共分為5個步驟,4個必做項和一個附加項。在本次專案中,我們依次完成了這樣的5個步驟,並將對應步驟記錄在github中。
結對分工
在這次結對程式設計中,我們採取的是分工 -> 領航員與駕駛員 -> 分工 這樣的合作模式。採取這樣模式的主要原因是一個是這個專案延續了兩週,在日常難以協調出長時間進行程式設計的時間,所以選擇在週末進行領航員與駕駛員式的結對程式設計,平常以分工和簡短的討論為主。在分工程式碼出現問題時會採用遠端共享桌面的方式進行合作。
程式設計規範的確定
由於是第二次專案,之前對彼此程式碼風格都有一定了解,並且兩個人都對變數命名規範等沒有很強的強迫症,所以我們選取了一篇部落格中的編碼規範(該部落格地址在我們的github專案中),並對一些細節在第一次討論時做了一定的規範,很快達成一致。在討論中,我們還確定了程式碼的幾個部分和合作的方式。
做到儘量好的結果
策略
由於時間的限制,所以做的結果是一個我們可以接受的儘量好的結果。我們採取的結對策略是分工,領航員與駕駛員,分工的合作模式,所以在接到專案的前期,我們先是使用開會的方式很快的確定了採用python作為程式語言,和一些對應的編碼規範。
資料收集
比起盲目嘗試,這樣一個經典的專案會有很多的參考。所以在討論之後我們進入一段時間的資料收集,參考網路上如何進行詞頻統計的程式碼示例來總結一些經驗。在這個階段,我們主要使用Skype直接分享調研得到的結果。通過這個調研結果,我們發現使用python的collection包中的Counter可以很快速的幫助我們對詞頻進行統計。使用正則匹配的re函式包可以用正則表示式進行分詞。所以我們先定下了初步的使用到的函式
初步分工
我們在這個階段主要是依據之前收集的資料進行初步的程式設計,先不考慮任何的實現效率,使用庫函式和基本的邏輯判斷做一個初步的,可以實現所有功能的版本,保證可以復現出一個相對正確的結果。並編寫一定的測試樣例來保證我們結果的正確性,對每一步迭代進行單元測試和迴歸測試
領航員與駕駛員
在週末,完成了初步功能版本的我們開始了結對優化。我們使用的是Visual Studio中的python效能分析功能進行效能分析,使用unittest進行單元測試的編寫。
首先,我們進行了一些實現誤區上的糾正,例如幾個命令列引數不可以混用以及例如stopword應該如何處理這個樣子的誤區我們進行了糾正,並修改了對應的單元測試,之後我們為程式碼添加了計時模組,同時利用程式本身的計時和python效能分析來進行判斷。
在最初版本的優化中,因為我們誤將動詞加介詞形式的短語作為優化的重點,所以我們將大部分精力放置於如何優化動詞加介詞的判斷。由於re模組的正則匹配是一個不回溯的匹配模式,所以我們採取先分割單詞再人為對單詞進行組合成短語的形式進行判斷。

在上述截圖中,我們發現compile函式呼叫了8521次,findall呼叫了8493次,查詢字典中對應的key呼叫了124071次,我們查看了具體的呼叫處,
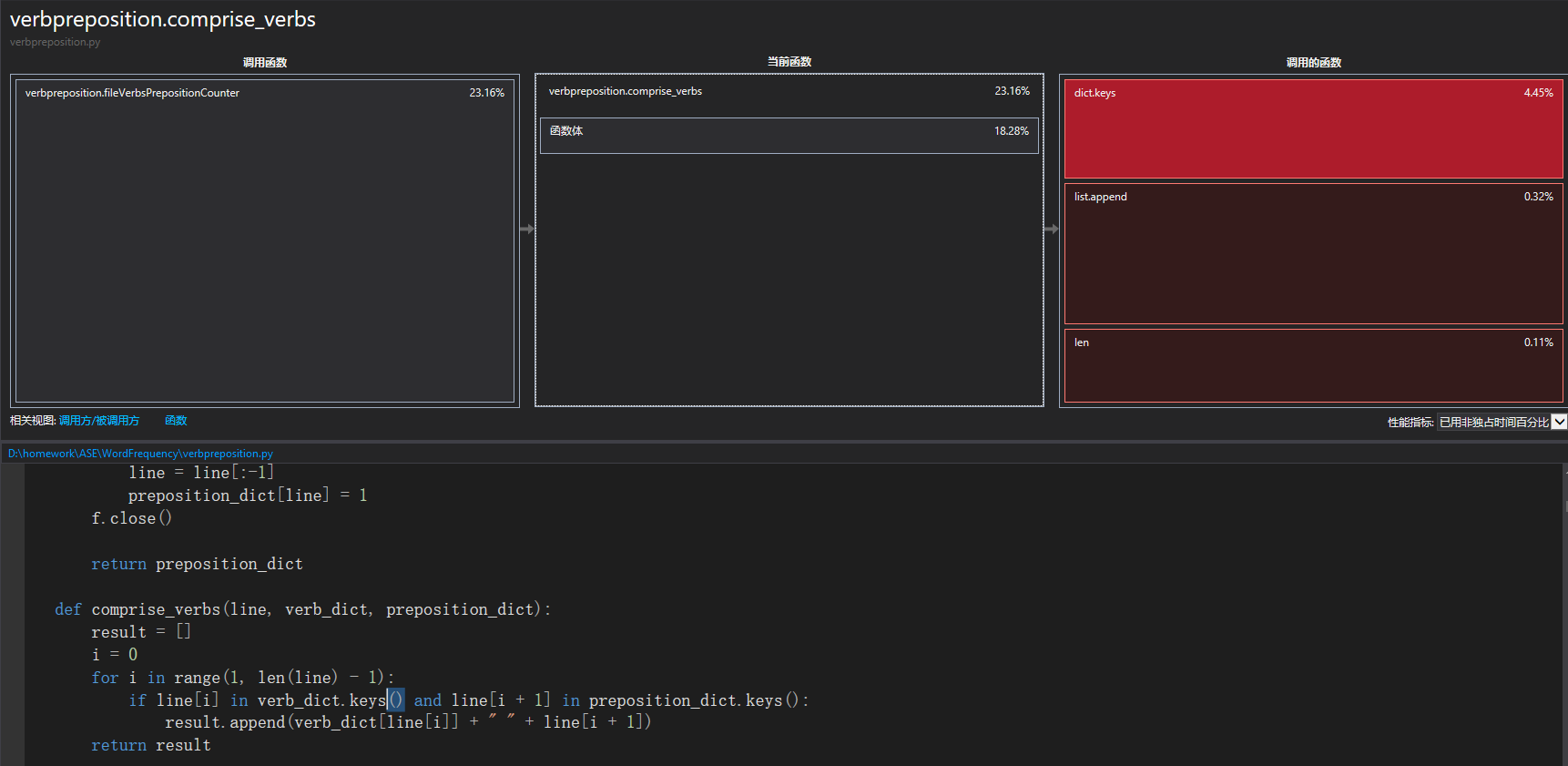
通過資料查閱,發現字典可以不使用keys來呼叫所有的鍵值,所以我們對程式碼進行了修改,將keys刪除,來減少字典查詢時間,
經過優化,速度從0.13提升到0.10(500K大小的文字檔案)。之後,採用類似的策略,我們嘗試減少了判斷次數,比如在匹配成功的情況下可以直接跳過一個單詞進行判斷,也就是可以在發現了一個動詞加空格加介詞的形式時直接跳過一個單詞。之後,同樣的啟發,我們對判斷短語函式中的長短語判斷邏輯進行了優化。也就是,儘量每個詞只進行一次判斷,採取一個跳躍的判斷形式,類似於KMP的演算法流程,如下所示:
while i < length: while j < pharse: if line[i + j][0] > 'z' or line[i + j][0] < 'a': i = i + j j = 0 temp='' break temp = temp + line[i + j] + ' ' lens[j] = len(line[i+j]) j = j + 1 if j==pharse: j = pharse - 1 result.append(temp[:-1]) temp = temp[lens[0]+1:] for k in range(pharse-1): lens[k] = lens[k+1] i = i + 1在之後的優化邏輯中,由於我們拼接字串會多引入一個空格,而我們用來有一定邏輯判斷的rstrip函式進行了空格去除操作,這部分邏輯判斷並不是必須的,因此我們採取[:-1]的字串擷取操作。
在這一版本的效能分析中,我們發現求字串長度的len函式呼叫次數非常多,所以我們將此處的字串拼接操作改成了使用列表進行儲存操作,減少字串拼接次數,同樣獲得了一定的速度提升。
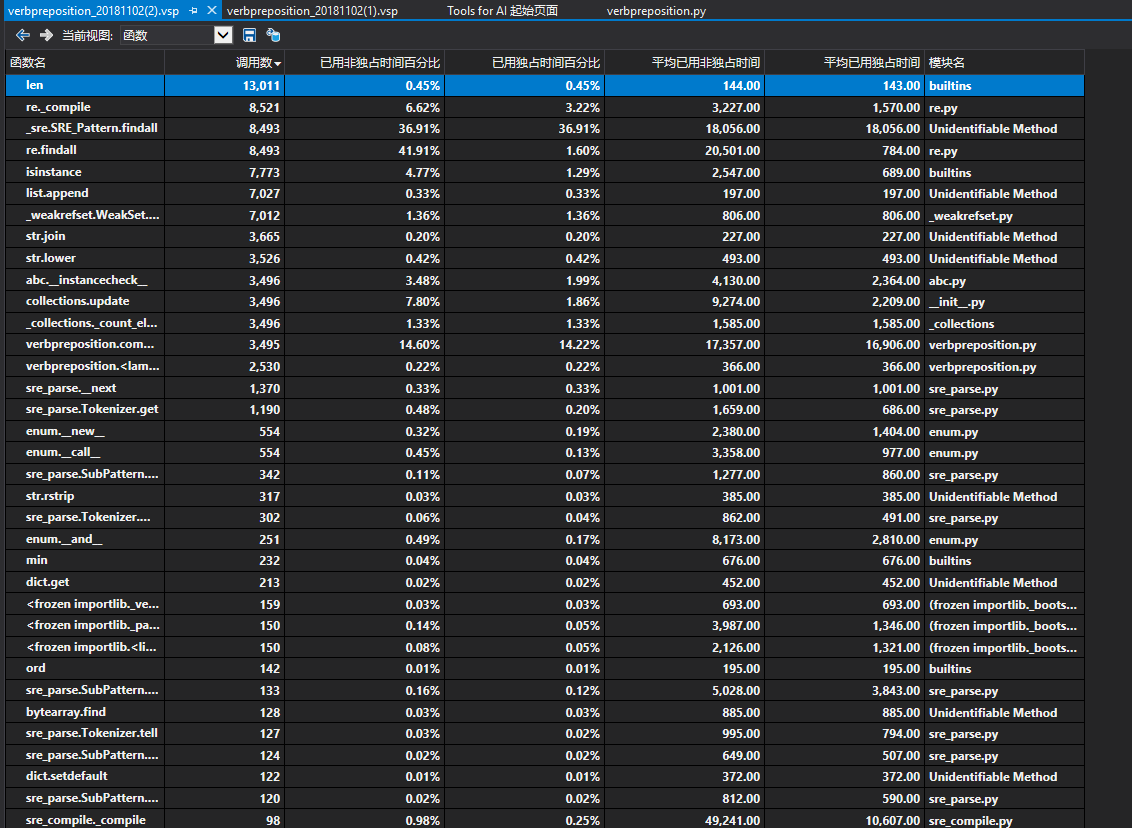
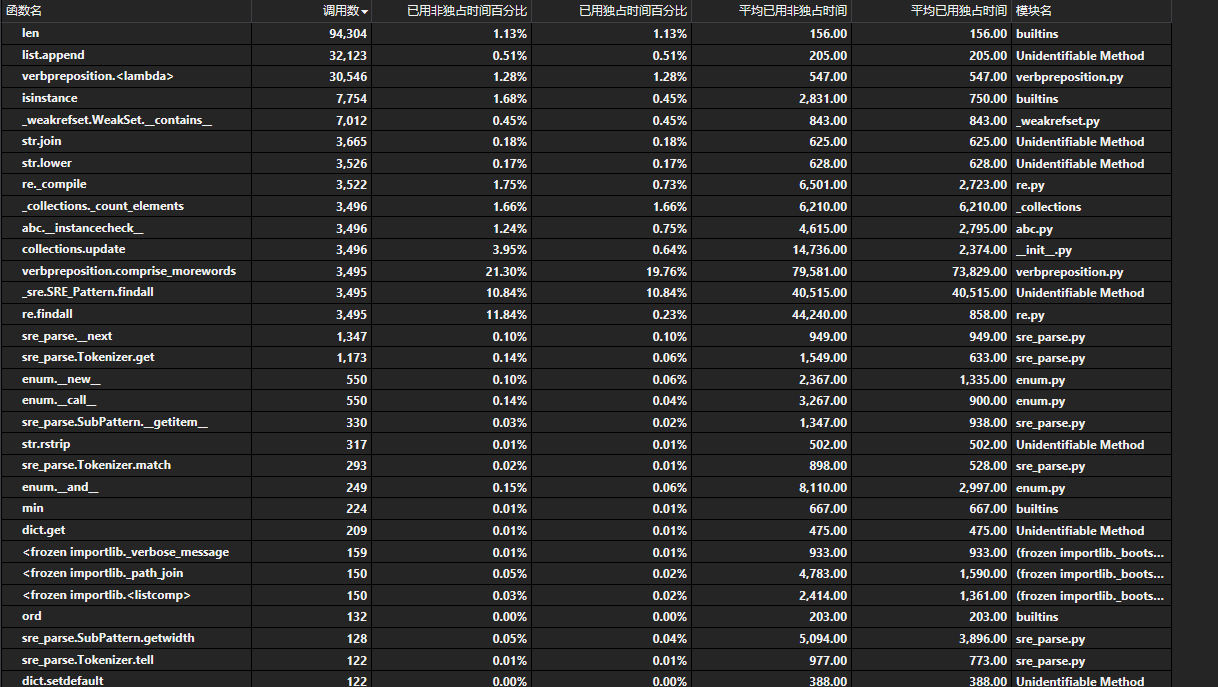
在效能分析中,我們用於分割單詞的re.findall函式呼叫的次數非常多,為了解決這個問題,我們嘗試了NTLK的函式分割包,和pynlpir這樣的函式包,和自己寫的if邏輯判斷,發現速度都沒有提升(攤手)
這個問題後來通過先分把長段分割成句子,再通過將句子分割成單詞,減少正則表達次數得到了一定的緩解,但是這個樣子的結果表現並不穩定。
所以我們的結對優化過程就是這樣一個修改,測試的迭代過程。再次分工
在最後的階段,我們採取了自行測試分析,找尋可能的方法作嘗試的方法來進行進一步的優化,比如發現字串採用format的形式進行連線操作會比使用"+"進行連線操作要更有效率。
存在一些問題
一開始的優化目標出現了問題,精力分配出錯。然後在測試過程中因為一次最多測試兩種想法,很多開出來的腦洞並沒有嘗試就被拋棄了(因為想不起來是啥)。對於一些編碼的細節把握還是有欠缺,比如字串操作的幾種方式的效率這樣的細節。
互評
隊友:
優勢:- 認真,能在編碼過程中發現很多小錯誤,比如我的單詞拼寫這樣的錯誤
- 對於腦洞的實現能力強,很快的嘗試各種方法
- 對python熟悉,可以利用python的特性省掉if判斷
缺點:
太忙